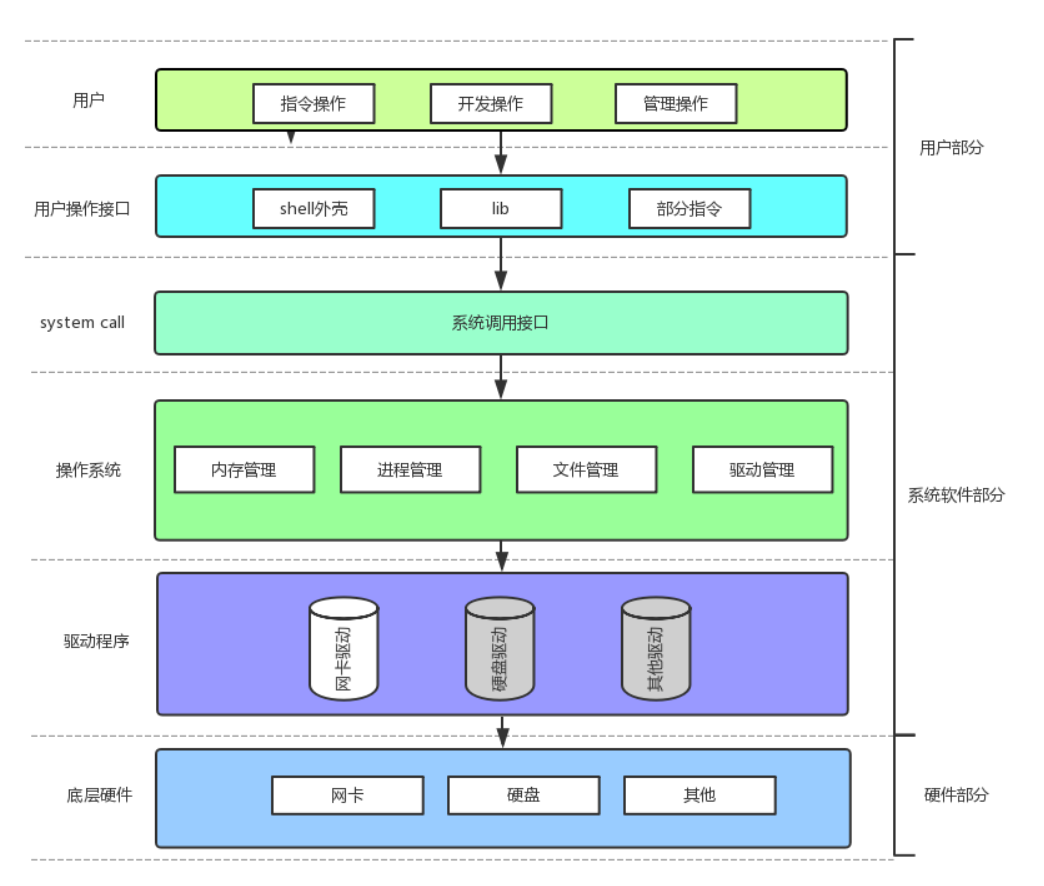
1.强化学习(Reinforcement Learning, RL)
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。

A.强化学习分类(基于价值、基于策略)
- 基于价值(Value-Based )的强化学习:智能体通过学习价值函数,隐式的策略,如Ɛ-greedy。Value-Based 算法的缺点:1)对连续动作的处理能力不足;2)对受限状态下的问题处理能力不足;3)无法解决随机策略问题。包括Q-Learning、SARSA、Deep-Q-network算法。
- 基于策略(Policy-Based )的强化学习:没有价值函数,直接学习策略。基于策略(Policy-Based )适用于随机策略、连续动作。包括Policy Gradient算法、TRPO、PPO。
- 演员-评论家强化学习:学习价值函数(评论家),同时也学习策略(演员)。包括Actor-Critic算法、DDPG。
B.动态规划、蒙特卡罗、时间差分法、暴力搜索

动态规划(dynamic programming methods):是假设智能体已经知道关于该环境的所有信息。动态规划所要解决的问题就是智能体知道了环境的所有信息后,如何利用这些信息找出最优策略。
蒙特卡罗方法(Monte Carlo methods) :蒙特卡罗法的基本思想是:为了求解问题,首先建立一个概率模型或随机过程,使它的参数或数字特征等于问题的解:然后通过对模型或过程的观察或抽样试验来计算这些参数或数字特征,最后给出所求解的近似值。解的精确度用估计值的标准误差来表示。
时间差分法(temporal difference):结合了动态规划DP和蒙特卡洛MC方法。如on-policy的Sarsa方法和off-policy的Q-Learning方法.
暴力搜索ES。
C.强化学习分类(基于环境)
根据是否具有环境模型,强化学习算法分为两种:
基于模型的强化学习(model-based):动态规划
无模型的强化学习(model-free):蒙特卡罗、时间差分法
D.强化学习分类(on/off-policy)
On-policy:学习的 agent 跟和环境互动的 agent 是同一个。行为策略与目标策略相同。其好处就是简单粗暴,直接利用数据就可以优化其策略,但这样的处理会导致策略其实是在学习一个局部最优,因为On-policy的策略没办法很好的同时保持即探索又利用。
Off-policy: 学习的 agent 跟和环境互动的 agent 不是同一个。将收集数据当做一个单独的任务。Off-policy将目标策略和行为策略分开,可以在保持探索的同时,更能求到全局最优值。但其难点在于:如何在一个策略下产生的数据来优化另外一个策略。
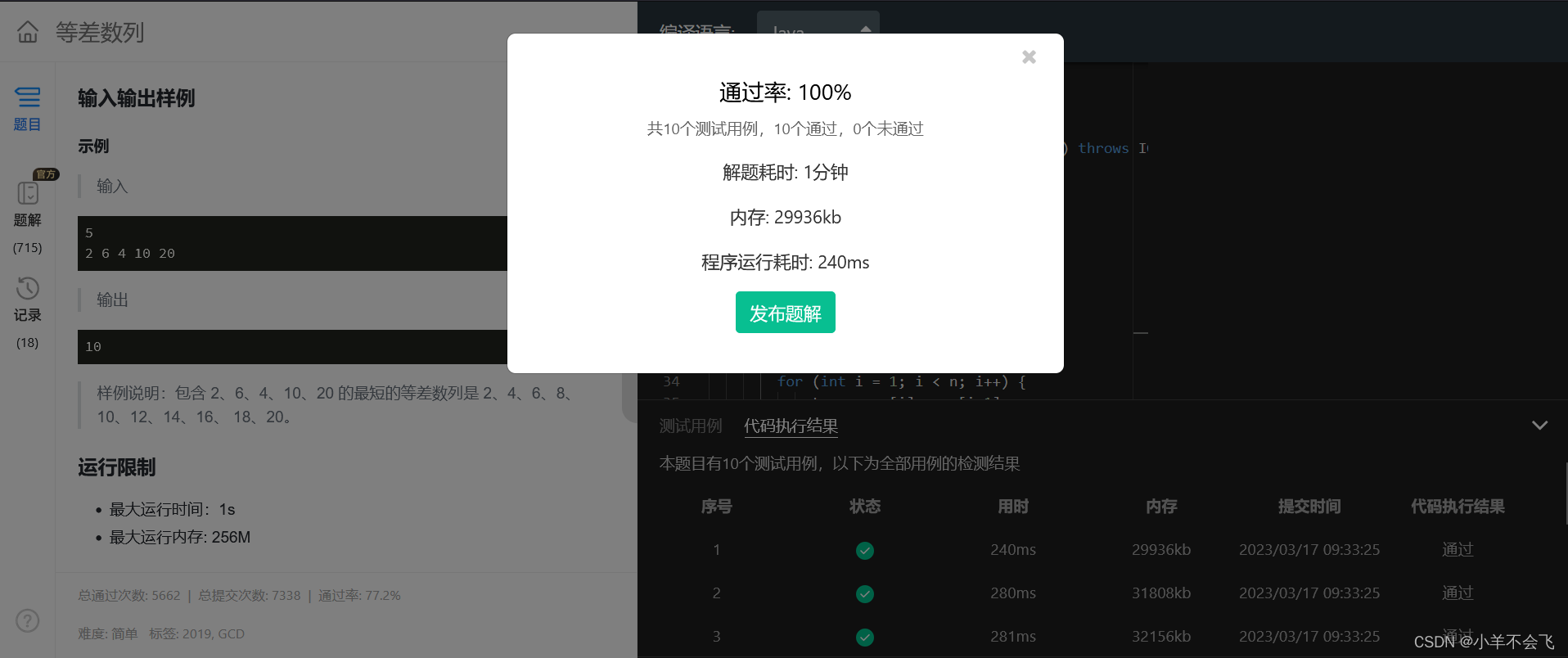
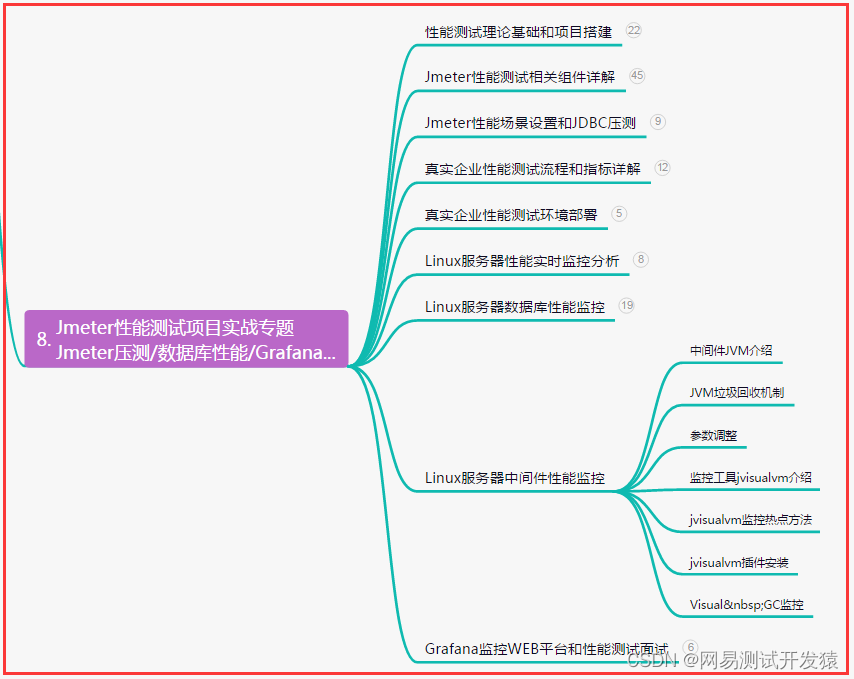
2 Q-Learning

Q-Table/状态-价值函数Q(s,a):这个表格的每一行代表每个 state,每一列代表每个 action,表格的数值就是在各个 state 下采取各个 action 时能够获得的最大的未来期望奖励。
例如在一个游戏中有下面5种状态和4种行为,则表格为:

通过 Q table 就可以找到每个状态下的最优行为,进而通过找到所有最优的action得到最大的期望奖励。
Q表更新公式:
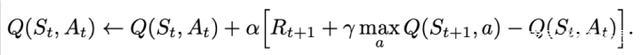
Q-learning在更新Q值时下一步动作是不确定的,它会选取Q值最大的动作来作为下一步的更新。
3 SARSA
SARSA(State-Action-Reward-State-Action)是一个学习马尔可夫决策过程策略的算法。
1994年,G.A. Rummery 和 M.Niranjan 在 Modified Connectionist Q-learning 论文中的脚注提及了SARSA。
1996年,R.S. Sutton 正式提出了SARSA的概念。
它的算法和公式和 Q learning 很像,但是 Q-Learning 是Off-Policy的,SARSA 是On-Policy 的。
Q-Learning 和SARSA主要是Q表更新公式不一样。
Q表更新公式:
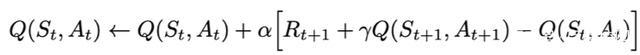
Sarsa使用下一步的实际动作来作为更新,而Q-learning选取下一步Q值最大的动作作为更新。
4 Dyna-Q
Dyna算法框架并不是一个具体的强化学习算法,而是一类算法框架的总称。Dyna将基于模型的强化学习和不基于模型的强化学习集合起来,既从模型中学习,也从和环境交互的经历去学习,从而更新价值函数和(或)策略函数。

对于模型部分,我们可以用查表法和监督学习法等方法,预测或者采样得到模拟的经历。而对于非模型部分,使用前面的Q-Learning系列的价值函数近似,或者基于Actor-Critic的策略函数的近似都是可以的。
算法如下:
在每次与环境交互进行一次Q-learning后,Dyna-Q执行n次Q-planning(下面的第f步)。Q-planning中生成模拟数据。

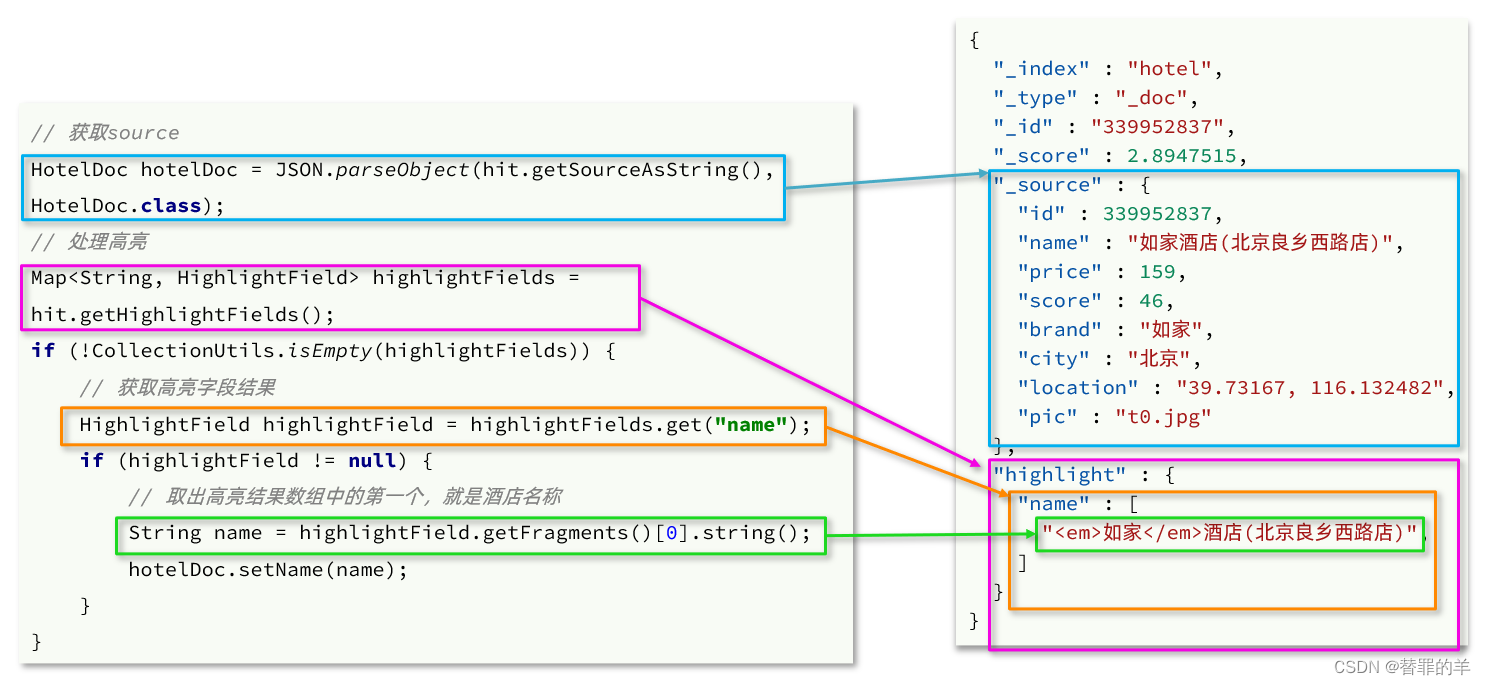
5 DQN(deep Q-network)
DQN 是基于价值(value-based)而非策略(policy-based)的方法。基于深度学习的Q-Learing算法。
Q-Learing算法维护一个Q-table,使用表格存储每个状态s下采取动作a获得的奖励,即状态-价值函数Q(s,a),这种算法存在很大的局限性。在现实中很多情况下,强化学习任务所面临的状态空间是连续的,存在无穷多个状态,这种情况就不能再使用表格的方式存储价值函数。
为了解决这个问题,我们可以用一个函数Q(s,a;w)来近似动作-价值Q(s,a),称为价值函数近似Value Function Approximation,我们用神经网络来生成这个函数Q(s,a;w),称为Q网络(Deep Q-network),w是神经网络训练的参数。


6 Policy Gradient
基于策略(Policy-Based )方法其实比基于价值(value-based)的方法更直接,如下图,直接通过神经网络预测智能体在state下采取什么动作(action)。训练的过程也就是学习神经网络参数θ,即直接学习策略。

策略π可以被被描述为一个包含参数θ的函数:

上述公式是指,假设智能体处于状态s,时间t,带参数 θ 的环境中,在时间t采取动作a的概率。
Policy Gradient 类的算法是经过梯度计算去更新策略网络的参数,其中目标函数就直接设计成指望累积奖励。
如下图,智能体(actor)在s1下产生动作a1,接着环境变成s2, actor又在s2下产生动作a2,等等。
其中每次动作的奖励的r。玩一次游戏记为(s1、a1、s2、a2....),这次游戏的奖励为R(),为各个动作奖励的累积。我们选取目标函数为多次游戏的平均奖励,即。

有了目标函数J,就可以更新模型参数θ,大体算法如下:
1.目标函数J描述如下,并转换成log的形式:

2.对目标函数转换后的log进一步拆分。

3.实际训练不能准确知道期望E,所以用平均值来估计,如下面的1/N。

Policy Gradient的梯度可以写成下面更一般的形式:


A是advantage方法,V 反映的是在当前策略下做出动作的平均累计折扣回报的期望,可以理解为平均水平。
进而可以转换成对下面目标函数求微分。
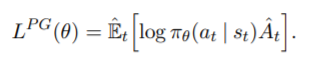
a. reinforce算法
上面讲的policy gradient的方法其实就是reinforce算法。
REINFORCE算法仅使用一个网络,我们可以称之为策略网络。我们使用智能体网络与环境进行一个回合的交互,同时收集所有的轨迹信息,最后使用一个回合所有的交互信息更新策略网络。
整体算法重新描述如下,下面引入了奖励折扣率:

b.加入基准值(baseline)的策略梯度法
加入基准值(baseline)就是指减掉平均期望V,如下面第2个式子。
V 反映的是在当前策略下做出动作的平均累计折扣回报的期望,可以理解为平均水平。
7 TRPO(Trust Region Policy Optimization)
Trust Region Policy Optimization即置信域策略优化。使用Trust Region算法来进行Policy 优化的算法。
TRPO算法和Policy Gradient(reinforce)算法的目标函数一样。只是Policy Gradient采用随机梯度上升来求解目标函数最大值;而TRPO采用Trust Region算法求解目标函数最大值。TRPO算法比Policy Gradient更加稳健。
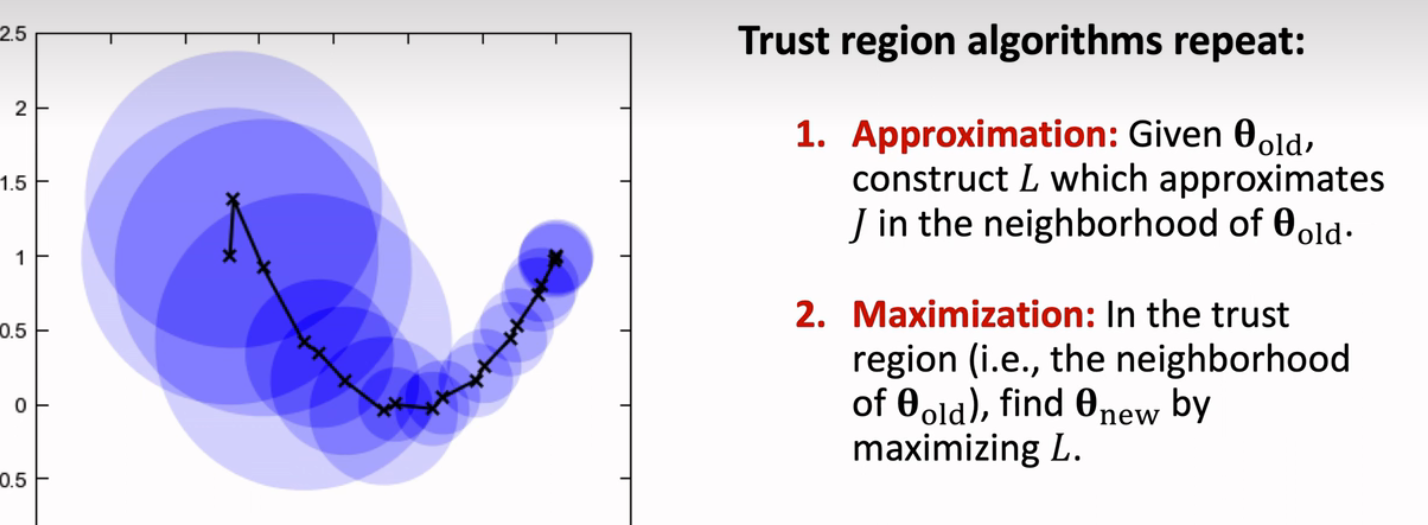
Trust Region概念如下,领域内L函数可以近似J函数,那么这个领域就叫做trust region。L函数可以构造的比J函数更方便计算。

置信域算法是不断重复下面两个步骤,如下,1)根据θ找到置信域,找到L函数;2)找到最大化L的参数θ,然后继续第一步。
TRPO算法目标函数如下(TRPO第一种形式):
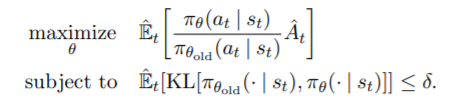
如果将上面第二个式子约束条件变成惩罚项,那么TRPO目标函数变成如下形式(TRPO第二种形式):

8 PPO
PPO算法是对TRPO优化效率上一个改进,其通过修改TRPO算法,使其可以使用SGD算法来做置信域更新,并且用clipping的方法方法来限制策略的过大更新,保证优化在置信域中进行.
PPO算法是openAI默认的强化学习算法。chatGPT就是采用PPO算法进行的强化学习。
下面公式参考2017年openAI论文《Proximal Policy Optimization Algorithms 》。
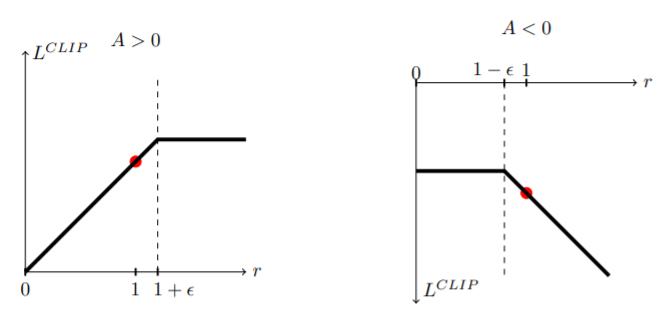
1)PPO算法有两种,下面是Clipped Surrogate Objective 方法的目标函数(对应TRPO第一种形式):


Clip是将新旧策略做比值,将这一比值限制在一定范围。clip这里是,如果第一项小于第二项,就输出第二项;如果大于第三项,就输出第三项。
ϵ 是一个超参数,可以取0.2。
2)下面是PPO第二种(对应TRPO第二种形式),该方法实验结果没有CLIP效果好:

9 Actor-Critic算法
Actor-Critic算法由两部分组成:Actor和Critic。其中Actor用的是Policy Gradient,Critic用的是Q-learning,所以它实际上是策略迭代法和价值迭代法的结合.

10 A3C
A3C(Asynchronous Advantage Actor-critic)利用多线程的方法,同时在多个线程里面分别和环境进行交互学习,每个线程都把学习的成果汇总起来,整理保存在一个公共的地方。并且,定期从公共的地方把大家的齐心学习的成果拿回来,指导自己和环境后面的学习交互。
相比Actor-Critic,A3C的优化主要有3点,分别是异步训练框架,网络结构优化,Critic评估点的优化。其中异步训练框架是最大的优化。
A3C算法通过多个work和环境互动,把环境的梯度给一个全局的网络,也就是通过不同work共同更新一个网络,每次更新全局网络,都把work的网络和全局网络同步,在下次work返回梯度的时候,都是比较的全局网络与环境互动的梯度,保障了全局网络不断朝好的方向发展。

11 DDPG
深度确定性策略梯度算法DDPG(Deep Deterministic Policy Gradient)是DQN的扩展版,可以简单的看成是DQN算法加上Actor-Critic框架。解决了DQN不能用于连续性动作的缺点。DDQG也借鉴了DQN的经验回放 (Experience Replay)的技巧。
下面算法摘自2019年google DeepMind的《CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING 》。

首先,初始化Actor和Critic以及其各自的目标网络共4个网络以及经验池replay buffer R。
在Actor网络输出动作时,DDPG通过添加随机噪声的方式实现exploration,可以让智能体更好的探索潜在的最优策略。之后是采取经验回放的技巧。把智能体与环境交互的数据 (,,,) 存储到R。随后每次训练从中随机采样一个minibatch。
在参数更新上,先利用Critic的目标网络 Q′ 来计算目标值 ,利用 与当前Q值的均方误差构造损失函数,进行梯度更新。对于Actor的策略网络,其实就是把Actor的确定性动作函数代进Q-function的a,然后求梯度,最后是更新目标网络。
12 Soft Actor Critic (SAC)
PPO算法是目前最主流的DRL算法,但是PPO是一种on-policy算法,存在sample inefficiency的缺点,需要巨量的采样才能学习。DDPG及其拓展是面向连续控制的off-policy的算法,相对于PPO来说更sample efficient,但是它存在对其超参数敏感,收敛效果差的问题。SAC算法是面向最大熵强化学习开发的一种off-policy算法。
如下图所示,SAC结合了PPO和DDPG。

下面公式参考2018年论文《Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor 》。
1.soft value function

2.soft Q-functio n

3.soft策略


4.最终整体算法:

13 参考
- Q-Learning:Q-Learning_帅帅气气的黑猫警长的博客-CSDN博客
- 什么是 Q-learning?:什么是 Q-learning? - 简书
- 深度强化学习——DQN算法原理:深度强化学习——DQN算法原理_流萤点火的博客-CSDN博客
- 强化学习第六篇--DQN算法https://www.cnblogs.com/huanglinqiang/articles/15045229.html?ivk_sa=1024320u
- B站,李宏毅《强化学习》
- reinforce算法:https://www.cnblogs.com/devilmaycry812839668/p/14186743.html
- Actor-Critic算法:Actor-Critic算法 | ByteCat
- 强化学习入门——深入理解DDPG:强化学习入门——深入理解DDPG - 知乎
- 【强化学习】时间差分法(TD):【强化学习】时间差分法(TD)_shura_R的博客-CSDN博客
- [A3C]:看我的影分身之术(附代码及代码分析):[A3C]:看我的影分身之术(附代码及代码分析) - 知乎