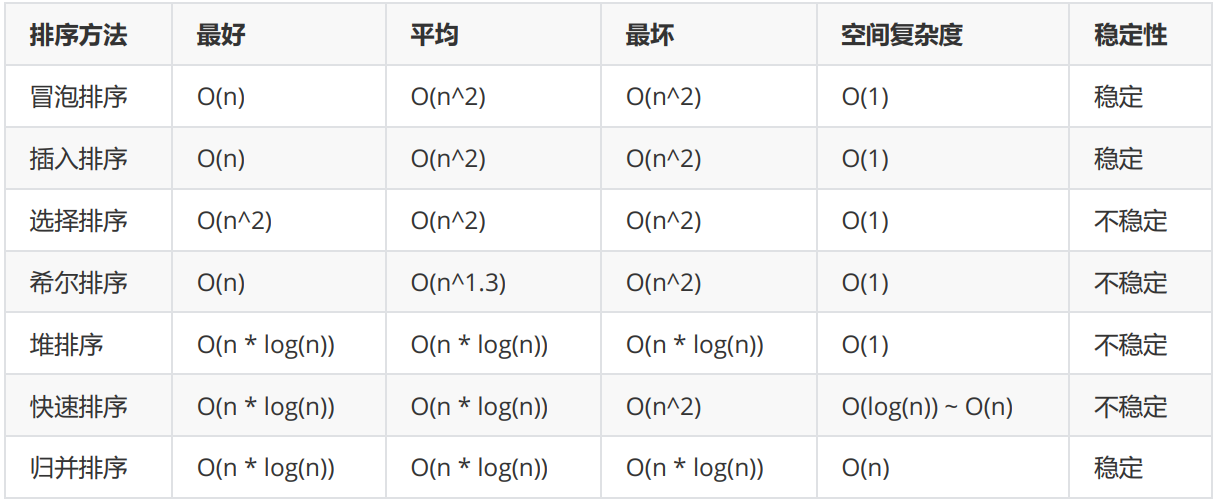
chatGPT的横空出世给人工智能注入一针强心剂,它是历史上以最短时间达到一亿用户的应用。chatGPT的能力相当惊人,它可以用相当流利的语言和人对话,同时能够对用户提出的问题给出相当顺畅的答案。它的出现已经给各个行业带来不小冲击,据说有很多公司已经使用chatGPT来替代人工,于是引起了不少裁员事件。
chatGPT是人类科技史上一个里程碑。它基于一种叫大语言模型的技术,使得计算机具备了相当于人乃至超越人的能力,chatGPT的发明者openAI据说在推进下一代模型的开发,据说已经能达到通用AI的程度,我对此表示怀疑。无论如何基于大模型技术的AI将人类带入一个新时期,我们必须有所准备,我们既不需要过分狂热,以为它又是一个暴富风口;也不能漠不关心,认为它完全与自己无关,如果你从事信息技术行业,你必须要特意留一手,如果它真的是进入新纪元的钥匙,那么我们不会被落下,如果只是一阵骚动,那么基于技多不压身的原则,咱花点心思多学一门技术也不亏。
我们这个系列着重于探究发明出chatGPT的技术,我们基于可用的算力和数据从零开始做一个“类”chatGPT,也就是我们做出来的模型不可能有chatGPT那么厉害,但是我们掌握和使用的原理跟它一样,只不过我们没有对应的资源训练它而已。同时chatGPT底层还有一种技术叫transformer,基于这个技术我们可以把chatGPT的开源模型拿过来,然后使用小样本数据就能将其训练成某个特定领域的AI专家,于是chatGPT就能为我所用。
这个系列分为两部分,首先是介绍NLP(自然语言处理)的基本原理和技术,然后我们看看如何使用开源的大语言模型进行特定的开发,由此打造出属于我们自己的chatGPT.首先需要声明的是,涉及到人工智能和深度学习,它具有一定的门槛,那就是你至少要比较熟练大学阶段的高数,你要了解微积分相关内容,熟悉向量,矩阵等线性代数概念,要不然很难在这个领域发展。
现在我们回到技术层面。人工智能要解决的主要是传统算法处理不了的问题,传统算法之所以对一些问题束手无措,主要是因为要处理的对象无法使用结构化的数据结构进行表达。例如给定一张人脸图片,我们如何使用传统数据结构来描述呢,是使用链表,二叉树,哈希表吗,显然不行。由于这个原因,传统算法处理不了这些范畴的问题。那么人工智能怎么用数据区描述例如人脸,单词都这些对象呢,方法是用向量,面对的对象性质越复杂,向量的长度就越大,例如人脸通常用长度为256或者更大的实数向量来表示。对NLP而言,它处理的对象是文本,因此它会使用向量来表示文本的基本单位,如果文本是英语,那么就用向量来表示单词,如果是中文,那么就用向量表示一个字。
我们看一个具体例子,假设我们有一段英语文本:
Times flies like an arrow
Fruit flies like a banana.
显然传统数据结构是无法表达上面的句子和单词,因此我们转向向量来表达。首先我们把所有单词转换为小写,然后将其排列起来,单词排列的先后顺序没有关系,于是有:
time fruit flies like a an arrow banana
接下来我们使用一种叫one-hot-vector的向量来表示单词,可以看到上面有8个不同的单词,因此向量包含8个元素,由于time排在第一个,于是我们把向量第一个元素设置为1,其他元素设置为0,因此time的向量表示就是[1,0,0,0,0,0,0], 同理fruit排在第2位,因此它对应的向量就是第二个元素为1,其他元素为0,于是其对应向量为[0,1,0,0,0,0,0,0],其他以此类推。这种对单词的向量描述方式在我们后面的深度学习算法中会发挥很大作用。对于一个句子而言,它的向量描述方式就是把单词对应的向量进行“或”操作,例如句子like a banana,组成它三个单词的向量是[0,0,0,1,0,0,0,0], [0,0,0,0,1,0,0,0],[0,0,0,0,0,0,0,1], 进行“或”操作后结果就是[0,0,0,1,1,0,0,1],我们用代码来实践看看:
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns
corpus = ['Time flies flies like an arraw.', 'Friut flies like a banana']
one_hot_vectorizer = CountVectorizer(binary = True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
vocab = one_hot_vectorizer.get_feature_names_out()
sns.heatmap(one_hot, annot=True, cbar = False, xticklabels = vocab, yticklabels=['Sentence 1','Sentence 2'])
上面代码运行后结果如下:
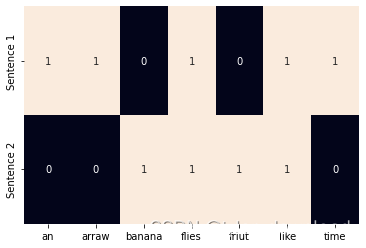
从上图我们能看到图形化的,两个句子对应的向量表示,如果给的单词在句子中出现了,他们向量对应位置设置为1,要不然就设置为0.one-hot-vector只是对单词或句子最基本的数学描述方式,事实上在不同的文本或应用场景下,单词或句子的向量绝对不会那么简单,他们依然需要以向量来表示,但是向量的长度和每个元素的取值都得靠深度学习算法来分析出来,具体情况在后面章节详细阐明。
下面我们看看深度学习的基本原理。有过微积分基础的同学会了解,对于一个连续函数f(x),如果在某一点求导所得结果为0:f’(x)=0,那么这个点就可能是在局部范围内的最大值或最小值。深度学习本质上就是通过微分求极小值的过程,只不过它对应的函数包含不止一个变量,例如chatGPT对应的模型就是一个包含1750亿个参数的函数,训练的目的就是找出这1750亿参数的合适取值,这样它才能根据输入的句子给出合适的回复,因此用于它训练的算力和数据无疑是及其巨大的,以下我们给出深度学习网络训练的基本流程:
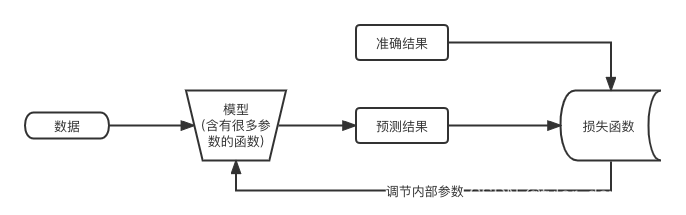
对深度学习基本原理不熟悉的同学可以参考《神经网络与深度学习实战》,或者我在云课堂上的课程:http://m.study.163.com/provider/7600199/index.htm?share=2&shareId=7600199
下面我们看运算图的概念。在上图中“模型”其实可以使用传统数据结构中的“图论”来表示。“含有很多个参数的函数”其实可以使用链表来表示,当算法对函数的参数进行求导时,这些运算就可以通过链表来完成,我们看一个具体例子,对于函数y = wx+b,我们可以用链表表示如下:
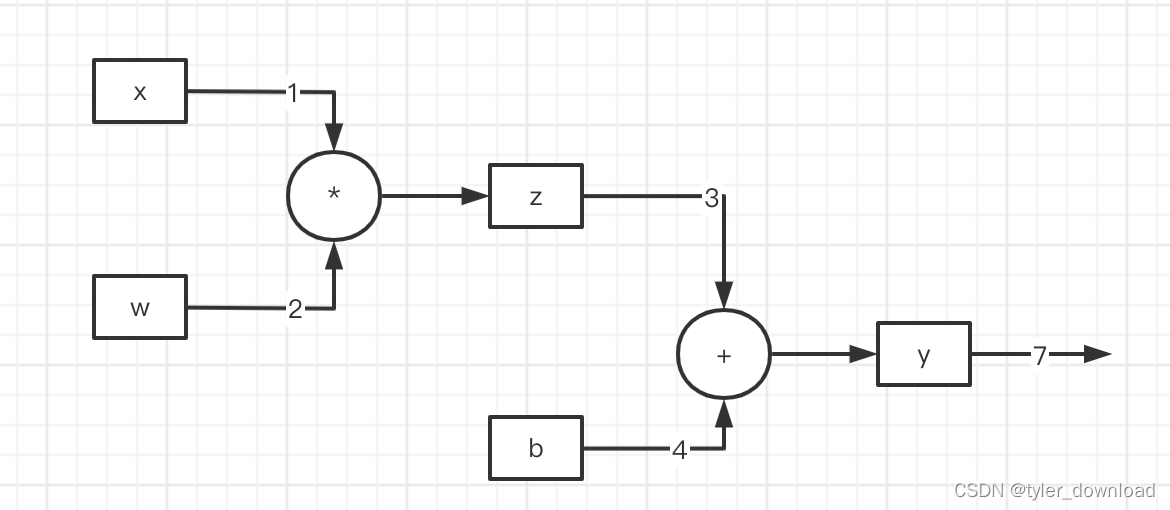
参数x, w, b, y使用矩形节点表示,运算符则使用圆形节点表示。箭头上的值表示对应参数的值,他们经过圆形节点后执行对应运算然后输出结果。前面我们提到过chatGPT的参数有1370亿个,那意味着其对应的运算图将非常庞大和复杂,因此我们通常使用特定框架来完成运算图的构建以及执行基于其的运算,常用的框架有tensorflow, pytorch还有百度的飞桨,目前用的比较多的还是meta的pytorch框架。
在具体的深度学习应用中,参数节点往往不会像上面那么简单,他们通常是高维度向量,我们上面显示的是0维度的向量,也就是他们是单个参数,在实际应用中x,b通常是一维向量,w是二维向量也就是矩阵。如果我们要处理的输入是图片,那么x可能就是二维向量,如果处理的是视频,那么可能就是三维向量,因为视频是具有时间维度的图片,对于NLP而言,也就是自然语言处理而言,输入的x通常是一维或者二维向量.接下来我们看看如何在基于pytorch框架的基础上实现向量的各自运算。
我们所有代码将运行在谷歌的colab开发环境,这个环境好在于集成了pytorch框架,同时还能让我们免费使用gpu加快运算效率。首先我们用一段代码展示如何使用pytorch创建各种维度的向量:
import torch
def describeTensor(tensor):
#输出向量的维度,类型,以及元素值
print(f"Type: {tensor.type()}")
print(f"shape/size: {tensor.shape}")
print(f"values: {tensor}")
describeTensor(torch.Tensor(2,3)) #创建二维向量,也就是2*3矩阵
上面代码执行后输出如下:
Type: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[-7.9076e-20, 4.5766e-41, -7.7950e-20],
[ 4.5766e-41, -7.7948e-20, 4.5766e-41]])
这里需要注意的是,向量中每个元素的值是随意初始化的,一般情况下向量初始值是什么不重要。在深度学习中,我们往往需要对输入数据进行正规化处理,也就是把向量元素进行加工,使得他们加总的值为1,我们看个例子:
#对向量进行正规化处理,也就是向量元素加起来等于1
describeTensor(torch.randn(2,3))
上面代码运行后结果如下:
ype: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[ 0.5474, 0.7511, 0.7454],
[ 0.7795, -1.8067, 0.4035]])
不难看到,上面输出的每个向量,它对应元素加起来值正好等于1.0.在某些情况下,我们创建向量后,希望初始化向量中每个分量的值,因此我们可以如下操作:
#把向量每个元素初始化为0
describeTensor(torch.zeros(2,3))
#把每个元素初始化为1
x = torch.ones(2,3)
#把每个元素设置为5,下划线表示函数对应的操作会直接作用在给定的向量上
x.fill_(5)
describeTensor(x)
上面代码执行后结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[0., 0., 0.],
[0., 0., 0.]])
Type: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[5., 5., 5.],
[5., 5., 5.]])
在python的数值应用中,numpy是必不可少的函数库,因此我们能把numpy对应的列表直接转换成向量,例如下面的方式
import numpy as np
npy = np.random.rand(2,3)
#直接从numpy向量转换为pytorch向量
describeTensor(torch.from_numpy(npy))
上面代码运行后输出结果如下:
Type: torch.DoubleTensor
shape/size: torch.Size([2, 3])
values: tensor([[0.2552, 0.2467, 0.9570],
[0.3357, 0.8942, 0.2779]], dtype=torch.float64)
注意看,这里向量的类型变成了double而不是float。另外我们还可以将运算作用在向量上,例如把向量的行相加得到一个一维向量,例如下面代码:
x = torch.Tensor([[1, 2, 3], [4, 5, 6]])
#将向量按照行相加,
y = torch.sum(x, dim = 0)
describeTensor(y)
#将向量按照列相加,这个稍微有点抽象,它的做法是想取出一行,然后将所有元素加总,然后取出第二行,将所有元素加总
#第一行的元素为[1,2,3]加总后就是1+2+3 = 6, 第二行是【4,5,6】加总后就是4+5+6=15,结果就是一个包含两个元素的1维向量[6,15]
z = torch.sum(x, dim = 1)
describeTensor(z)
上面代码运行后结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([3])
values: tensor([5., 7., 9.])
Type: torch.FloatTensor
shape/size: torch.Size([2])
values: tensor([ 6., 15.])
针对向量的运算,比较令人混乱的是对向量进行转换,这些操作统称为indexing, slicing, 和joining,我们看几个具体例子:
x = torch.Tensor([[0, 1, 2], [3,4,5]])
'''
:1是针对行进行选取,:1表示选取所有下标不超过1的行,由于向量只有两行,因此只有第0行满足条件,于是:1的作用是把第0行选取出来。
:2是针对列进行选取,它表示选取下标不超过2的列,由于前面我们已经选取了第0行,因此:2表示在第0行基础上选出下标不超过2的列,于是
操作结果就是[0,1]
'''
describeTensor(x[:1, :2])
上面代码运行后结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([1, 2])
values: tensor([[0., 1.]])
我们再看看如何针对高维向量,选取它指定的列:
indices = torch.LongTensor([0, 2])
'''
dim = 1 ,表示操作将针对列进行,(行对应的dim为0),index指定将给定下标的列选取出来
由于indices对应的值为0,2,因此下面操作就是将第0列和第2列选取出来,于是结果就是[[0,2],[3,5]]
由于indices对应的数值必须是整形,因此我们设置向量的类型为long,也就是每个分量的类型是int64
'''
describeTensor(torch.index_select(x, dim = 1, index = indices))
上面代码运行后结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([2, 2])
values: tensor([[0., 2.],
[3., 5.]])
我们再看一个更令人困惑的操作:
indices = torch.LongTensor([0, 0])
'''
本次操作作用于向量的行,也就是dim = 0,我们要把下标为indices的行选取出来,由于
indices对应的参数为两个0,因此下面操作把第0行选取两次,于是形成结构就是[[0,1,2],[0,1,2]]
'''
describeTensor(torch.index_select(x, dim = 0, index = indices))
上面操作运行后结果如下;
Type: torch.FloatTensor
shape/size: torch.Size([2, 3])
values: tensor([[0., 1., 2.],
[0., 1., 2.]])
我们还能同时选取向量的行和列,例如:
x = torch.Tensor([[0, 1, 2], [3,4,5]])
#用于设置下标的向量必须是整形,而向量默认是浮点型,因此如果向量用于存储下标,那么需要明确生成long型的向量
row_indecies = torch.LongTensor([0,1])
col_indecies = torch.LongTensor([0, 1])
'''
先选取第0,1两行,然后选取第0行的第0列,接着选取第1行的第1列,所得结果就是[0,4]
'''
describeTensor(x[row_indecies, col_indecies])
上面代码运行后所得结果为:
Type: torch.FloatTensor
shape/size: torch.Size([2])
values: tensor([0., 4.])
不同向量之间还能进行组合,合并等操作,这些操作也很容易让人头疼和困惑,我们看几个例子:
x = torch.Tensor([[1,2,3], [4,5,6]])
y = torch.Tensor([[7,8,9], [10, 11, 12]])
'''
将x,y在行的维度上叠加,这个操作要求两个向量要有相同数量的列
'''
z = torch.cat([x, y], dim = 0)
describeTensor(z)
上面代码运行后所得结果如下:
Type: torch.FloatTensor
shape/size: torch.Size([4, 3])
values: tensor([[ 1., 2., 3.],
[ 4., 5., 6.],
[ 7., 8., 9.],
[10., 11., 12.]])
同样我们可以将两个向量的列进行叠加:
x = torch.Tensor([[1,2,3], [4,5,6]])
y = torch.Tensor([[7,8,9], [10, 11, 12]])
'''
将两个向量在列的维度进行叠加,也就是把两个向量的第一行合成一行[1,2,3]+[7,8,9]->[1,2,3,7,8,9],
然后把两个向量的第二行合成一行[4,5,6]+[10,11,12]->[4,5,6,10,11,12],
老实说我对这个操作也感觉困惑
'''
z = torch.cat([x, y], dim = 1)
describeTensor(z)
上面代码运行结果为:
Type: torch.FloatTensor
shape/size: torch.Size([2, 6])
values: tensor([[ 1., 2., 3., 7., 8., 9.],
[ 4., 5., 6., 10., 11., 12.]])
我们还能将多个向量作为新向量的分量,例如:
x = torch.Tensor([[1,2,3], [4,5,6]])
y = torch.Tensor([[7,8,9], [10, 11, 12]])
'''
把两个向量叠起来,也就是把两个向量分别作为新向量的分量,由于现在向量维度是2行3列,
因此把这两个向量作为新向量的分量时,新向量就会有2个分量,同时每个分量的维度就是2行3列,
于是新向量的维度就是[2, 2, 3]
'''
z = torch.stack([x,y])
describeTensor(z)
上面操作结果为:
Type: torch.FloatTensor
shape/size: torch.Size([2, 2, 3])
values: tensor([[[ 1., 2., 3.],
[ 4., 5., 6.]],
[[ 7., 8., 9.],
[10., 11., 12.]]])
我们还能对向量进行运算,例如让某一行或某一列乘以一个值,例如:
#初始化三行两列的矩阵,并让每个分量取值1
x = torch.ones(3,2)
'''
x[:, 1]表示选取向量所有行,同时选取行中下标为1的元素,让这些元素加上数值1
'''
x[:, 1] += 1
describeTensor(x)
上面代码运行后结果为:
Type: torch.FloatTensor
shape/size: torch.Size([3, 2])
values: tensor([[1., 2.],
[1., 2.],
[1., 2.]])
对应高维向量,我们还能把他们当做矩阵来相乘
x = torch.Tensor([[1,2], [3,4]])
y = torch.Tensor([[5,6], [7,8]])
#将两个向量执行矩阵乘法,第一个元素是第一个向量的第一行乘以第二个向量的第一列,也就是[1,2] X [5,7] = 1*5 + 2*7 = 19,以此类推
z = torch.mm(x, y)
describeTensor(z)
上面代码执行后所得结果我:
Type: torch.FloatTensor
shape/size: torch.Size([2, 2])
values: tensor([[19., 22.],
[43., 50.]])
下一节我们看看自然语言处理的深度学习算法中,我们需要涉及的一些概念和流程,更多信息请在b站搜索coding迪斯尼。

![[数据结构]直接插入排序、希尔排序](https://img-blog.csdnimg.cn/1b043aa97c4743969433ea4cd0b5f6fe.png)