C语言扩展
CUDA的编程接口是C语言的扩展集,其中主要的是Runtime库,该库分为三个组件:主机组件、设备组件以及公共组件
主机组件:在主机上运行并提供函数来控制和访问一个或多个计算设备
设备组件:设备运行并且提供特定设备的函数
公共组件:提供内置矢量类型和主机与设备编码都支持的C语言标准库的一个子集
提出疑问
- 函数定义和声明类型的限定语句,主机和设备(GPU)的函数是如何调用?
- 如何定义GPU的内存位置及大小?
- 一个来自kernel的函数如何在设备上执行?
- GPU的块和线程的指标如何调用?
- 如何编译CUDA代码?
函数类型限定语句
__device__ // 在设备上执行,仅可从设备上调用
__global__ // 限定一个函数作为kernel的存在,在设备上执行,仅可从主机上调用
__host__ // 在主机上执行,仅可从主机上调用
/*
__host__ 可以与 __device__ 限定词的组合,支持主机和设备双向编译
*/
/*
限定:
__device__ 和 __global__ 不支持递归、内部不能声明静态变量、不能有自变量的一个变量数字
__device__ 不能拿到函数地址,另外,函数指向 __global__ 是支持的
__global__ 和 __host__ 不能一起使用
__global__ 函数必须要void的返回类型,调用到__global__函数必须指定它的执行配置
__global__ 函数的调用是同步的,意味着设备执行完成前返回
__global__函数参数目前是通过共享内存到设备的,并且被限制在256 个字节
*/
变量类型限定语句
__device__
__device__限定词声明驻留在设备上的一个变量。
最多的一个其它类型限定词被定义在下面的三项里
可以与__device__一起共同用于进一步指定变量归属在哪些内存空间,这个变量:
- 驻留在全局内存空间
- 具有应用的生存期
- 从栅格内所有线程和从主机通过runtime 库是可访问的
__constant__
__constant__限定词,与__device__一起随机使用,声明一变量
- 驻留在常量内存空间
- 具有应用的生存期
- 从栅格内所有线程和从主机通过runtime 库的是可访问的
__shared__
__shared__限定词,与__device__一起选择使用,声明一个变量:
- 驻留在线程块的共享内存空间中
- 具有块的生存期
- 只有块之内的所有线程是可访问的
在线程中共享的变量有完全的顺序一致性
只有执行__syncthreads()函数,从其他线程的写操作中才保证可见
除非变量被定义为可挥发的,否则只要前一个状态到达,编译器将自由的优化共享内存中的读写
当声明一个在共享内存的变量作为一个外部数组时,例如 extern_shared_float shared[];
数组的大小是由发送时间决定的。所有变量用这种方式声明的,开始于内存的同一个地址
因此在数组的变量布局必须通过offset(位移量)明确地加以控制
例如,如果你想要如下定义
short array0[128];
float array1[64];
int array2[256];
在动态分配的共享内存,你可以用以下方式定义数组
extern __shared__ short array[];
__device__ void func() //__device__or__global__function
{
Short* array0 = (short*)array;
float* array1 = (float*)&array0[128];
int* array2 = (int*)&array1[64];
}
限定
这些限定词不允许函数的 :struct和union成员,形式参数和局部变量在主机上执行
__shared__和__constant__变量隐含了静态存储
__device__,__shared__ 和 __constant__ 变 量 不 能 被 用 extern 关 键 字 定 义 为 外 部 使 用
__device__和__constant__变量只允许在文件范围
__constant__变量不能从设备上赋值,仅可以通过主机 runtime 函数从主机上赋值
__shared__变量不能作为它们声明的一部分得到初始化
一个不用任何限定词在设备码中声明的自变量通常驻留在一个寄存器中
尽管在某些情况下编译器可以选择在局部内存里安置它
通常在这个情况下,大型结构或者数组将消耗许多寄存器空间,并且编译器不能确定数组用常量数量建立了索引
ptx 汇编代码的检查(通过- ptx 或-keep 选项编译获得的)将指出,如果变量在第一个编译阶段期间被安置在局部内存,因此它将声明是使用.local 助记符或者使用ld.local 和 st.local 助记符访问的
假如它没有这样做,即使它们发现它为目标架构消耗太多寄存器空间,随后编译阶段仍然可以做出另外的决定
可以使用--ptxas-option=-v 生成局部内存使用量报告(lmem)。
执行在设备上的指针代码支持,当编译器可以解析它们是否指向全局内存空间或者局部内存空间
否则它们将被限制只指向寻址的内存或在全局内存中声明的空间。
解除一个指针在主机上执行的全局或共享内存中的代码,或者载设备上执行的主机内存代码
其结果产生一个未定义的行为,从而产生片断错误或者应用终止。
只能通过设备代码中的__device__,__shared__或__constant__变量来获取地址
其中__device__或__constant__变量的地址只能通过cudaGetSymbolAddress()获得
执行配置
所有__global__函数的调用必须指定执行配置
执行配置定义了通常在设备执行的函数的栅格和块的维数,以及同样相关的stream。
它通过在函数名称和用括弧括起来的参数之间插入<<< Dg, Db, Ns,S>>>来指定
Dg 是类型dim3并且指定栅格的维数和大小,这样Dg.x * Dg.y 等于被发送的块的数量;
Db 是类型dim3并且指定每个块的维数和大小,这样Db.x * Db.y * Db.z 等于每个块的线程数量;
Ns 是类型size_t 并且指定在共享内存中的字节数量,这个共享内存是静态分配的内存之外的动态分配每个块的内存; 这个动态分配的内存是被任何一个声明为外部数组的变量使用的、Ns 是一个默认为0 的可选参数。
S 是类型cudaStream_t 并且指定相关的stream;S 是一个默认为0 的可选数
作为例子,函数被声明为
__global__ void Func(float* parameter);
必须象这样调用:
Func<<< Dg, Db, Ns >>>(parameter);
执行配置的函数参数在调用前将被评估,且通过共享内存传至设备。
如果Dg 或Db 大于设备允许的最大值,或者Ns 的值大于减去(共享内存中的静态分配的内存,函数参数,和执行配置))的值,函数将无法被调用
内置变量
/*
gridDim
这个变量是类型dim3 (参见4.3.1.2 部分)并且包含栅格的维数。
blockIdx
这变量是类型uint3 (参见4.3.1.1 部分)并且包含栅格之内的块索引。
blockDim
这变量是类型dim3 (参见4.3.1.2 部分)并且包含在块的维数。
threadIdx
这变量是类型uint3 (参见4.3.1.1 部分)并且包含块之内的线程索引。
限定
内置变量不允许取得任何地址。
不允许赋值到任何内置变量。
*/
NVCC 编译
nvcc 是编译CUDA 代码过程的编译器驱动程序的简称:它提供简单和熟悉的命令行选项,并且通过调用实施不同编译阶段汇集的工具来执行它们
nvcc 的基本工作流程在于从主机代码中分离出设备代码,并且编译设备代码成为一个二进制格式的或cubin 对象
生成的主机代码输出,作为使用其他工具提交编译的C 代码,或者作为在最后编译阶段期间直接调用主机编译器的对象代码
应用程序可以直接忽略生成的主机代码并使用CUDA 驱动程序API 加载在设备上的cubin 对象或者链接生成的主机代码
代码包括作为一个全局初始化的数据数组的cubin 对象,并且包含一个执行配置语法的转换,和进入必要的CUDA Runtime 的起始码,来加载和发送每个编译了的Kernel。
编译器处理CUDA 源文件的前端部分完全遵照C++的语法
主机代码完全支持C++。但是设备代码只支持C++中的C 子集;
在基本块中的C++的特性,比如:classes, inheritance, 或者变量的声明是不支持的
作为使用C++语法的结果,void 指针(例如,通过malloc()返回)在没有使用typecast 的情况下不能分配给non-void 的指针。
下面介绍NVCC 两个编译器侦测。
__noinline__
默认下,__device__函数总是inline 的
__noinline__函数可以作为一个非inline 函数的提示
函数本身必须放在调用的文件中,编译器不能保证函数带有指针参数和函数带有大量参数表的__noinline__的限定词正常工作。
#pragma unroll
默认下,编译器为已知的行程计数展开小型循环
#pragma unroll 可以侦测和控制任何展开的循环
它必须放在这个循环之前,并只作用于这个循环。同时,可以通过一个参数指定循环可以展开多少次
例如:
#pragma unroll 5
For (int i = 0; i < n; ++i)
循环将展开5 次。请自行确定展开动作不会影响到程序的正确性。
如果#pragma unroll 后面没有附值,当行程计数为常数时,循环完全展开,否则不会展开
公共Runtime 组件
公共的Runtime 的组件可同时被主机和设备函数使用
内置矢量类型
char1, uchar1, char2, uchar2, char3, uchar3, char4, uchar4, short1, ushort1,
short2, ushort2, short3, ushort3, short4, ushort4, int1, uint1, int2, uint2, int3,
uint3, int4, uint4, long1, ulong1, long2, ulong2, long3, ulong3, long4, ulong4,
float1, float2, float3, float4
这些矢量类型是源于基本的整型和浮点类型
它们是结构和第1,第2,第3,还有第4 个组件可通过域 x, y, z, 和 w 分别访问
它们全都带有一个来自格式make_<type name>的构造器函数
例如:int2 make_int2(int x, int y); 通过赋值(x, y)创建一个类型int2 的矢量
dim3 类型
这个类型是基于uint3 的用于指定维数的整型矢量类型
当定义一个类型dim3 的变量时,所有剩余的非特指的组件初始化为1
数学函数
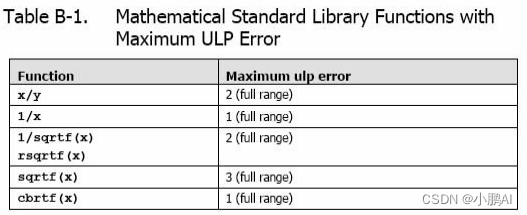
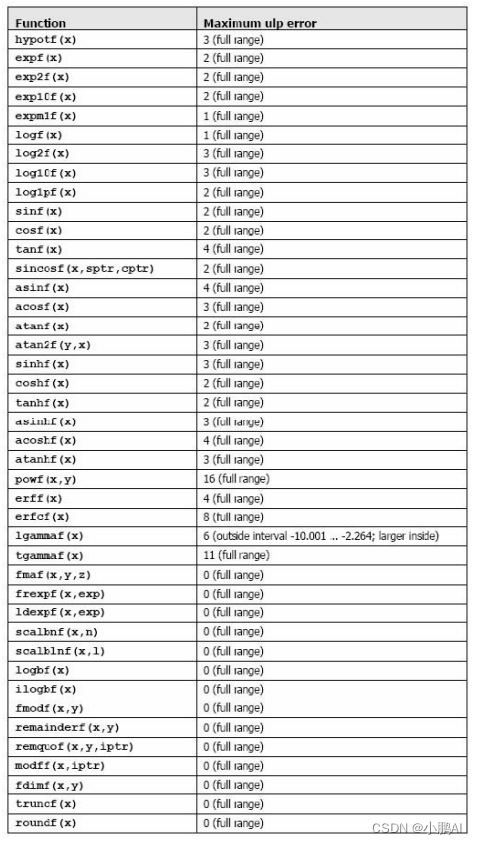
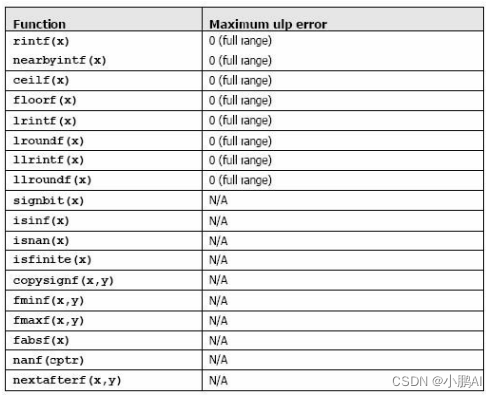
Table B-1 数学函数可以被用作主机和设备函数,每个函数的误差极限通过了密集测试,但不保证绝对正确
加法和乘法为IEEE 兼容的,所以拥有最大误差0.5 ulp。它们通常被合并成一个乘-加指令(FMAD)
我们建议求浮点数运算到整型时,使用rintf(),而不是roundf()
因为roundf()映射8 个指令序列,而rintf()只映射一个指令
truncf(),ceilf(),和floorf()同样也只映射一个指令
CUDA runtime 库也支持整型的min()和max(),同样映射一个指令
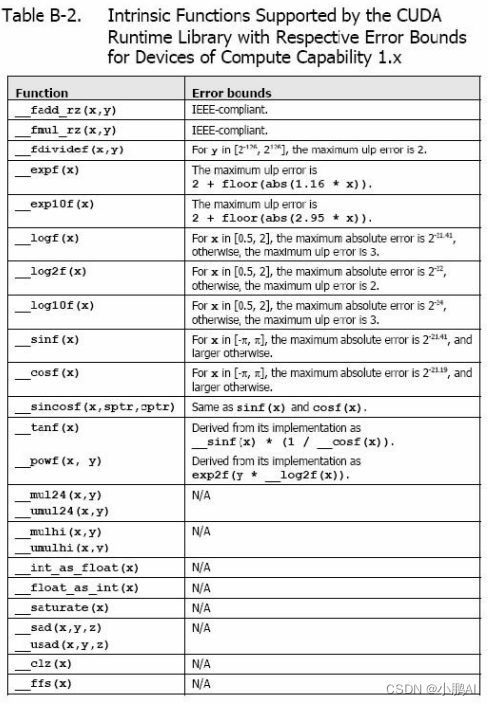
Table B-2 函数只能被用作设备函数
它们的误差限是GPU 特定的
虽然这些函数的精度更低,但是它们的速度比表B-1 中的一些函数快很多;它们拥有同样的前缀
__fadd_rz(x,y)使用舍入零的方式计算浮点参数x 和y 和__fmul_rz(x,y)使用舍入零的方式计算浮点参数
x
x
x 和
y
y
y 乘积
常规的浮点除法和__fdividef(x,y)拥有同样的精度,但对于
2
126
<
y
<
2
128
2^{126} < y < 2^{128}
2126<y<2128
__fdividef(x,y) 的结果为零,而常规的除法可以得到正确的结果同样的,对于
2
126
<
y
<
2
128
2^{126}< y <2^{128}
2126<y<2128 ,如果
x
x
x 是无穷大
__fdividef(x,y) 的结果是NaN(结果是无穷大乘于零),常规的除法返回无穷大
__[u]mul24(x,y)计算24 位最低有效位的整型参数x 和y 的乘积,并且给出32 位最低有效位的结果。
x
x
x 和
y
y
y 的8 位最高有效位被忽略
__[u]mulhi(x,y)计算整型参数
x
x
x 和
y
y
y 的乘积,并且给出64 位结果中的32 位最高有效位
__[u]mul64hi(x,y)计算64 位整型参数
x
x
x和
y
y
y 的乘积,并且给出128 位结果中的64 位最高有效位
__saturate(x)如果
x
x
x 小于0,返回0;如果
x
x
x 大于1 返回1;如果x 在[0,1]之间,返回
x
x
x
__[u]sad(x,y,z)(Sum of Absolute Difference )求整型参数
z
z
z 与整型参数
x
x
x 和
y
y
y 差的绝对值的和
__clz(x)计算32 位整型参数
x
x
x的前导零
__clzll(x)计算64 位整型参数
x
x
x的前导零
__ffs(x)返回整型参数x 的第一个为1 位的位置。最低有效位的位置是1,如果x 是0
__ffs()返回0。这里和linux 函数ffs 是一样的
__ffsll(x)返回64 位整型参数
x
x
x 的第一个为1 位的位置。最低有效位的位置是1,如果x 是0
__ffsll()返回0。这里和Linux 函数ffsll 是一样的
时间函数
clock_t clock(); 每个时钟周期递增下的计数器的返回值
在 kernel 开始和的结束时采样这个计数器,取得这个二个采样的差
并且记录着每线程每时钟周期通过设备完全地执行线程取得的结果
而不是设备执行线程指令时实际花费的时钟周期数量
前者的数字是比后者更大是因为线程是被切成时间段的
纹理类型
CUDA 支持硬件纹理渲染的一个子集,通过GPU 为图形使用纹理内存
通过纹理内存读取数据相比全局内存有很多性能上的优势
纹理内存通过一个叫texture fetches 的设备函数从kernel 读取
Texture fetch 的第一个参数指定一个叫texture referece 的对象
Texture reference 定义纹理内存的哪一个部分被fetch
在被kernel 使用之前,它必须通过主机的runtime函数绑定到一些内存区域
一些texture reference 也许绑定在同一个纹理下或者纹理映射的内存中
Texture reference 有一些属性
其中的一个就是,它可以通过一个纹理坐标指定纹理是否使用一维数组寻址
或者通过两个纹理坐标指定纹理是否使用二维数组寻址
数组的元素被简称为texels(texture elements)
另一个属性是,为纹理的fetch 定义输入输出数据类型
Texture Reference 声明
一些texture reference 的属性是固定的,它们在声明texture reference 时被指定。一个texture reference在文件范围作为类型texture 的一个变量被声明
Texrure<Type, Dim, ReadMode> texRef;
其中
Type指定的数据类型是在拾取纹理时返回的Dim指定texture reference的维数,它等于1 或2;Dim的是默认为1 的一个可选自变量;ReadMode等于cudaReadModeNormalizedFloat或cudaReadModeElementType; 如果它是cudaReadModeNormalizedFloat而且Type是一个16-bit或8-bit的整型类型,实际上返回的值将被看作浮点类型,unsigned的整型类型被映射到[0.0,1.0],signed的整型类型被映射到[-1.0,1.0];例如,一个带有值0xff 的无符号的8-bit 纹理元素读作1;如果它是cudaReadModeElementType,将不执行转换;ReadMode是一个默认到cudaReadModeElementType的可选自变量
Runtime Texture Reference 属性
一些texture reference 的属性是不固定的,它们可以通过主机的runtime 改变
它们可以指定纹理坐标是否是normalized ,寻址模式,和纹理过滤。
默认下,纹理通过浮点数坐标[0,N)引用,N 是关于坐标在空间上纹理的大小
例如:一个64x32 大小的纹理拥有坐标范围x 轴[0,63]和y 轴[0,31]
Normalized 的纹理通过坐标[0.0,1.0)引用,而不是[0,N)
因此,同样的64x32 纹理将被指向normalized 的坐标x轴[0.0,1.0)和坐标y轴[0.0,1.0)
Normalized 的纹理坐标天生适合一些应用程序,例如纹理坐标独立于纹理大小。
寻址模式定义了,当纹理坐标超出范围后会怎样
当使用unnormalized 的纹理坐标时,纹理坐标超出范围[0, N)时,小于0 的值被设成0,大于N 的值被设成N-1
当使用normalized 的纹理坐标时,纹理坐标范围被限制在[0.0,1.0)。对于normalized 的纹理坐标,同样指定了warp寻址
warp 寻址通常被用于,当纹理包含一个周期性的信号时它只作用于纹理坐标的分数部分
例如,1.25 将被看作0.25,-1.25 将被看作0.75。
线性纹理过滤只能用在纹理被设置为返回浮点数据的情况下
它在邻近的texel 中执行一个低精度的插值texel 周边的纹理拾取地址将被读取
并基于texel 所在的纹理坐标返回插值的纹理拾取值
简单的插值执行在一维纹理中,bilinear 插值执行在二维纹理中
线性内存纹理操作对比CUDA 数组
一个纹理可以被划在线性的内存中或者一个CUDA 数组中, 纹理分配在线性内存中:
- 只有维数为1 时;
- 不支持纹理过滤;
- 只能使用non-normalized 纹理坐标寻址;
- 不能支持不同的寻址模式:超出范围的纹理访问返回0;
设备Runtime 组件
设备runtime 的组件只能用于设备函数
同步函数:void __syncthreads();
在一个块内同步所有线程。一旦所有线程到达了这点,恢复正常执行
__syncthreads()通常用于调整在相同块之间的线程通信
当在一个块内的有些线程访问相同的共享或全局内存时
对于有些内存访问潜在着read-after-write, write-after-read, 或者 write-after-write 的危险
这些数据危险可以通过同步线程之间的访问得以避免
__syncthreads() 允许放在条件代码中,但只有当整个线程块有相同的条件贯穿时,否则代码执行可能被挂起或导致没想到的副作用
类型转换函数
下面函数的后缀指定IEEE-754 的舍入模式
rn 是求最近的偶数
rz 是逼近零
ru 是向上舍入(到正无穷)
rd 是向下舍入(到负无穷)
int __float2int_[rn,rz,ru,rd](float); 用指定的舍入模式转换浮点参数到整型
Unsignde int __float2unit_[rn,rz,ru,zd](float); 用指定的舍入模式转换浮点参数到无符号整型
float __int2float_[rn,rz,ru,rd](int); 用指定的舍入模式转换整型参数到浮点数
float __int2float_[rn,rz,ru,rd](unsigned int); 用指定的舍入模式转换无符号整型参数到浮点数
Type Casting 函数
float __int_as_float(int); 在整型自变量上执行一个浮点数的type cast,保持值不变
例如,__int_as_float(0xC0000000) 等于-2
int __float_as_int(float); 在浮点自变量上执行的一个整型的type cast ,保持值不变
例如,__float_as_int (1.0f)等于0x3f800000
纹理函数
- 设备内存纹理操作 :设备内存中的纹理通过
tex1Dfetch()函数访问
template<class Type>
Type tex1Dfetch(
texture<Type, 1, cudaReadModeElementType> texRef,
int x);
float tex1Dfetch(
texture<unsigned char, 1, cudaReadModeNormalizedFloat> texRef,
int x);
float tex1Dfetch(
texture<signed char, 1, cudaReadModeNormalizedFloat> texRef,
int x);
float tex1Dfetch(
texture<unsigned short, 1, cudaReadModeNormalizedFloat> texRef,
int x);
float tex1Dfetch(
texture<signed short, 1, cudaReadModeNormalizedFloat> texRef,
int x);
这些函数通过纹理坐标x 拾取线性内存中绑定到texture reference texRef 的区域
对于整型来说,不允许纹理过滤和选择寻址模式。对于这些函数,可能需要将整型数升级到32-bit 浮点数
下面的函数展示了2-和4-元组的支持
float4 tex1Dfetch(
texture<uchar4, 1, cudaReadModeNormalizedFloat> texRef,
int x);
通过纹理坐标x 拾取线性内存中绑定到texture reference texRef 的区域
- CUDA 数组纹理操作:从CUDA 数组中的纹理通过tex1D()或tex2D()函数访问
template<class Type, enum cudaTextureReadMode readMode>
Type tex1D(texture<Type, 1, readMode> texRef, float x);
template<class Type, enum cudaTextureReadMode readMode>
Type tex2D(texture<Type, 2, readMode> texRef, float x, float y);
这些函数通过纹理坐标x 和y 拾取CUDA 数组中绑定到texture reference texRef 的区域
Texture reference 的编译时(固定的)和运行时(可变的)的属性决定了,坐标如何被解释,纹理拾取时将有哪些处理发生,和纹理拾取返回的值
原子函数
只有计算兼容性为1.1 的设备才可以使用原子函数
/*
1. atomicAdd()
从全局内存中读取地址为address 的32-bit 字old,计算(old + val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old
*/
int atomicAdd(int* address, int val);
unsigned int atomicAdd(unsigned int* address, unsigned int val);
/*
2. atomicSub()
从全局内存中读取地址为address 的32-bit 字old,计算(old - val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old
*/
int atomicSub(int* address, int val);
unsigned int atomicSub(unsigned int* address, unsigned int val);
/*
3 atomicExch()
从全局内存中读取地址为address 的32-bit 字old,存储val 返回全局内存中的同一地址。
这二个操作由一个原子操作执行。函数返回old。
*/
int atomicExch(int* address, int val);
unsigned int atomicExch(unsigned int* address, unsigned int val);
float atomicExch(float* address, float val);
/*
4 atomicMin()
从全局内存中读取地址为address 的32-bit 字old,计算old 和val 的最小值,将结果返
回全局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old。
*/
int atomicMin(int* address, int val);
unsigned int atomicMin(unsigned int* address,
unsigned int val);
/*
5 atomicMax()
从全局内存中读取地址为address 的32-bit 字old,计算old 和val 的最大值,将结果返
回全局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old
*/
int atomicMax(int* address, int val);
unsigned int atomicMax(unsigned int* address, unsigned int val);
/*
6 atomicInc()
从全局内存中读取地址为address 的32-bit 字old,计算((old >= val) ? 0 :
(old+1)),将结果返回全局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old
*/
unsigned int atomicInc(unsigned int* address, unsigned int val);
/*
7 atomicDec()
从全局内存中读取地址为address的32-bit 字old,计算(((old ==0)| (old > val)) ?
val : (old-1)), 将结果返回全局内存中的同一地址。这三个操作由一个原子操作执行。
函数返回old。
*/
unsigned int atomicDec(unsigned int* address, unsigned int val);
/*
8 atomicCAS()
从全局内存中读取地址为address 的32-bit 字old,计算(old == compare ? val :
old),将结果返回全局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old
(比较和置换)
*/
int atomicCAS(int* address, int compare, int val);
unsigned int atomicCAS(unsignedint*address, unsigned int compare, unsigned int val);
/*
9. atomicAnd()
从全局内存中读取地址为address 的32-bit 字old,计算(old & val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old。
*/
int atomicAnd(int* address, int val);
unsigned int atomicAnd(unsigned int* address, unsigned int val);
/* 10.
atomicOr()
从全局内存中读取地址为address 的32-bit 字old,计算(old | val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old。
*/
int atomicOr(int* address, int val);
unsigned int atomicOr(unsigned int* address, unsigned int val);
/*
11 atomicXor()
从全局内存中读取地址为address 的32-bit 字old,计算(old ^ val),将结果返回全
局内存中的同一地址。这三个操作由一个原子操作执行。函数返回old
*/
int atomicXor(int* address, int val);
unsigned int atomicXor(unsigned int* address, unsigned int val);
原子函数在全局内存中的一个32-bit 字中执行一个读-修改-写的原子操作
例如,atomicAdd()在全局内存中的同一个地址读取一个32-bit 字,加一个整型进去,并写回结果到同一个地址
所谓“原子”就是保证操作不会干扰其它线程。在操作完成之前,其它线程也无法访问这个地址。
原子操作只能用于32-bit 有符号和无符号的整型数。
主机Runtime 组件
主机Runtime 的组件只能被主机函数使用
它提供函数来处理以下问题:
- 设备管理
- Context 管理
- 内存管理
- 编码模块管理
- 执行控制
- Texture reference 管理
- OpenGL 和Direct3D 的互用性
它由二个API 组成:
一个低级的API 调用CUDA 驱动程序API
一个高级的API 调用的CUDA runtime API ,在CUDA 驱动程序API 之上运行的API
这些API 是互相排斥:一个应用程序应该选择其中之一来使用
CUDA runtime 通过提供固有的初始化,context 管理,和模块管理减轻了设备代码的管理
Nvcc 生成的C 主机代码基于 CUDA runtime,因此应用程序连接这个代码必须使用 CUDA runtime API
相反, CUDA 驱动程序API 要求更多的代码,使编程和调试更加困难,但它提供更好的控制,并且是语
言独立的,因为它只处理cubin 对象
尤其是使用CUDA 驱动程序API 配置和启动Kernel 更加困难,因为执行配置和kernel 参数必须指定外在的函数调用,来替换执行配置语法
同样的,设备仿真不能与CUDA 驱动程序API 一起工作
CUDA 驱动程序API 通过cuda 动态库提供,所有它的进入点带有前缀cu
CUDA runtime API 通过cudart 动态库提供,所有它的进入点带有前缀cuda
公共概念
设备
两个API 都提供了函数来枚举在系统上可使用的设备,查询它们的属性,并选择它们中的一个来执行kernel
一些主机线程可以在同一设备上执行设备代码,但从设计角度上看,一个主机线程只能在一个设备上执行设备代码
因此,多主机线程需要在多个设备上执行设备代码
另外,任何在一个主机线程中通过runtime创建的CUDA 源文件不能被其它主机线程使用
内存
设备内存可被分配到线性内存或者是CUDA 数组
在设备上的线性内存使用32-bit 地址空间,因此单独分配的实体可以通过指针的互相引用
例如,在一个二元的树结构中, CUDA 数组是针对纹理拾取优化的不透明的内存布局, 它们是一维或二维的元素组成的,每个有1 个,2个或者4 个组件,每个组件可以是有符号或无符号8-bit,16-bit或32-bit整型,16-位浮点(仅通过CUDA 驱动
程序API 支持),或32 位浮点。
CUDA 数组只能通过kernel 纹理读取。
通过主机的内存复制函,数线性内存和 CUDA 数组都是可读和可写的
不同于由malloc()函数分配的pageable 主机内存,主机runtime 同样提供可以分配和释放page-locked主机内存的函数
如果主机内存被分配为page-locked
使用page-locked 内存的优势是,主机内存和设备内存之间的带宽将非常高
但是,分配过多的page-locked 内存将减少系统可用物理内存的大小,从而降低系统整体的性能
OpenGL Interoperability
OpenGL 缓冲器对象可以被映射到CUDA 地址空间,使CUDA 能够读取被OpenGL 写入的数据
或者使CUDA 能够写入被OpenGL 消耗的数据
Direct3D Interoperability
Direct3D 9.0 顶点缓冲器可以被映射到CUDA 地址空间,使CUDA 能够读取被Direct3D 写入的数据
或者使CUDA 能够写入被Direct3D 消耗的数据
一个CUDA context 每次只可以互用一个Direct3D 设备,通过把begin/end 函数括起来调用
CUDA context 和Direct3D 设备必须建立在同一个GPU 上
可以通过查询与CUDA 设备是否关联使用Direct3D的适配器来确保
Direct3D 设备必须使用D3DCREATE_HARDWARE_VERTEXPROCESSING 标志创建
CUDA 尚不支持:
- 除Direct3D 9.0 之外的版本
- 除顶点缓冲器之外的Direct3D 对象
- cudaD3D9GetDevice()和cuD3D9GetDevice()同样可以确保Direct3D 设备和CUDA context 建立在不同的设备上,比如Direct3D 的loading balance 和CUDA 的over interoperability
异步的并发执行
为了促使主机和设备之间的并发执行,一些runtime 函数是异步的:在设备完成请求的任务之前,控制权将交还给应用程序
- Kernel 通过__global__ 函数或cuGridLaunch()和cuGridLaunchAsync()启动
- 执行内存拷贝的函数需要后缀Async
- 执行设备到设备内存拷贝的函数
- 设置内存的函数
一些设备也可以执行page-locked 主机内存和设备内存之间并发的拷贝
应用程序可以与CU_DEVICE_ATTRIBUTE_GPU_OVERLAP一起通过cuDeviceGetAttribute()查询是否有这个功能
这个功能目前只支持内存拷贝,且是通过cudaMallocPitch() 或 cuMemAllocPitch() 分配的不包括CUDA 数组或2D 数组的
应用程序通过流(stream) 管理并发。一个流是有序执行的操作序列。另一方面,不同的流也许会遵循其它或并行的乱序执行
一个流被定义为,通过建立流对象且指定它的流参数到kernel 的启动序列和主机到设备的内存拷贝
只有当全部的操作已完成的情况下:包括操作本事是流的一部分,和在完成之前没有随之的操作
一个带有零参数的流才开始,例如:任何kernel 的启动,内存的设置或内存的拷贝
cudaStreamQuery()和 cuStreamQuery()提供一个方法使应用程序查询一个流中的全部操作是否完成了
cudaStreamSynchronize() 和 cuStreamSynchronize()提供一个方法强制应用程序等待,直到流中的全部操作完成
同样的,cudaThreadSynchronize()和cuThreadSynchronize()应用程序可以强制runtime 等待,直到全部设备任务完成
为了避免速度下降,这些函数最好用于时间目的的,孤立启动的或内存拷贝失败的情况
runtime 同样提供一个方法更近的监控设备的进程
在精确的时间下,让应用程序异步的纪录程序中任意一点的事件,并可查询这些事件是何时被纪录的
不同流中的两个操作不能并发的执行
无论是page-locked 主机内存分配,设备内存的分配,设备内存的设置,设备到设备的内存拷贝,或它们之间的事件纪录
可以通过设置CUDA_LAUNCH_BLOCKING 环境变量为1,来全局的关闭异步执行,对于所有系统上的CUDA 应用程序
这个功能仅限debug 用途,不要用于增加软件产品的可靠性
Runtime API
[初始化]
没有明确针对RuntimeAPI 的初始化函数; 它在第一次Runtime 函数调用时初始化
需要注意的是,何时适时的调用Runtime 函数,和何时说明从第一次调用进入Runtime 的错误代码
[设备管理]
cudaGetDeviceCount()和cudaGetDeviceProperties()提供一个方法来枚举这些设备和获得它们的属性
int deviceCount;
cudaGetDeviceCount(&deviceCount);
Int device;
for (device = 0; device < deviceCount; ++device) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp,device);
}
cudaSetDevice()用来选择相关于主机线程的设备
cudaSetDevice(device);
一个设备必须在任何__global__函数调用之前选择
否则,device 0 自动地被选择,并且所有随后的设备选择将是无效的
[内存管理]
调用函数用来分配和释放设备内存,访问在全局内存中任意声明的变量分配的内存,和从主机内存到设备内存之间的数据传输。
线性内存通过cudaMalloc()或cudaMallocPitch()分配,通过cudaFree()释放
下面的代码演示,在线性内存中分配一个256 个浮点元素的数组
float* devPtr;
cudaMalloc((void**)&devPtr, 256 * sizeof(float));
分配2D 数组建议使用cudaMallocPitch(), 从而保证访问行地址,或拷贝2D 数组到设备内存的其它区域的最佳性能
返回的pitch 必须用来访问数组元素
下面的代码演示,分配一个宽x 高带有浮点数的2D 数组,和在设备代码中如何循环数组元素:
// host code
float* devPtr;
int pitch;
cudaMallocPitch((void**)&devPtr, &pitch,
width*sizeof(float),height);
myKernel<<<100,512>>>(devPtr,pitch);
// device code
__global__ void myKernel(float* devPtr, int pitch)
{
for (int r = 0; r < height; ++r) {
float* row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; ++c) {
float element = row[c];
}
}
}
CUDA 数组通过cudaMallocArray()分配,通过cudaFreeArray()释放
cudaMallocArray()需要一个格式的解释,通过cudaCreateChannelDesc()建立
下面的代码演示,分配一个宽x 高带有一个32-bit 浮点数的2D 数组:
cudaChannelFormatDescchannelDesc=
cudaCreateChannelDesc<float>();
cudaArray* cuArray;
cudaMallocArray(&cuArray, &channelDesc, width, height);
cudaGetSymbolAddress()用来获得指向全局内存中一个声明的变量分配的内存地址
分配内存的大小用cudaGetSymbolSize()取得
cudaMalloc()分配的线性内存
cudaMallocPitch() 分配的线性内存,CUDA 数组,全局变量分配的内存或常驻内存
下面的代码演示,拷贝一个2D 数组到之前例子中分配的CUDA 数组:
cudaMemcpy2DToArray(cuArray, 0, 0, devPtr, pitch,
width * sizeof(float),height,
cudaMemcpyDeviceToDevice);
下面的代码演示,拷贝一些主机内存数组到设备内存:
float data[256];
int size = sizeof(data);
float* devPtr;
cudaMalloc((void**)&devPtr, size);
cudaMemcpy(devPtr, data, size, cudaMemcpyHostToDevice);
下面的代码演示,拷贝一些主机内存数组到常驻内存:
__constant__ float constData[256];
float data[256];
cudaMemcpyToSymbol(constData, data, sizeof(data));
[流管理]
调用函数用来创建和销毁流,并且判定一个流中的所有操作是否完成
下面的代码演示,创建两个流:
cudaStream_t stream[2];
for(inti=0;i<2;++i)
cudaStreamCreate(&stream[i]);
下面的代码演示,每一个流被依次定义执行一次:从主机到设备的内存拷贝,kernel 启动,从设备到主机的内存拷贝。
for (int i = 0; i < 2; ++i)
cudaMemcpyAsync(inputDevPtr+i*size,hostPtr+i*size,size,cudaMemcpyHostToDevice,stream[i]);
for (int i = 0; i < 2; ++i)
myKernel<<<100, 512, 0, stream[i]>>>(outputDevPtr + i * size, inputDevPtr + i * size, size);
for (int i = 0; i < 2; ++i)
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
cudaThreadSynchronize();
每个流拷贝部分输入数组hostPtr 到设备内存中的输入数组inputDevPtr
通过调用myKernel()在设备上处理inputDevPtr, 并拷贝结果outputDevPtr 到hostPtr 的同一个部分
使用两个流处理hostPtr 允许内存拷贝从一个流覆盖到另一个流对于任何覆盖,hostPtr 必须指向page-locked 的主机内存:
float*hostPtr;
cudaMallocHost((void**)&hostPtr,2*size;
cudaThreadSynchronize()在最后被调用,以确保在继续处理之前全部的流已经完成。
[事件管理]
调用函数用来创建,纪录和销毁事件,并可查询两个事件之间花费的时间
下面的代码演示,建立两个事件:
cudaEvent_tstart,sto;
cudaEventCreate(&stat);
cudaEventCreate(&stop);
这些事件可以用来计算之前代码的时间:
cudaEventRecord(start, 0);
for (int i = 0; i < 2; ++i)
cudaMemcpyAsync(inputDev + i * size, inputHost + i * size, size, cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < 2; ++i)
myKernel<<<100, 512, 0, stream[i]>>> (outputDev + i * size, inputDev + i * size, size);
for (int i = 0; i < 2; ++i)
cudaMemcpyAsync(outputHost + i * size, outputDev + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
[Texture Reference 管理]
调用函数用来管理texture reference
纹理类型是由高级API 定义的公开的结构,texture Reference 类型是由低级API 定义的,例如:
struct textureReference
{
int normalized;
enum cudaTextureFilterMode filterMode;
enum cudaTextureAddressMode addressMode[2];
struct cudaChannelFormatDesc channelDesc;
}
normalized 指定纹理坐标是否是normalized;
如果它不是零,纹理中的全部元素拥有纹理坐标[0,1], 而不是[0,width-1]或[0,height-1],其中width 和height 是纹理的大小;
filterMode 指定过滤模式:基于输入的纹理坐标,计算纹理拾取的值是如何返回的;
过滤模式等于cudaFilterModePoint 或cudaFilterModeLinear;
如果是cudaFilterModePoint,返回的值等于最接近于输入纹理坐标的texel;
如果是cudaFilterModeLinear,返回的值等于最接近于输入纹理坐标的,两个texel(对于一维纹理)或四个texel(对于二维纹理)的线性插值的结果;
cudaFilterModeLinear 需要返回值是浮点类型;
addressMode 指定寻址模式:如果控制超出范围的纹理坐标,则分别指定第一个纹理坐标的寻址模式和第二个纹理坐标的寻址模式;
寻址模式等于cudaAddressModeClamp 或cudaAddressModeWrap;
如果是cudaAddressModeClamp,超出范围的纹理坐标被钳制到合法的范围;
如果是cudaAddressModeWrap,超出范围的纹理坐标被覆盖到合法的范围;
cudaAddressModeWrap 仅支持normalized 的纹理坐标;
channelDesc 定义了,当拾取纹理时返回值的格式;参见下面代码:
struct cudaChannelFormatDesc {
int x, y, z, w;
enum cudaChannelFormatKind f;
};
其中
x,y,z和w 是返回值每个部分的位数
f 是:
cudaChannelFormatKindSigned如 果 这 些 部 分 是 有 符 号 的 整 型 ,cudaChannelFormatKindUnsigned如 果 它 们 是 无 符 号 的 整 型 ,cudaChannelFormatKindFloat如果它们是浮点数。
normalized,addressMode,和filterMode 可以在主机代码中直接修改。
它们只应用在绑定到CUDA 数组的texture reference
在一个kernel 通过texture reference 读取纹理内存之前
texture reference 必须绑定到一个使用cudaBindTexture()或cudaBindTextureToArray()的纹理中。
下面的代码演示,绑定一个texture reference 到通过devPtr 指向的线性内存中:
使用低级API
texture<float, 1, cudaReadModeElementType> texRef;
textureReference* texRefPtr;
cudaGetTextureReference(&texRefPtr, “texRef”);
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaBindTexture(0, texRefPtr, devPtr, &channelDesc, size);
使用高级API
texture<float, 1, cudaReadModeElementType> texRef;
cudaBindTexture(0, texRef, devPtr, size);
下面的代码演示,绑定一个texture reference 到CUDA 数组cuArray 中:
使用低级API:
texture<float, 2, cudaReadModeElementType> texRef;
textureReference* texRefPtr;
cudaGetTextureReference(&texRefPtr, “texRef”);
cudaChannelFormatDesc channelDesc;
cudaGetChannelDesc(&channelDesc, cuArray);
cudaBindTextureToArray(texRef, cuArray, &channelDesc);
使用高级API:
texture<float, 2, cudaReadModeElementType> texRef;
cudaBindTextureToArray(texRef, cuArray);
绑定一个纹理到texture reference 的格式必须匹配声明texture reference 时的参数;
否则,纹理拾取的结果将是未定义的。
cudaUnbindTexture()用来卸载texture reference 的绑定。
[OpenGL Interoperability]
调用函数用来控制OpenGL 的互用性
一个缓冲对象在被映射之前必须注册到CUDA
使用cudaGLRegisterBufferObject():
GLuint bufferObj;
cudaGLRegisterBufferObject(bufferObj);
注册以后,缓冲对象可以通过kenrel 使用设备内存读取或写入,内存设备的地址通过cudaGLMapBufferObject()返回:
GLuint bufferObj;
float* devPtr;
cudaGLMapBufferObject((void**)&devPtr, bufferObj);
卸载映射和注册通过,cudaGLUnmapBufferObject()和cudaGLUnregisterBufferObject()
[Direct3D Interoperability]
调用函数用来控制Direct3D 的互用性
Direct3D 的互用性必须通过cudaD3D9Begin()来初始化,cudaD3D9End()来终止。
一个顶点对象在被映射之前必须注册到CUDA。使用cudaD3D9RegisterVertexBuffer():
LPDIRECT3DVERTEXBUFFER9 vertexBuffer;
cudaD3D9RegisterVertexBuffer(vertexBuffer);
注册以后,缓冲对象可以通过kenrel 使用设备内存读取或写入,内存设备的地址通过cudaD3D9MapVertexBuffer()返回:
LPDIRECT3DVERTEXBUFFER9 vertexBuffer;
float* devPtr;
cudaD3D9MapVertexBuffer((void**)&devPtr, vertexBuffer);
卸载映射和注册通过,cudaD3D9UnmapVertexBuffer()和 cudaD3D9UnregisterVertexBuffer()
[使用设备仿真方式调试]
编程环境不支持任何原生的调试运行在设备上的代码,但伴随而来一个针对调试目的的设备仿真模式
在这个方式(使用-deviceemu 选项)下编译应用程序时,设备代码被编译成针对运行在主机上的
允许开发人员使用主机原生的调试支持来调试应用程序
预处理器宏__DEVICE_EMULATION__在这个模式下被定义
对于当前应用程序的所有代码,包括任何被使用的库,必须被编译,无论对于设备仿真或设备执行
连接设备仿真或设备执行的代码所产生的运行时错误,可以通过cudaErrorMixedDeviceExxcution返回。
当在设备仿真模式下运行应用程序时,编程模型通过runtime 被仿真
对于在线程块中的每条线程,runtime在主机生成一条线程。开发人员需要确定:
主机能够运行每个块线程的最大数量,加上一条主线程
足够的内存可用于运行所有线程,每条线程需要256 KB 堆栈
通过设备仿真模式提供的许多特点使它成为一套非常有效的调试工具:
通过使用主机原生的调试支持,开发人员可以使用调试器的所有特性,像设置断点和数据检查
由于设备代码被编译到主机上运行,这个代码可以把在设备不能运行的代码补充进来
像是对文件或者屏幕(printf(),等)的输入和输出操作
因为所有数据驻留在主机上,任何设备的或者主机特定的数据可以从设备或者主机代码读取;
同样的,任何设备或主机的函数可以从设备或主机代码中调用。
为防止同步的错误使用,runtime 监测死锁情况。
开发人员必须牢记设备仿真模式是模仿设备,不是模拟它
因此,设备仿真模式在发现算法错误上是非常有用的,但某些错误是很难发现
当内存单元在同一时间被栅格之内的多条线程访问时,运行在设备仿真方式下时的结果与运行在设备上时的结果截然不同,因为在仿真模式下线程是顺序的执行。
当解除一个指向主机上的全局内存或者指向设备上的主机内存的引用时,设备执行几乎肯定在一些未定义的方式上失败,反之,设备仿真可以产生正确的结果。
在大多数情况下,在设备上执行和在主机上通过设备仿真模式执行,同一浮点计算将不会产生完全相同的结果。
这在通常情况下是能预料到的,对于同一浮点计算,取得的不同结果是由不同的编译器选项形成的,更不用说不同的编译器,不同的指令组,或者不同的架构了。
特别是,一些主机平台在扩展精度的寄存器里存贮了单精确度浮点计算的中间结果,往往造成设备仿真模式下,精度上的很大不同
当出现这些情况时,开发人员可尝试以下方法,但任何一种方法都不能完全保证工作:
- 声明一些浮点变量因为不稳定而强制单一精确度存贮;
- 使用
gcc编译器的–ffloat-storegcc选项; - 使用
Visual C++编译器的/Op或/fp选项; - 对于
Linux使用_FPU_GETCW()和_FPU_SETCW(),对于Windows使用_controlfp()
函数来强制一部分代码单一精度浮点计算
unsigned int originalCW;
_FPU_GETCW(originalCW);
unsigned int cw = (originalCW & ~0x300) | 0x000;
_FPU_SETCW(cw);
unsigned int originalCW = _controlfp(0, 0);
_controlfp(_PC_24, _MCW_PC);
在一开始,存储控制字的当前值,并强制尾数以24 位存储 _FPU_SETCW(originalCW); 或 _controlfp(originalCW, 0xfffff);
不同于计算设备,主机平台通常也支持规格化的数字
这样可以导致在设备仿真和设备执行模式之间明显不同的结果,因为某些计算在一种情况下可能产生一个有限结果而在另外一个情况下可能
产生一个无限结果。
驱动API
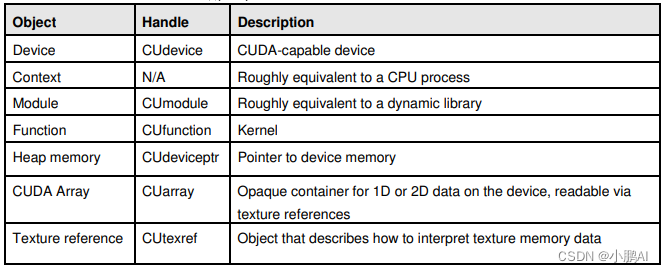
驱动程序API 是基于句柄的,命令式的API:多数对象通过不透明地句柄引用。
可用于CUDA 的对象在表4-1 加以概述。
[初始化]
在其他的函数被调用之前,需要使用cuInit()函数初始化。
[设备管理]
调用函数用来管理当前系统中的设备
cuDeviceGetCount()和cuDeviceGet()用来枚举这些设备
int deviceCount;
cuDeviceGetCount(&deviceCount);
int device;
for (int device = 0; device < deviceCount; ++device) {
CUdevice cuDevice;
cuDeviceGet(&cuDevice, device)
int major, minor;
cuDeviceComputeCapability(&major, &minor, cuDevice);
}
[Context管理]
调用函数用来创建,捆绑和分离CUDA context
一个CUDA context 是类似于一个CPU 处理
在计算API 之内执行的所有资源和行为被压缩在CUDA context里,并且当context 被销毁时系统自动地清理这些资源
除了对象例如模块和纹理引用以外,每个context 有它自己的独立的32bit 地址空间
因此,来自不同的CUDA context 的CUdeviceptr 值引用不同的内存单元
Context 在主机线程中有一个一一对应的机制
一个主机线程当前一次只可以有一个设备context
当一个context 被创建时cuCtxCreate(),它成为了当前调用的主机线程
以一个context 操作的CUDA 函数(大多数函数不包括设备枚举或者context 管理) 将返回CUDA_ERROR_INVALID_CONTEXT,如果当前的线程不是一个合法的context
为了促进运行在同一个context 中的第三方授权的代码之间的互用性,驱动API 提供一个由每个确定客户给定的context 的使用量计数器
例如,如果三个库被加载使用同一个CUDA context ,每个库必须调用cuCtxAttach()来增加使用量计数器,而且当库已经完成context使用时,调用cuCtxDetach()减少使用量计数器
当使用量计数器为0 时context 就被销毁了
对大多数库来说,应用程序应该在加载或初始化库之前创建一个CUDA context;
那样,应用程序可以创建一个用于它自己的context,并且库仅简单的操作context 交给它的任务
[模块管理]
调用函数用来加载和卸载模块,并获得模块中的句柄,变量的指针或函数的定义
模块是动态地可加载的包括设备代码和数据的压缩包,如同Windows 中的DLL, 它们通过nvcc 输出
名称对于所有标志,包括函数,全局变量和纹理引用,在模块范围内提供,以便被独立第三方编写的模块在同一CUDA context 可以互用
下面的代码演示,加载一个模块并为kernel 取得一个句柄:
CUmodule cuModule;
cuModuleLoad(&cuModule, "myModule.cubin");
CUfunction cuFunction;
cuModuleGetFunction(&cuFunction, cuModule, “myKernel”);
[执行控制]
调用函数用来管理在设备上一个kernel 的执行
cuFuncSetBlockShape()用来设置给定函数每个块中线程的数量,和线程ID 如何分配
cuFuncSetSharedSize()指定函数共享内存的大小
cuParam*() 函数集提供用于kernel 的参数,当下次kernel 启动时包含culanuchGrid()或cuLanuch()
cuFuncSetBlockShape(cuFunction, blockWidth, blockHeight, 1);
int offset = 0; int i;
cuParamSeti(cuFunction, offset, i);
Offset += sizeof(i);
float f;
cuParamSetf(cuFunction, offset, f);
offset += sizeof(f);
char data[32];
cuParamSetv(cuFunction, offset, (void*)data, sizeof(data));
offset += sizeof(data);
cuParamSetSize(cuFunction, offset);
cuFuncSetSharedSize(cuFunction, numElements * sizeof(float));
cuLaunchGrid(cuFuntion, gridWidth, gridHeight);
[内存管理]
调用函数用来分配和释放设备内存,并从主机和设备内存之前传输数据。
线性内存通过cuMemAlloc()或cuMemAllocPitch()来分配,cuMemFree()来释放
下面的代码演示,在线性内存中分配一个256 个浮点元素的数组:
CUdeviceptr devPtr;
cuMemAlloc(&devPtr, 256 * sizeof(float));
分配2D 数组建议使用cuMemMallocPitch(),从而保证访问行地址,或拷贝2D 数组到设备内存的其它区域的最佳性能
返回的pitch 必须用来访问数组元素
下面的代码演示,分配一个宽x 高带有浮点数的2D 数组,和在设备代码中如何循环数组元素:
// host code
CUdeviceptr devPtr;
int pitch;
cuMemAllocPitch(&devPtr, &pitch, width * sizeof(float), height, 4);
cuModuleGetFunction(&cuFunction,cuModule,"myKernel");
cuFuncSetBlockShape(cuFunction, 512, 1, 1);
cuParamSeti(cuFunction, 0, devPtr);
cuParamSetSize(cuFunction, sizeof(devPtr));
cuLaunchGrid(cuFunction, 100, 1);
// device code
__global__ void myKernel(float* devPtr)
{
for (int r = 0; r < height; ++r) {
float* row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; ++c) {
float element = row[c];
}
}
}
CUDA 数组通过cuArrayCreate()分配,通过cuArrayDestroy()释放
下面的代码演示,分配一个宽x 高带有一个32-bit 浮点数的CUDA 数组:
CUDA_ARRAY_DESCRIPTOR desc;
desc.Format = CU_AD_T_FLOAT;
desc.NumChannels = 1;
desc.Width = width;
desc.Height = height;
CUarray cuArray;
cuArrayCreate(&cuArray, &desc);
下面的代码演示,拷贝一个2D 数组到之前例子中分配的CUDA 数组:
CUDA_MEMCPY2D copyParam;
memset(©Param, 0, sizeof(copyParam));
copyParam.dstMemoryType = CU_MEMORYTYPE_ARRAY;
copyParam.dstArray = cuArray;
copyParam.srcMemoryType = CU_MEMORYTYPE_DEVICE;
copyParam.srcDevice = devPtr;
copyParam.srcPitch = pitch;
copyParam.WidthInBytes = width * sizeof(float);
copyParam.Height = height;
cuMemcpy2D(©Param);
下面的代码演示,拷贝一些主机内存数组到设备内存:
float data[256];
int size = sizeof(data);
CUdeviceptr devPtr;
cuMemMalloc(&devPtr, size);
cuMemcpyHtoD(devPtr, data, size);
[流管理]
调用函数用来创建和销毁流,并且判定一个流中的所有操作是否完成
下面的代码演示,创建两个流:
CUStream stream[2];
for (int i = 0; i < 2; ++i)
cuStreamCreate(&stream[i], 0);
下面的代码演示,每一个流被依次定义执行一次:从主机到设备的内存拷贝,kernel 启动,从设备到主机的内存拷贝
for (int i = 0; i < 2; ++i)
cuMemcpyHtoDAsync(inputDevPtr + i * size, hostPtr + i * size, size, stream[i]);
for (int i = 0; i < 2; ++i) {
cuFuncSetBlockShape(cuFunction, 512, 1, 1);
int offset = 0;
cuParamSeti(cuFunction, offset, outputDevPtr);
offset += sizeof(int);
cuParamSeti(cuFunction, offset, inputDevPtr);
offset += sizeof(int);
cuParamSeti(cuFunction, offset, size);
offset += sizeof(int);
cuParamSetSize(cuFunction, offset);
}
cuLaunchGridAsync(cuFunction, 100, 1, stream[i]
for (int i = 0; i < 2; ++i)
cuMemcpyDtoHAsync(hostPtr + i * size, outputDevPtr + i * size,
size, stream[i]);
cuCtxSynchronize();
每个流拷贝部分输入数组hostPtr 到设备内存中的输入数组inputDevPtr,通过调用cuFunction 在设备上处理inputDevPtr, 并拷贝结果outputDevPtr 到hostPtr 的同一个部分。
使用两个流处理hostPtr 允许内存拷贝从一个流覆盖到另一个流
对于任何覆盖,hostPtr 必须指向page-locked 的主机内存:
float* hostPtr;
cuMemMallocHost((void**)&hostPtr, 2 * size);
cuCtxSynchronize()在最后被调用,以确保在继续处理之前全部的流已经完成
[事件管理]
调用函数用来创建,纪录和销毁事件,并可查询两个事件之间花费的时间
下面的代码演示,建立两个事件
CUEvent start,
stop;cuEventCreate(&start);
cuEventCreate(&stop);
这些事件可以用来计算之前代码的时间:
cuEventRecord(start, 0);
for (int i = 0; i < 2; ++i)
cuMemcpyHtoDAsync(inputDevPtr + i * size, hostPtr + i * size, size, stream[i]);
for (int i = 0; i < 2; ++i) {
cuFuncSetBlockShape(cuFunction, 512, 1, 1);
int offset = 0;
cuParamSeti(cuFunction, offset, outputDevPtr);
offset += sizeof(int);
cuParamSeti(cuFunction, offset, inputDevPtr);
offset += sizeof(int);
cuParamSeti(cuFunction, offset, size);
offset += sizeof(int);
cuParamSetSize(cuFunction, offset);
}
cuLaunchGridAsync(cuFunction, 100, 1, stream[i]
for (int i = 0; i < 2; ++i)
cuMemcpyDtoHAsync(hostPtr + i * size, outputDevPtr + i * size, size, stream[i]);
cuEventRecord(stop, 0);
cuEventSynchronize(stop);
float elapsedTime;
cuEventElapsedTime(&elapsedTime, start, stop);
[Texture Reference 管理]
调用函数用来管理texture reference
在一个kernel 通过texture reference 读取纹理内存之前,texture reference 必须绑定到一个cuTexRefSetAddress()或cuTexRefSetArray()的纹理中使用。
如果一个模块cuModule 中包含一些texture reference texRef 定义为texture<float, 2, cudaReadModeElementType> texRef;
下面的代码演示,获得texRef 的句柄:
CUtexref cuTexRef;
cuModuleGetTexRef(&cuTexRef, cuModule, “texRef”);
下面的代码演示,绑定一个texture reference 到通过devPtr 指向的线性内存中:
cuTexRefSetAddress(Null, cuTexRef, devPtr, size);
下面的代码演示,绑定一个texture reference 到CUDA 数组cuArray 中:
cuTexRefSetArray(cuTexRef, cuArrary, CU_TRSA_OVERRIDE_FORMAT);
设定texture reference 的寻址模式,过滤模式,格式,和其他标志
绑定一个纹理到texture reference 的格式必须匹配声明texture reference 时的参数;
否则,纹理拾取的结果将是未定义的
[OpenGL Interoperability]
调用函数用来控制OpenGL 的互用性
OpenGL 的互用性必须通过cuGLInit()来初始化
一个缓冲对象在被映射之前必须注册到CUDA
使用cuGLRegisterBufferObject():
GLuint bufferObj;
cuGLRegisterBufferObject(bufferObj);
注册以后,缓冲对象可以通过kenrel 使用设备内存读取或写入,内存设备的地址通过cuGLMapBufferObject()返回:
GLuint bufferObj;
CUdeviceptr devPtr;
Int size;
cuGLMapBufferObject(&devPtr, &size, bufferObj);
卸载映射和注册通过,cuGLUnmapBufferObject()和cuGLUnregisterBufferObject()
[Direct3D Interoperability]
调用函数用来控制Direct3D 的互用性
Direct3D 的互用性必须通过cuD3D9Begin()来初始化,cuD3D9End()来终止
一个顶点对象在被映射之前必须注册到CUDA使用cuD3D9RegisterVertexBuffer()
LPDIRECT3DVERTEXBUFFER9 vertexBuffer;
cuD3D9RegisterVertexBuffer(vertexBuffer);
注册以后,缓冲对象可以通过kenrel 使用设备内存读取或写入,内存设备的地址通过cuD3D9MapVertexBuffer()返回:
LPDIRECT3DVERTEXBUFFER9 vertexBuffer;
CUdeviceptr devPtr;
Int size;
cuD3D9MapVertexBuffer(&devPtr, &size, vertexBuffer);
卸载映射和注册通过,cuD3D9UnmapVertexBuffer()和cuD3D9UnregisterVertexBuffer()


![SQLSTATE[IMSSP]: The active result for the query contains no fields.](https://img-blog.csdnimg.cn/22ba99764be64a78a995121483b816b5.png)


![python3/pip3 SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed](https://img-blog.csdnimg.cn/dd1bf75284594006b3e610989f44f6f9.png)




![[好书推荐] 之 <趣化计算机底层技术>](https://img-blog.csdnimg.cn/36f3f754ed084f12b12277eb844b69fb.gif)
