作者:几冬雪来
时间:
内容:二叉树与堆内容讲解
目录
前言:
1.完全二叉树的存储:
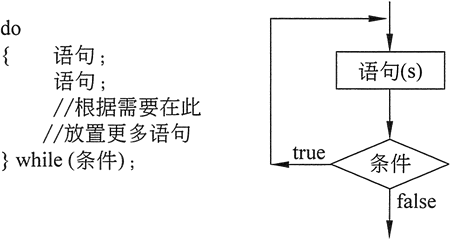
2.堆的实现:
1.创建文件:
2.定义结构体:
3.初始化结构体:
4.扩容空间与扩容后插入数据:
5.交换结点:
6.删除数据及调整:
7.返回根的值:
8.判断是否为空:
9.返回个数:
10.实践:
3.堆排序:
4.代码:
结尾:
前言:
在上一篇博客中,我们介绍了数据结构中的树以及二叉树它们的基本内容,而其中的二叉树经常被我们所日常使用到,那么今天我们就借用二叉树来实现我们数据结构中的一大重要知识点——堆。

1.完全二叉树的存储:
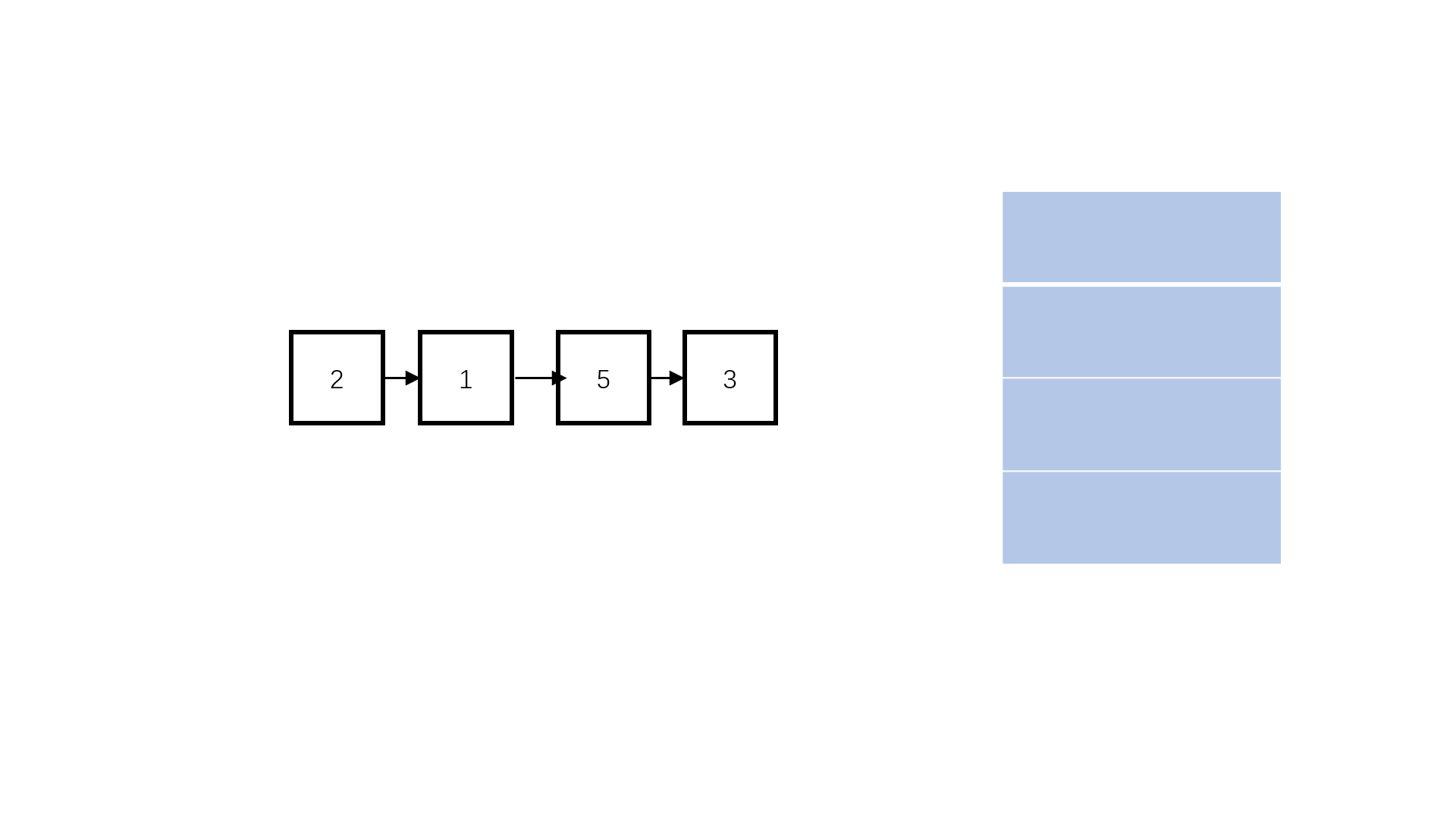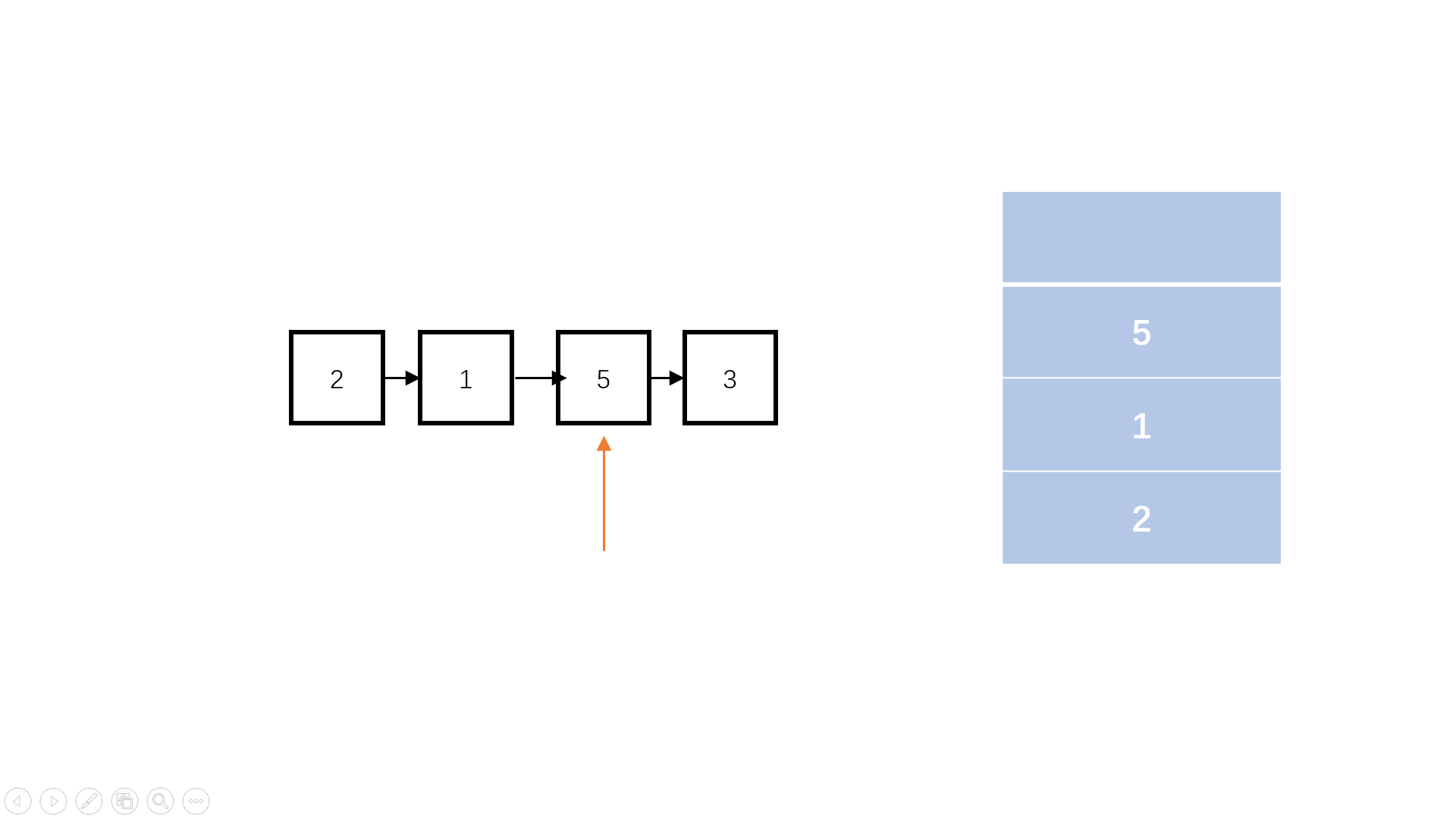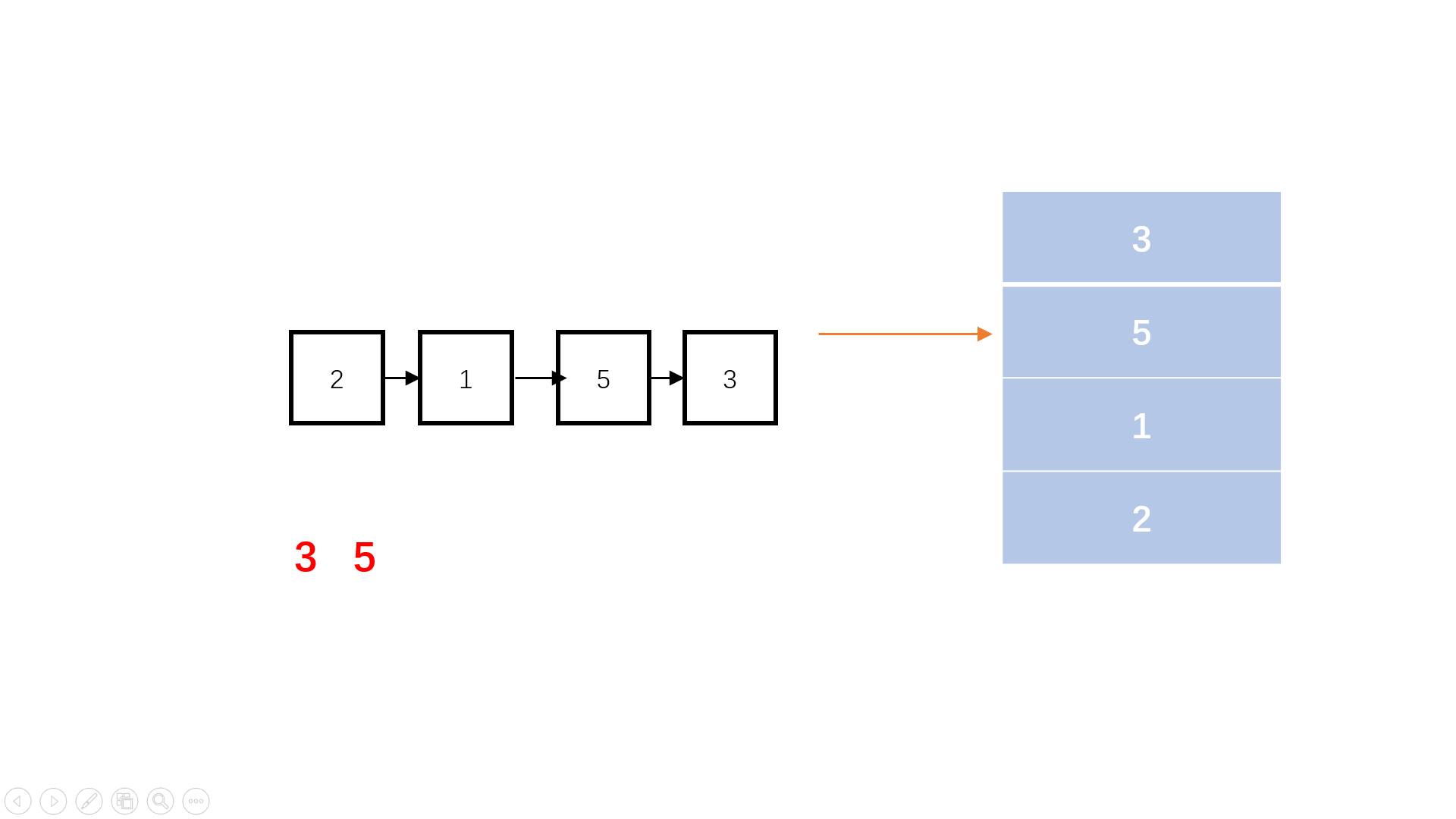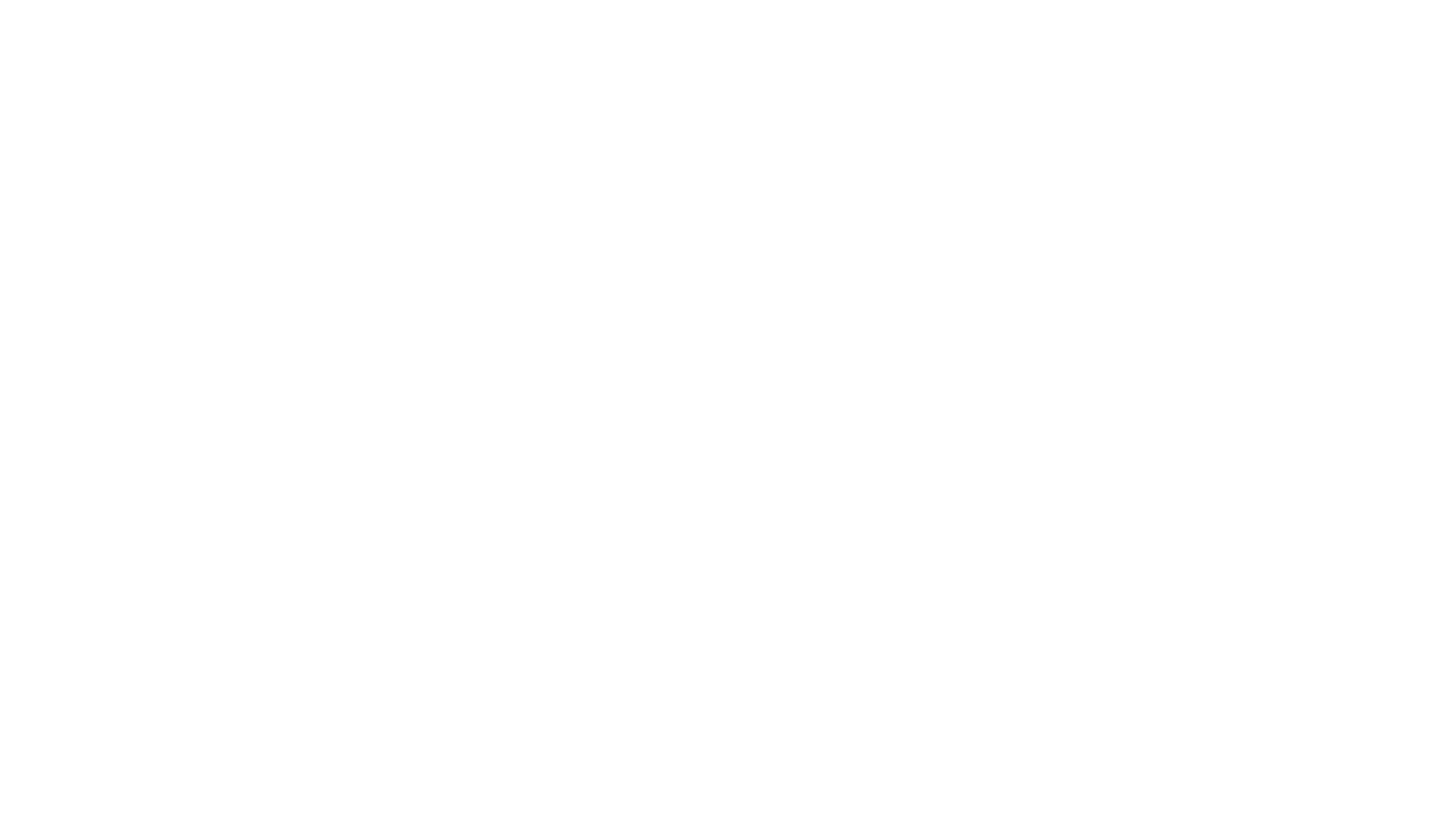
在完全二叉树的中我们一般使用顺序存储的存储方式。
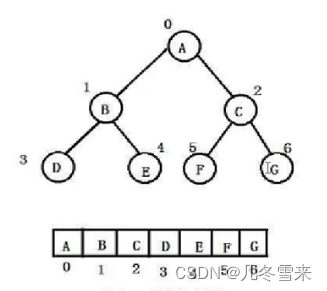
在这个图表中,上面的结构是逻辑结构,下面的结构是物理结构。而且我们平时的存储结构一般都是物理结构。这里我们也可以将它的物理结构转变为我们二叉树的形式。
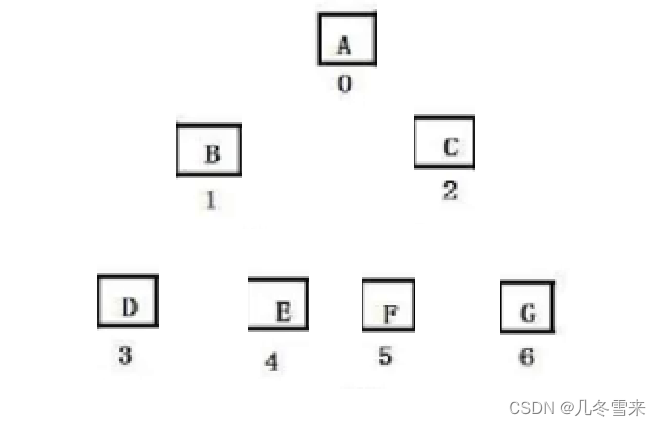
而且在树的板块中我们有提到要存储树或者二叉树,我们会用到——“左孩子右兄弟”的方法。这个方法在二叉树中也同样适用。那么在这里我们怎么确定我们的父与子的位置呢?
通过上表我们可以得出几道公式。
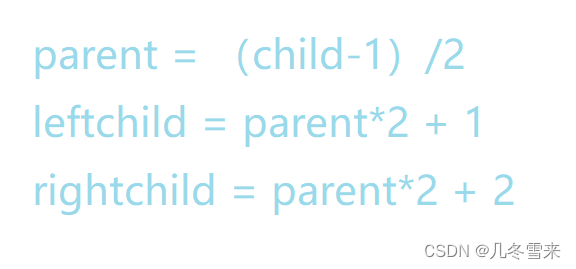
这里的公式表达的是二叉树的值在数组位置中的下标关系。而这个公式用在数组存储只适用于满二叉树和完全二叉树。如果用于非满二叉树或者完全二叉树中,这就会造成浪费空间的行为。(left/rightchild为空)
而要想要数组存储的话,我们需要对其限制条件。但是在加上限制条件之后这里就有发生了改变。
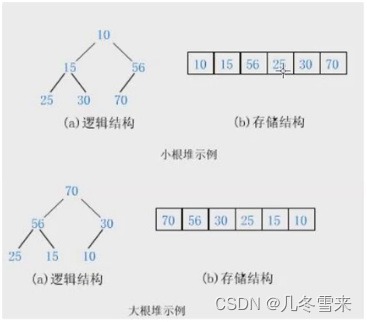
加上限制条件后,这里我们就被分成了大堆(大根堆)和小堆(小根堆)。在小根堆中,所以的父结点的值都小于或者等于子结点,如果是大根堆则反之。
而这里的这种堆的作用我们就可以用到平时的排序中去。
而在堆中,我们需要的时候会插入数据,在擦入数据的时候就还有两种情况。
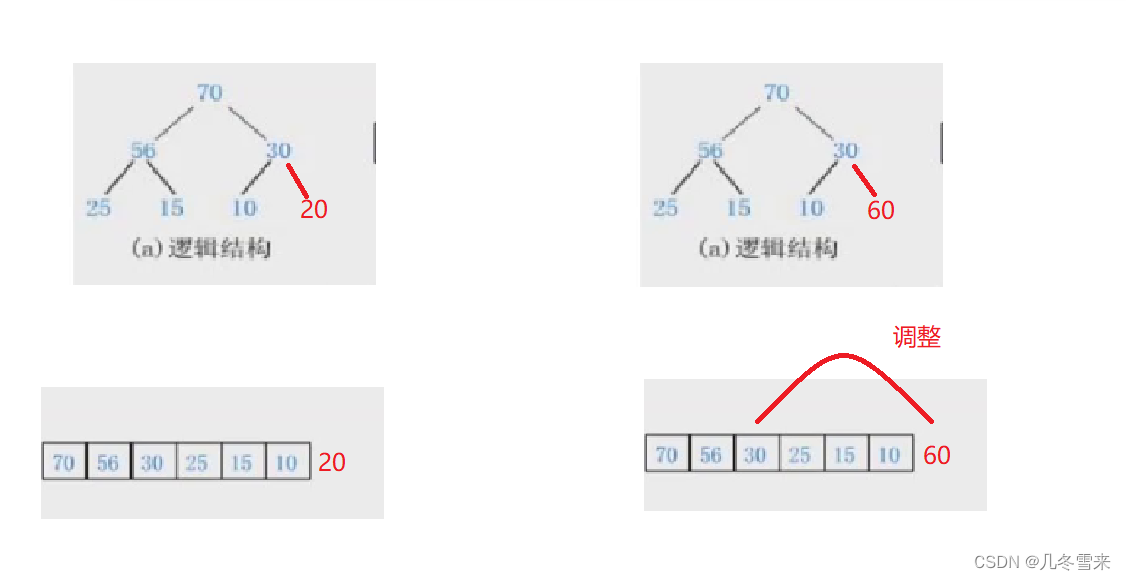
如图如果在这里我们插入的值比我们的父结点要小的话,这里直接插入即可。但是要是这里插入的数据要大于父结点,那么我们就需要对其进行调整。(向上调整最多logN次)
2.堆的实现:
那么在上面讲解了种种实现堆的代码可能遇到的问题之后,写下来我们就要正式书写我们的代码了。
1.创建文件:
想要实现我们的文件第一步就是创建文件。
同样的创建头文件和源文件。
2.定义结构体:
因为在这里我们书写的话需要定义多个数据,所以我们需要创建一个结构体来保存它们。

这里的结构体的定义类似我们数组的定义,这里就不多过讲解。
3.初始化结构体:
要想使用结构体,我们就要先将其初始化。
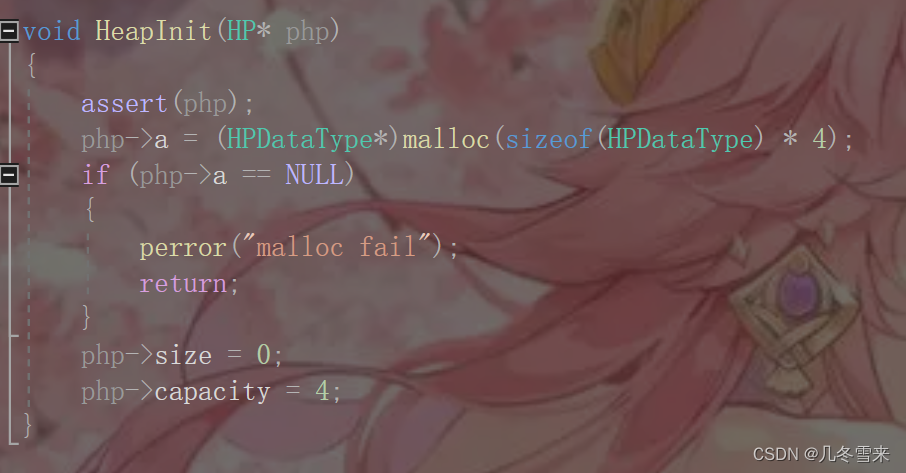
开幕断言,接下来就是为我们的结构体中的a申请空间,同时也要在这里判断申请失败的情况。而后因为a中没有数据,我们初始化为0,现阶段最大的个数为4个,所以capacity初始化为4。
4.扩容空间与扩容后插入数据:
因为我们要不断的插入空间,空间不够的话就只能进行扩容操作。
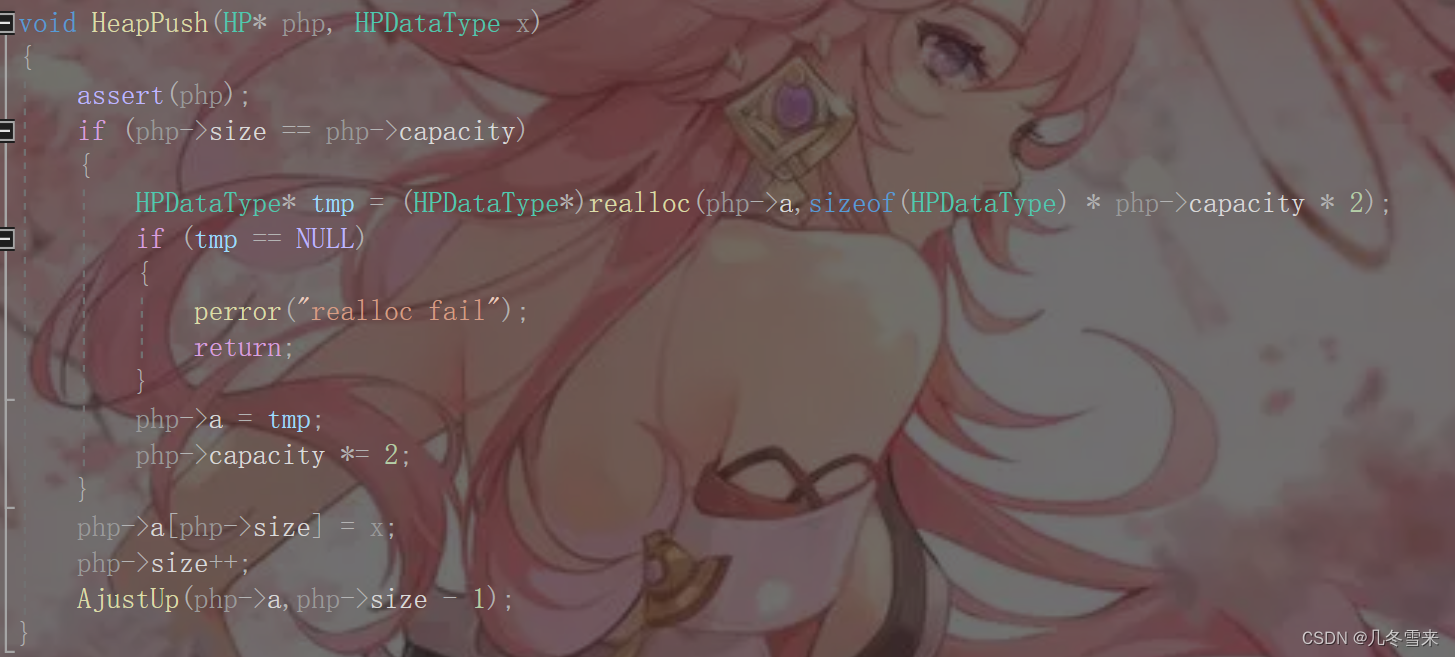
这里插入空间还是老样子,开始判断如果size与capacity相等,说明内存已经满了。接下来就是我们的扩容操作和判断是否扩容成功。扩容成功我们将新创立的指针交给a保护,capacity乘等于2。
成功扩容之后,我们就在下标size的地方插入我们的值,然后size往下走,这里最后一行代码是交换。
5.交换结点:
如果子结点大于我们的父结点,这里就需要对数据进行调整。
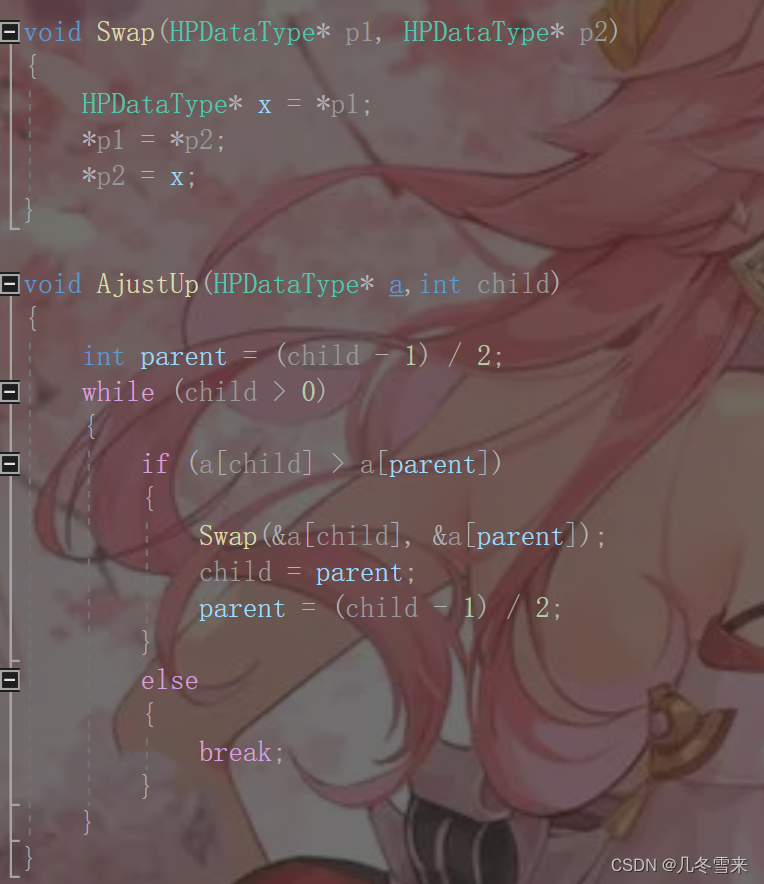
这里我们就来交换数据,这里通过child来找到我们它父结点的下标值。因为我们的子结点不可能为0,所以这里我们拿来作为循环条件。如果子结点大于父结点,我们就创建一个函数将二者交换,然后再将parent变为子结点,child继续找下一个父结点,直到根结点或者中间哪个父结点大于子结点就停下后进行break。
6.删除数据及调整:
有插入数据的操作,那必然也会有删除数据的操作,但是在二叉树中我们不能随意的删除数据。
删除根结点的数据我们应该怎么做?这里我们不能使用挪动数据的方法来解决这个问题。因为我们这里一开始就是一个堆,在删除数据之后一个保持它还是一个堆。
如果挪动数据之后,它就已经不是堆了。挪动数据删除会导致我们的效率低下,父结点与子结点的关系乱套。
那我们这里有一个怎么去进行删除呢?在这里我们运用到了一种方法:让我们的根结点和最后一片叶子互换位置,这样并不会破坏堆的结构,然后将最后一片叶子删除,最后来调整我们的堆。

这里向下调整的话,我们需要拿父结点和更大一点的子结点进行比较。这样才能保证新的父结点大于我们两个子结点。(向下调整最多调整logN次)
那这里我们的代码要怎么去写它呢?
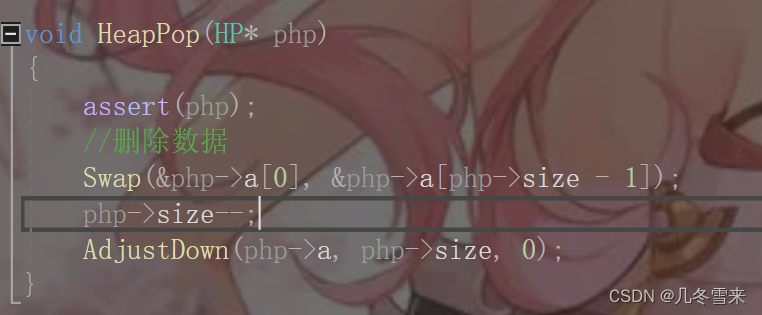
在这里,还是先断言。接下来用我们的函数来交换最后一片叶子和根结点的值,然后size--将我们最后一片叶子删除。接下来就是我们调整数据使它再变成一个堆。
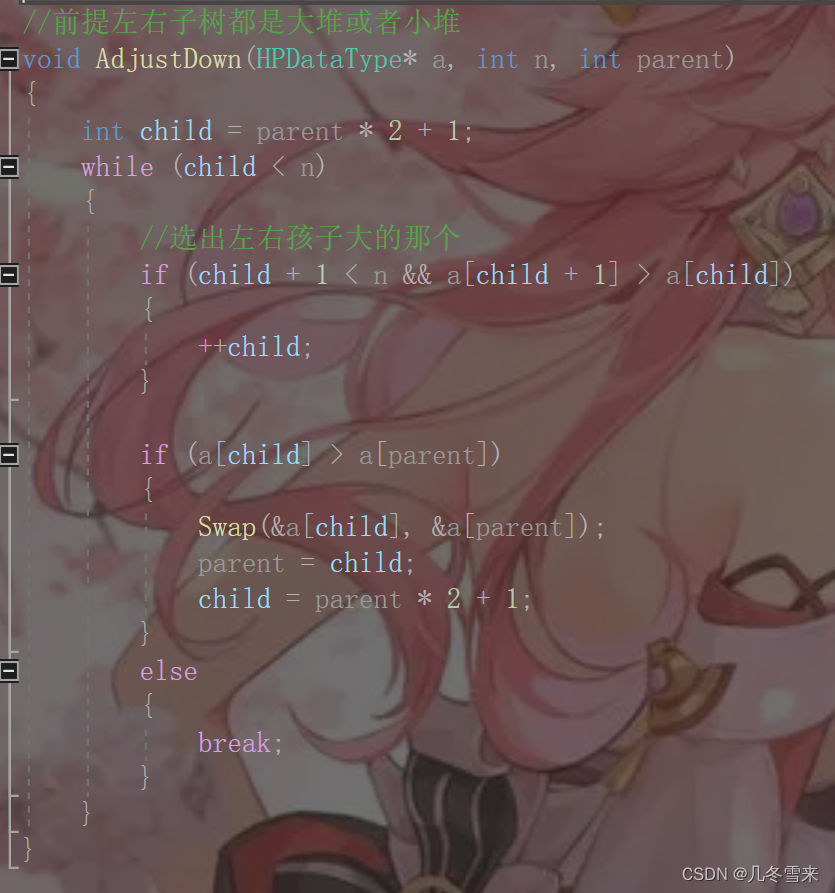
这里我们可以先通过父结点来找到我们的左边的子结点。接下来就是循环,当child小于我们的个数n的时候,进入循环。因为一个根有两个子结点,因此我们也要判断两个子结点之间的大小,一开始我们就设定左结点大于右结点,如果根的左结点+1不为小于n(有右结点)且右结点大于左结点,我们就将child++,让它从指向左结点变为指向右结点。如果较大的子结点大于父结点,我们就将两个值交换,然后新的子结点设计为我们的新的根,继续求它的左结点。要是父结点大于子结点,我们就直接跳出循环。
7.返回根的值:
那么在这个代码中如果我们要返回根结点的值要怎么做?

这里断言后直接返回就行了。
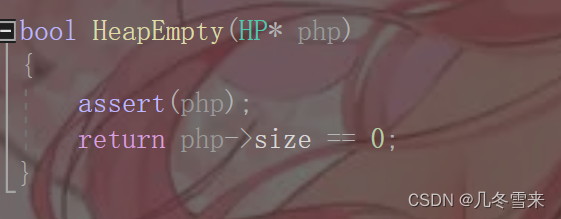
8.判断是否为空:
在删除数据的时候,如果个数为0的话,接下来我们就不用再进行删除操作了。那么这里要怎么判断呢?
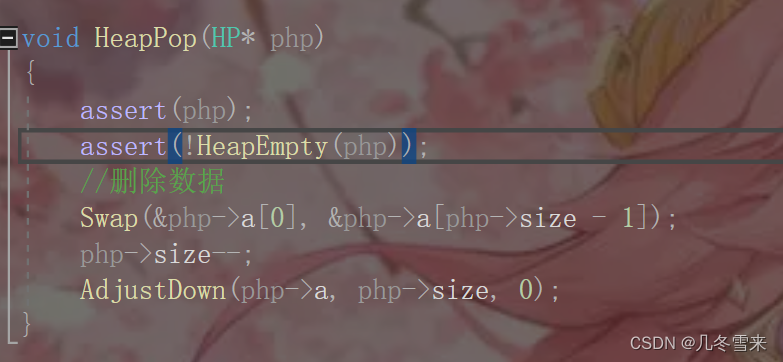
同时我们删除数据的代码也可以进一步完善。
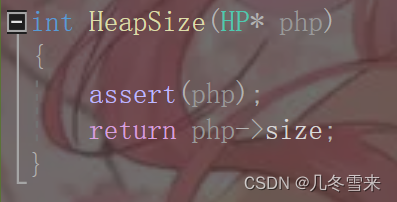
9.返回个数:
在这里返回个数的操作和我们返回根结点的操作一样。
这里就直接写出来了。
10.实践:
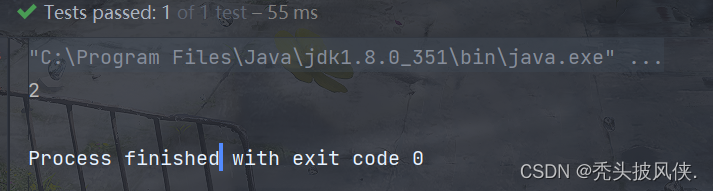
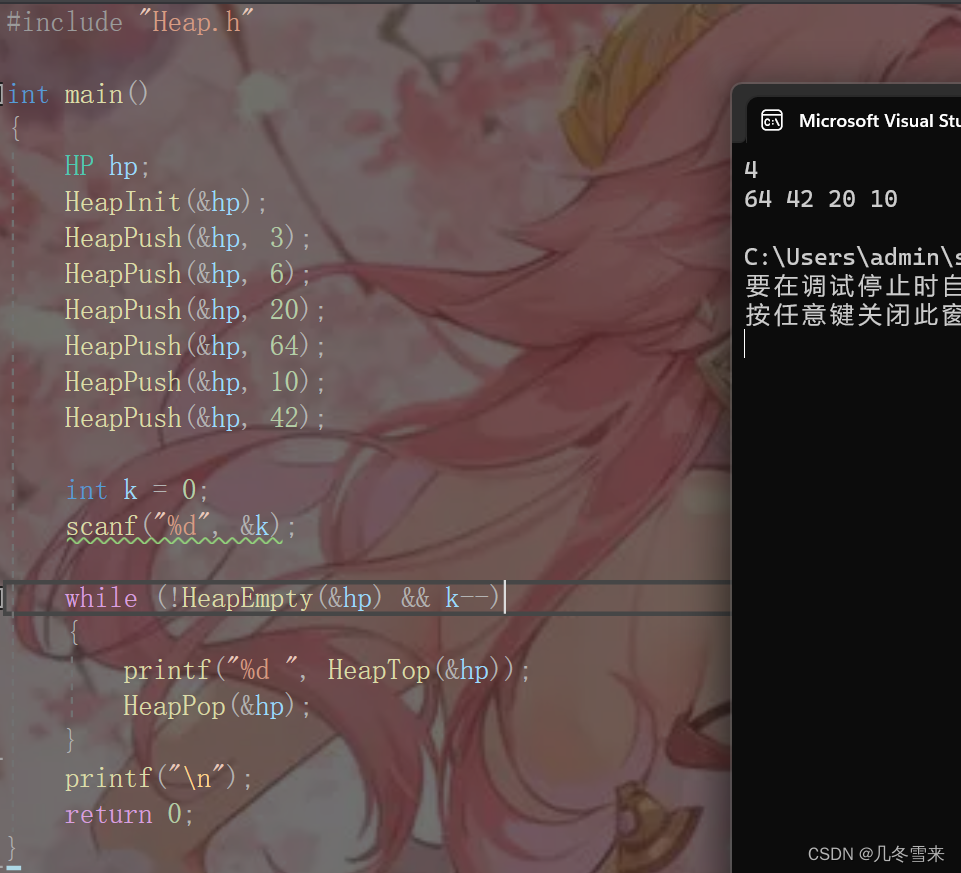
到这里我们的代码操作都写完了,下来我们就来实践操作一下看看结果是什么?
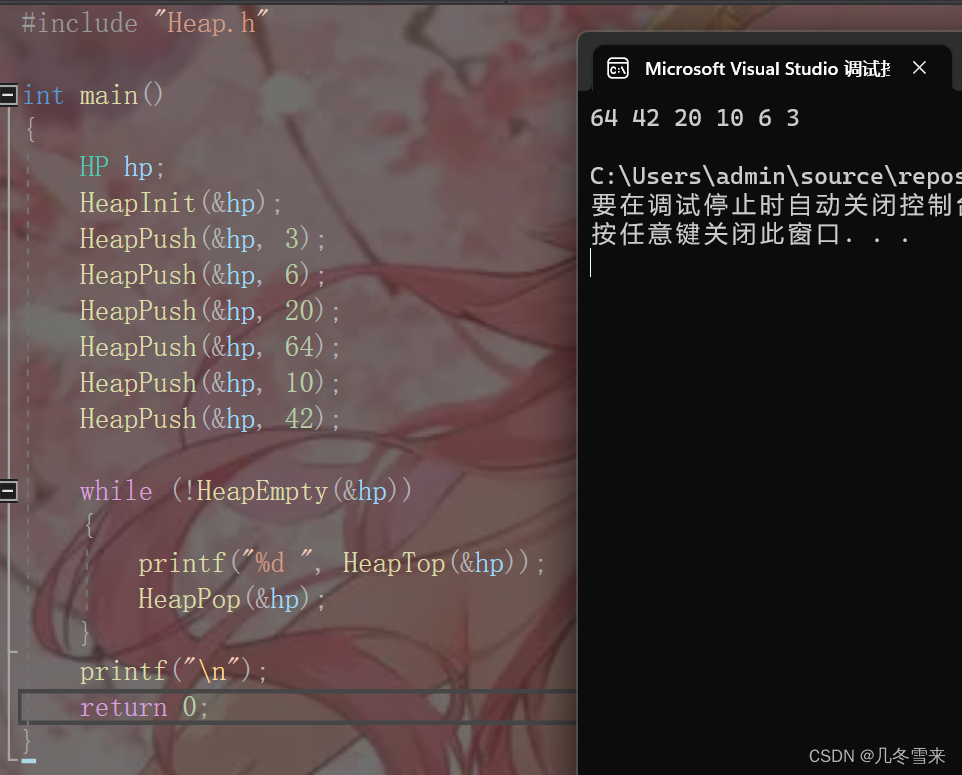
从结果来看,它十分符合我们的预想。我们也可以对代码进行修改让它只打印我们前几个想要的数据。
3.堆排序:
接下来我们就来讲解一下堆的排序,这里有人就要问了:上面我们的这种代码不是堆排序吗?它不是堆排序,这只是一种类似堆排序的数组排序罢了。
假设我们这里给一个数组,我们要将它进行堆排序的话要怎么做?最简单粗暴的方法就是直接再写一个堆出来,但是它是下下策。因此这里我们要建堆,直接建堆一个出来。
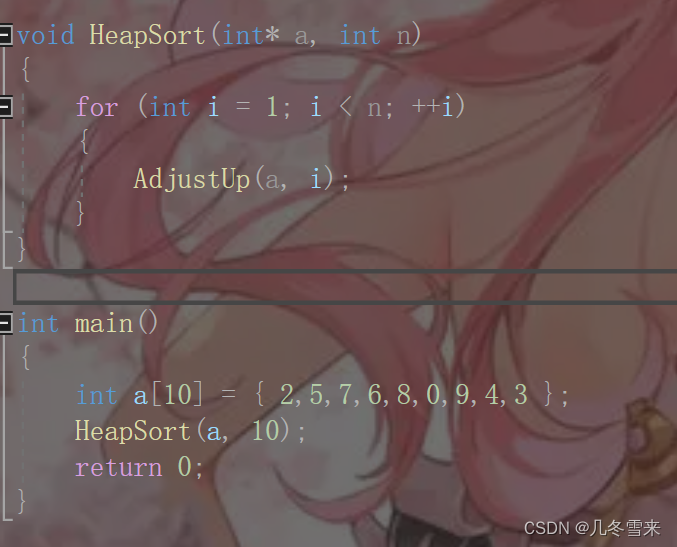
这里我们直接建堆的话,要在已经有向上和向下调整代码的前提下。
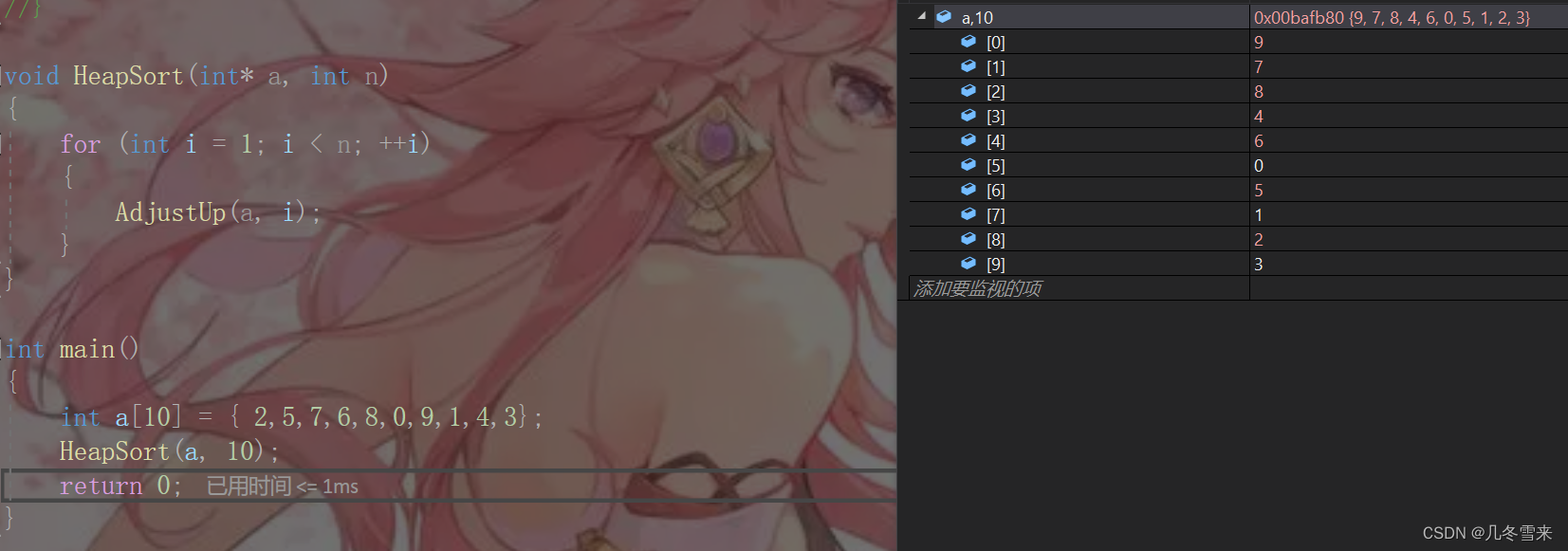
我们来对它进行调试,第一眼看着没有什么顺序可言,但是只要我们将图画出来就可以简单明了的看出来。 
这里我们就成功的进行了堆排序的建堆操作。
在树的板块我们有讲到,我们的排序分为大堆结构和小堆结构,如果在此我们要进行排升序操作,在这里我们是建大堆还是建小堆。上面这种方法是建大堆,那么如果要建小堆的话,代码要怎么修改?

在这里就只用将大于号换为小于号即可。换完之后我们来打印看看小堆是怎么样的一个情况。

这里可以看出我们的小堆排序成功实现了。但是实际上在我们写代码的时候,在进行排升序操作时,建小堆会出现一些问题。 如果我们采取建小堆,当我们选完了最小的数之后,接下来要选出次小的数,这里会出现什么问题?

当我们小堆选完了最小的数之后,我们将它移出后要选次小的数。但是在选次小的数之前,我们一个保存剩余的代码函数一个堆,虽然这里还是一个堆,但是它的关系已经乱掉了。在原堆中,我们的1和2是兄弟关系,当原根移出之后我们需要一个新的根,这里就将2个移动上去,但是这里就会变成1和2原本的兄弟关系变成了父子关系。
如果要解决这个问题的话,我们只能重新开始建一个堆,而大堆就没有这个烦恼。
因此在这里我们也得出一个结论:
在堆这里如果我们想排升序建大堆,排降序建小堆。
4.代码:
还是老规矩我们将我们的代码写出来。(包含堆的实现和堆排序的试验)
Heap.h文件
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#include <assert.h>
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;
void HeapInit(HP* php);
void HeapPush(HP* php, HPDataType x);
void HeapPop(HP* php);
HPDataType HeapTop(HP* php);
bool HeapEmpty(HP* php);
int HeapSize(HP* php);
void AdjustUp(HPDataType* a, int child);Heap.c文件
#include "Heap.h"
void HeapInit(HP* php)
{
assert(php);
php->a = (HPDataType*)malloc(sizeof(HPDataType) * 4);
if (php->a == NULL)
{
perror("malloc fail");
return;
}
php->size = 0;
php->capacity = 4;
}
void Swap(HPDataType* p1, HPDataType* p2)
{
HPDataType* x = *p1;
*p1 = *p2;
*p2 = x;
}
void AdjustUp(HPDataType* a,int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void HeapPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)
{
HPDataType* tmp = (HPDataType*)realloc(php->a,sizeof(HPDataType) * php->capacity * 2);
if (tmp == NULL)
{
perror("realloc fail");
return;
}
php->a = tmp;
php->capacity *= 2;
}
php->a[php->size] = x;
php->size++;
AdjustUp(php->a,php->size - 1);
}
//前提左右子树都是大堆或者小堆
void AdjustDown(HPDataType* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
//选出左右孩子大的那个
if (child + 1 < n && a[child + 1] > a[child])
{
++child;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapPop(HP* php)
{
assert(php);
assert(!HeapEmpty(php));
//删除数据
Swap(&php->a[0], &php->a[php->size - 1]);
php->size--;
AdjustDown(php->a, php->size, 0);
}
HPDataType HeapTop(HP* php)
{
assert(php);
return php->a[0];
}
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
int HeapSize(HP* php)
{
assert(php);
return php->size;
}
test.c文件
#include "Heap.h"
//int main()
//{
// HP hp;
// HeapInit(&hp);
// HeapPush(&hp, 3);
// HeapPush(&hp, 6);
// HeapPush(&hp, 20);
// HeapPush(&hp, 64);
// HeapPush(&hp, 10);
// HeapPush(&hp, 42);
//
// int k = 0;
// scanf("%d", &k);
//
// while (!HeapEmpty(&hp) && k--)
// {
// printf("%d ", HeapTop(&hp));
// HeapPop(&hp);
// }
// printf("\n");
// return 0;
//}
void HeapSort(int* a, int n)
{
for (int i = 1; i < n; ++i)
{
AdjustUp(a, i);
}
}
int main()
{
int a[10] = { 2,5,7,6,8,0,9,1,4,3};
HeapSort(a, 10);
return 0;
}结尾:
在这里我们讲解的堆的实现操作还有一部分的堆排序的知识,但是堆排序真正复杂的地方并不在这里,再往后我们还要学习并且计算它的时间复杂度等,这才是复杂的地方。最后希望这篇博客可以为大家带来帮助。

![[ 网络 ] 应用层协议 —— HTTP协议](https://img-blog.csdnimg.cn/5d2b0f854b0242948993be92f45a337f.png)