文章目录
- Redis HyperLogLog和Redis 7.0
- hyperloglog
- 基本使用
- 基本原理
- Redis7新特性
Redis HyperLogLog和Redis 7.0
hyperloglog
基本使用
基数:在一个数据集合中不重复元素的个数
redis hyperloglog 是用来做基数统计的算法。它可以利用少量内存进行大量数据的统计。它是有误差的,误差在0.81%。
应用场景就比如:统计网页的UV (页面访问量 一个人访问一个网站多次但还是算一个人)。
# hyperloglog它只有三个命令:pfadd、pfcount、pfmerge
# 添加元素 可以添加1个 也可以添加多个
127.0.0.1:6379> pfadd mykey a b c d e f g h i j k
(integer) 1
# 查询这个集合的基数
127.0.0.1:6379> pfcount mykey
(integer) 11
# 再创建一个集合
127.0.0.1:6379> pfadd mykey2 i j k l m n o p
(integer) 1
127.0.0.1:6379> pfcount mykey2
(integer) 8
# 还可以把两个集合合并成一个新集合
127.0.0.1:6379> pfmerge mykey3 mykey mykey2
OK
127.0.0.1:6379> pfcount mykey3
(integer) 16
基本原理
HyperLogLog基于概率论中伯努利试验并结合了极大似然估算方法,并做了分桶优化。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9bETsA5J-1680006850723)(picture/Redis/9922)]](https://img-blog.csdnimg.cn/ebd190a6646344899904761092b5e343.png)
Hyperloglog底层采用的是调和平均数,不是采用的算术平均数。
采用平均数的方式就是: (1000 + 30000) / 2 = 15500
采用调和平均数的方式就是: 2/(1/1000 + 1/30000) ≈ 1935.484
可见调和平均数比平均数的好处就是不容易受到大的数值的影响,比平均数的效果是要更好的。
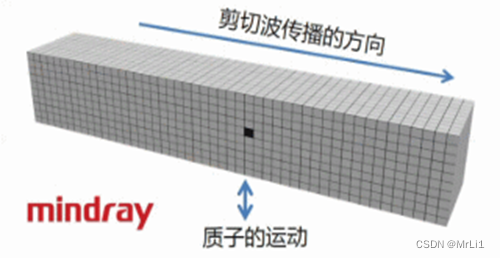
hyperloglog在redis启动时是占12KB内存大小,随着时间推移可能会有一点点的变化,redis会把这12KB的内存分为16384个桶(桶其实就是比较长的bit数组),也就是2^14次方,
hyperloglog首先会将要存的值进行hash运算转换为64位的二进制比特串,取低14位,就得到当前值应该放进哪个桶中。剩余的50位的数据就决定往桶中放入什么内容,从第14位开始往前数,找到第一个为1的比特位数,比如17位是1,那么就是从第14位开始往前数第3位是1,然后把这个3转换为二进制数存入桶中,相当于就是存了一个K。
各个桶中会求出自己的Kmax值,然后根据所有通的估计值求出调和平均数。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ugX4uwni-1680006850723)(picture/Redis/9923)]](https://img-blog.csdnimg.cn/0704e3b5887b42369ef6b3a7448a37b9.png)
Redis7新特性
提升了主从复制是性能
redis7版本以前主从复制是有两种:全量复制、增量复制。
当master节点执行一条更新命令时,它处理本机执行之外,还会往从库复制缓冲区(复制给从库)、复制积压区进行保存(将执行的命令做一个备份,slave断开连接重连时会用到)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q4BbWypW-1680006850724)(picture/Redis/image-20230328193950775.png)]](https://img-blog.csdnimg.cn/23ac5a0f1058468f958e0f83ab881988.png)
这种方式的问题是:
- 会为每一个slave节点都创建一个从库复制缓冲区,那么仅仅为了主从复制这个功能就会消耗master节点比较大的内存空间,从库越多消耗的内存也越多
- 在全量备份时会生成一个rdb文件,然后发送到从库复制缓冲区中再发送给salve1节点,如果这个时候再来一个slave节点,生成一个rdb文件是比较耗时的,Redis底层是让这些slave节点共用的同一份rdb文件,redis会把一个从库负责缓冲区中的内容拷贝到另一个从库负责缓存区,但这个容量可能几百MB或者个GB,那么就可能造成毫秒甚至是秒级单位中Redis无法响应客户端的请求,去做复制的事情去了
- 我们可以在运行时设置复制积压缓冲区的大小,这样就会造成重新分配一块新的内存空间,然后将原来的数据拷贝到新的内存块中。
redis7版本就提出来共享从库复制缓冲区的优化点。将原来一整大块内存拆分为了很多小块内存(Block),使用链表的结构将多个block连接起来,每个block中还维护了一个变量refcount用来表示从库引用计数,各个从库的复制缓冲区都是读取的一块内存,只是移动指针表示各个从库读取到了哪一个位置。这样也就不存在了多个从库复制缓冲区进行数据复制的问题了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-35HD2wMa-1680006850724)(picture/Redis/image-20230328195838348.png)]](https://img-blog.csdnimg.cn/89e2dadbc13148e7a19537483434a692.png)
因为使用了链表,假如链表上的节点非常多,如果想要获取其中一个block,那么遍历起来会非常耗时,底层用来rax树的数据结构来优化,它和Trie树的区别是进行了压缩,如下所示是一个Trie数的结构,一个字母就是一个节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fldkW2cq-1680006850724)(picture/Redis/image-20230328201933629.png)]](https://img-blog.csdnimg.cn/d552d2ea8da14f32a4a23dea706599b8.png)
而rax数如果此时某一个节点不会再分叉了,那么就把多个字母放在一个节点中,rax树其实就是压缩后的trie树。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uIxhuNOC-1680006850724)(picture/Redis/image-20230328202054482.png)]](https://img-blog.csdnimg.cn/635763af787f44dd8829a78d97acf0bb.png)
在Rax树中它其实不是按照一个字母来存放的,而是按照bit位来存放的。