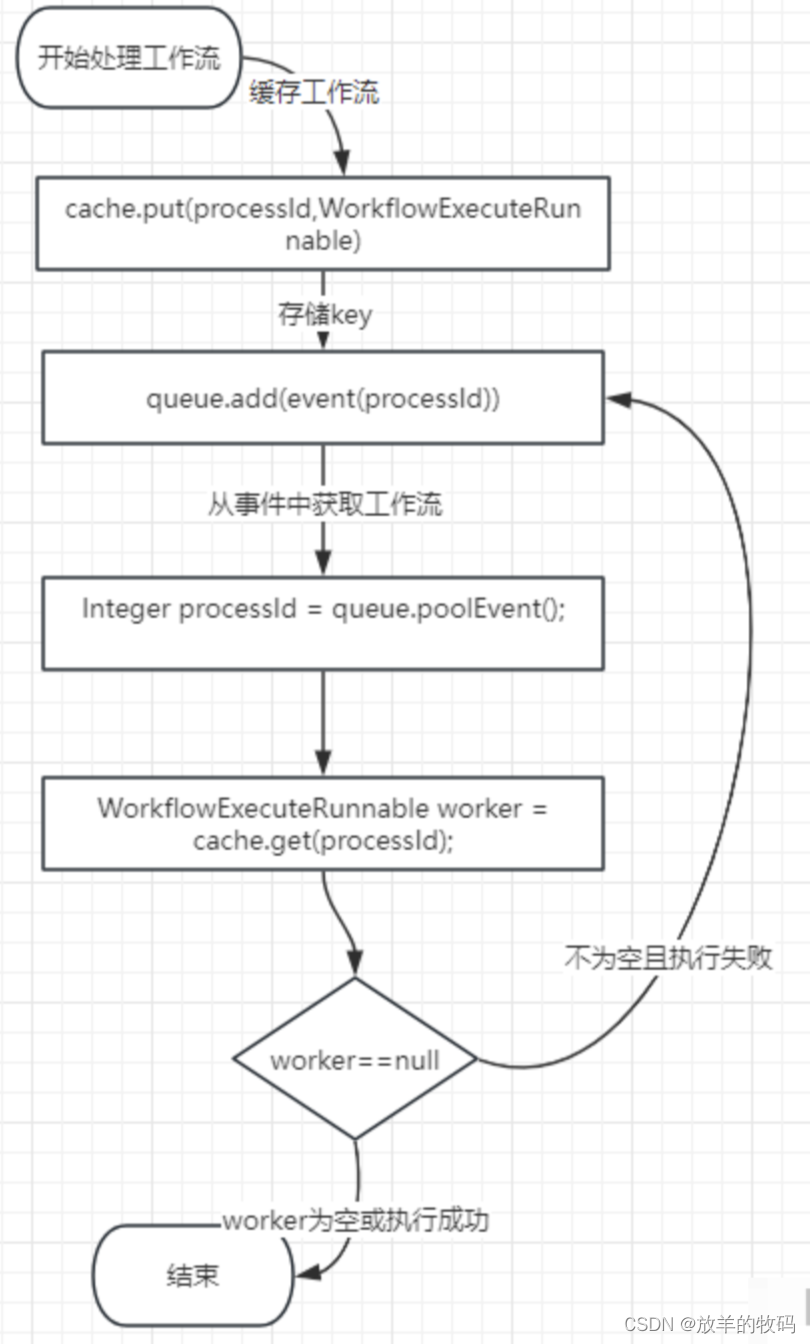
参考:https://blog.csdn.net/koulongxin123/article/details/122676149
1.什么是强化学习?
(1)定义
基于环境的反馈而行动,通过不断与环境的交互、试错,最终完成特定目的或者使得整体行动收益最大化(是一种通过与环境交互,学习最优的状态到行动的映射关系(即在某个状态下,采取所有行为的概率分布),以会的最大累计期望回报的学习方法)。强化学习不需要训练数据的label,但是它需要每一步行动环境给予的反馈,是奖励还是惩罚。反馈可以量化,基于反馈不断调整训练对象的行为。
(2)特点:
- 没有监督者,只有量化奖励信号
- 反馈延迟,只有进行到最后才知道当下的动作是好是坏
- 强化学习属于顺序决策,根据时间一步步决策行动,训练数据不符合独立同分布条件
- 每一步行动影响下一步状态,以及奖励
2.强化学习框架:智能体-环境
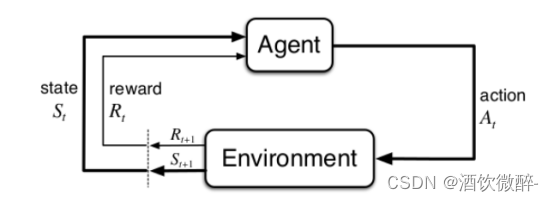
(1)智能体:强化学习系统
可以感知环境的状态(State),并根据反馈的奖励(Reward)学习选择一个合适的动作(Action),来最大化长期总收益。对于推荐系统,智能体为推荐系统本身,它包括基于深度学习的推荐模型、探索(explore )策略,以及相关的数据存储(memory )。
智能体的组成
强化学习的智能体可能有一个或多个如下的组成成分:
策略函数(policy function):把输入的状态变成行为
价值函数(value function):对当前状态进行评估(对后续收益的影响)
简直函数是未来奖励的一个预测,用来评估状态的好坏(折扣因子:希望尽可能在短的时间里面得到尽可能多的奖励)
模型(model):表现智能体对环境的理解
类型
- 基于价值的智能体(value-based agent)
显示的学习价值函数,隐式的学习策略。它维护一个价值表格或价值函数,并以此选取价值最大的动作。(常用算法:Q-Learning 、Sarsa)
A.基于策略的智能体(policy-based agent)
直接学习策略。当学习好环境以后,在每个状态都会得到一个最佳行为。(常用算法:策略梯度算法)
B.有模型智能体(model-based agent)
根据环境经验,对环境进行建模构建一个虚拟世界,同时在虚拟世界和现实世界学习。
要求:能对环境建模。即能预测下一步的状态和奖励
C.免模型智能体(model-free agent)
不对环境进行建模,直接与真实环境交互来学习最优策略。
目前,大部分深度强化学习都采用免模型学习。
(2)环境:与智能体交互的外部
环境会接收智能体执行的一系列动作,对这一系列动作进行评价并转换为一种可量化的信号反馈给智能体。
- 动作:智能体的行为表征
- 动作空间:(在给定的环境中,有效动作的集合)
分类:
(1)离散动作空间(discrete action space):智能体的动作数量是有限的
(2)连续动作空间(continuos action space):在连续空间中,动作是实值的向量
- 状态:智能体从环境获取的信息
- 奖励:
奖励信号定义了强化学习问题的目标,在每个时间步骤内,环境向强化学习发出的标量值即为奖励,它能定义智能体表现好坏,类似人类感受到快乐或是痛苦。因此我们可以体会到奖励信号是影响策略的主要因素。我们将奖励的特点总结为以下三点:
- 奖励是一个标量的反馈信号
- 它能表征在某一步智能体的表现如何
- 智能体的任务就是使得一个时段内积累的总奖励值最大
3.策略:智能体根据状态进行下一步动作的函数
- 定义
是一个函数,把输入的状态变成行为。
- 分类
随机性策略(stochastic policy)
π函数π ( a∣s ) = P ( A t = a∣S t = s ) ,表示在状态s下输出动作为a的概率。然后通过采样得到一个动作。
确定性策略(deterministic policy)
采取最有可能的动作,即a ∗= arg maxa π ( a∣s )
问题:比较随机性策略和确定性策略的优缺点
强化学习一般使用随机性策略,因为
- 随机性能更好的探索环境
- 随机性策略的动作具有多样性(不是唯一确定的)
- 确定性策略对相同环境做出相同的动作,这会导致很容易被预测
- 状态转移概率:智能体做出动作后进入下一状态的概率
3.学习与规划
A.学习(learning)
由于环境初始时是未知的,智能体需要不断与环境交互,逐渐改进策略
B.规划(planning)
获得学习好的模型后,智能体不需要实时与环境交互就能知道未来环境。可以根据当前状态,根据模型寻找最优策略。
C.解决思路
先学习环境如何工作,建立模型。再利用模型进行规划。
4.探索和利用
探索:通过试错来理解采取的某个行为能否得到好的奖励。
利用:直接采取已知的可以得到很好奖励的行为。
(探索:看某个行为的奖励,利用:选取已知可以取得最好奖励的行为)
探索和利用窘境(exploration-exploitation dilemma):探索(即估计摇臂的优劣)和利用(即选择当前最优摇臂) 这两者是矛盾的,因为尝试次数(即总投币数)有限,加强了一方则会自然削弱另一方