原文:https://automatetheboringstuff.com/2e/chapter16/

在第 15 章,你学习了如何从 PDF 和 Word 文档中提取文本。这些文件是二进制格式的,需要特殊的 Python 模块来访问它们的数据。另一方面,CSV 和 JSON 文件只是纯文本文件。您可以在文本编辑器(如 Mu)中查看它们。但是 Python 还附带了特殊的csv和json模块,每个模块都提供了帮助您处理这些文件格式的函数。
CSV 代表“逗号分隔值”,CSV 文件是存储为纯文本文件的简化电子表格。Python 的csv模块使得解析 CSV 文件变得很容易。
JSON(读作“JAY-saw”或“Jason”——怎么读并不重要,因为人们会说你读错了)是一种将信息作为 JavaScript 源代码存储在纯文本文件中的格式。(JSON 是 JavaScript 对象符号的缩写。)使用 JSON 文件不需要了解 JavaScript 编程语言,但是了解 JSON 格式很有用,因为它在许多 Web 应用中使用。
CSV 模块
CSV 文件中的每一行代表电子表格中的一行,行中的单元格用逗号分隔。例如,的电子表格example.xlsx在一个 CSV 文件中会是这样的:
4/5/2015 13:34,Apples,73
4/5/2015 3:41,Cherries,85
4/6/2015 12:46,Pears,14
4/8/2015 8:59,Oranges,52
4/10/2015 2:07,Apples,152
4/10/2015 18:10,Bananas,23
4/10/2015 2:40,Strawberries,98
我将在本章的交互式 Shell 示例中使用这个文件。您可以从下载example.csv或者在文本编辑器中输入文本并保存为example.csv。
CSV 文件很简单,缺少 Excel 电子表格的许多功能。例如,CSV 文件:
- 它们的值没有类型——一切都是字符串
- 没有字体大小或颜色的设置
- 没有多个工作表
- 无法指定单元格的宽度和高度
- 不能有合并单元格
- 不能嵌入图像或图表
CSV 文件的优点是简单。CSV 文件被许多类型的程序广泛支持,可以在文本编辑器(包括 Mu)中查看,并且是表示电子表格数据的一种直接方式。CSV 格式与广告中的完全一样:它只是一个由逗号分隔的值组成的文本文件。
由于 CSV 文件只是文本文件,您可能会尝试将它们作为字符串读入,然后使用您在第 9 章中学到的技术处理该字符串。例如,由于 CSV 文件中的每个单元格都由逗号分隔,所以您可以在每行文本上调用split(',')来获取逗号分隔的值作为字符串列表。但并不是 CSV 文件中的每个逗号都代表两个单元格之间的边界。CSV 文件也有自己的转义字符集,允许逗号和其他字符作为值的一部分包含在其中。split()方法不处理这些转义字符。因为这些潜在的陷阱,你应该总是使用csv模块来读写 CSV 文件。
reader对象
要用csv模块从 CSV 文件中读取数据,您需要创建一个reader对象。一个reader对象让你遍历 CSV 文件中的行。在交互 Shell 中输入以下内容,当前工作目录中有example.csv :
>>> import csv # ➊
>>> exampleFile = open('example.csv') # ➋
>>> exampleReader = csv.reader(exampleFile) # ➌
>>> exampleData = list(exampleReader) # ➍
>>> exampleData # ➎
[['4/5/2015 13:34', 'Apples', '73'], ['4/5/2015 3:41', 'Cherries', '85'],
['4/6/2015 12:46', 'Pears', '14'], ['4/8/2015 8:59', 'Oranges', '52'],
['4/10/2015 2:07', 'Apples', '152'], ['4/10/2015 18:10', 'Bananas', '23'],
['4/10/2015 2:40', 'Strawberries', '98']]
Python 自带了csv模块,所以我们可以导入它 ➊ 而不必先安装它。
要使用csv模块读取一个 CSV 文件,首先使用open()函数 ➋ 打开它,就像您处理任何其他文本文件一样。但不是在open()返回的File对象上调用read()或readlines()方法,而是将其传递给csv.reader()函数 ➌。这将返回一个reader对象供您使用。注意,您没有将文件名字符串直接传递给csv.reader()函数。
访问reader对象中的值的最直接的方法是通过将它传递给list()➍ 来将其转换成普通的 Python 列表。在这个reader对象上使用list()会返回一个列表列表,您可以将它存储在一个类似exampleData的变量中。在 Shell 中输入exampleData显示列表列表 ➎。
现在您已经将 CSV 文件作为一个列表列表,您可以使用表达式exampleData[row][col]访问特定行和列的值,其中row是exampleData中一个列表的索引,col是您希望从该列表中获得的项目的索引。在交互式 Shell 中输入以下内容:
>>> exampleData[0][0]
'4/5/2015 13:34'
>>> exampleData[0][1]
'Apples'
>>> exampleData[0][2]
'73'
>>> exampleData[1][1]
'Cherries'
>>> exampleData[6][1]
'Strawberries'
从输出中可以看到,exampleData[0][0]进入第一个列表并给出第一个字符串,exampleData[0][2]进入第一个列表并给出第三个字符串,依此类推。
在for循环中从reader对象中读取数据
对于大的 CSV 文件,您将希望在一个for循环中使用reader对象。这避免了一次将整个文件加载到内存中。例如,在交互式 Shell 中输入以下内容:
>>> import csv
>>> exampleFile = open('example.csv')
>>> exampleReader = csv.reader(exampleFile)
>>> for row in exampleReader:
print('Row #' + str(exampleReader.line_num) + ' ' + str(row))
Row #1 ['4/5/2015 13:34', 'Apples', '73']
Row #2 ['4/5/2015 3:41', 'Cherries', '85']
Row #3 ['4/6/2015 12:46', 'Pears', '14']
Row #4 ['4/8/2015 8:59', 'Oranges', '52']
Row #5 ['4/10/2015 2:07', 'Apples', '152']
Row #6 ['4/10/2015 18:10', 'Bananas', '23']
Row #7 ['4/10/2015 2:40', 'Strawberries', '98']
在您导入了csv模块并从 CSV 文件中创建了一个reader对象之后,您可以遍历reader对象中的行。每行是一个值列表,每个值代表一个单元格。
print()函数调用打印当前行的编号和该行的内容。要获得行号,使用reader对象的line_num变量,它包含当前行的行号。
reader对象只能循环一次。要重新读取 CSV 文件,您必须调用csv.reader来创建一个reader对象。
writer对象
一个writer对象允许你将数据写入一个 CSV 文件。要创建一个writer对象,可以使用csv.writer()函数。在交互式 Shell 中输入以下内容:
>>> import csv
>>> outputFile = open('output.csv', 'w', newline='') # ➊
>>> outputWriter = csv.writer(outputFile) # ➋
>>> outputWriter.writerow(['spam', 'eggs', 'bacon', 'ham'])
21
>>> outputWriter.writerow(['Hello, world!', 'eggs', 'bacon', 'ham'])
32
>>> outputWriter.writerow([1, 2, 3.141592, 4])
16
>>> outputFile.close()
首先调用open()并传递'w'以写模式打开一个文件 ➊。这将创建一个对象,然后你可以传递给csv.writer()➋ 来创建一个writer对象。
在 Windows 上,您还需要为open()函数的newline关键字参数传递一个空字符串。由于超出本书范围的技术原因,如果你忘记设置newline参数,那么output.csv中的行将是双倍行距,如图图 16-1 所示。
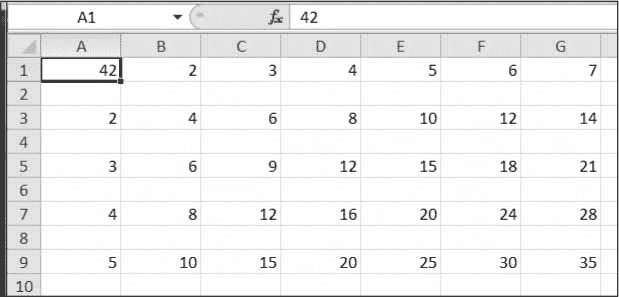
图 16-1:如果你忘记了open()中的newline=''关键字参数,CSV 文件将会是双倍行距。
writer对象的writerow()方法接受一个列表参数。列表中的每个值都放在输出 CSV 文件中自己的单元格中。writerow()的返回值是写入文件中该行的字符数(包括换行符)。
这段代码生成一个类似于下面的output.csv文件:
spam,eggs,bacon,ham
"Hello, world!",eggs,bacon,ham
1,2,3.141592,4
注意在 CSV 文件中,writer对象是如何用双引号自动转义值'Hello, world!'中的逗号的。csv模块让您不必亲自处理这些特殊情况。
delimiter和lineterminator关键字参数
假设您希望用制表符而不是逗号来分隔单元格,并且希望行是双倍行距。您可以在交互式 Shell 中输入如下内容:
>>> import csv
>>> csvFile = open('example.tsv', 'w', newline='')
>>> csvWriter = csv.writer(csvFile, delimiter='\t', lineterminator='\n\n') # ➊
>>> csvWriter.writerow(['apples', 'oranges', 'grapes'])
24
>>> csvWriter.writerow(['eggs', 'bacon', 'ham'])
17
>>> csvWriter.writerow(['spam', 'spam', 'spam', 'spam', 'spam', 'spam'])
32
>>> csvFile.close()
这将更改文件中的分隔符和行结束符。分隔符是出现在一行单元格之间的字符。默认情况下,CSV 文件的分隔符是逗号。行结束符是出现在一行末尾的字符。默认情况下,行结束符是换行符。您可以通过使用带有csv.writer()的delimiter和lineterminator关键字参数将字符更改为不同的值。
传递delimiter='\t'和lineterminator='\n\n'➊ 将单元格之间的字符更改为制表符,将行之间的字符更改为两个换行符。然后我们调用writerow()三次,得到三行。
这将生成一个名为example.tsv的文件,其内容如下:
apples oranges grapes
eggs bacon ham
spam spam spam spam spam spam
现在我们的单元格由制表符分隔,我们使用文件扩展名tsv,用于制表符分隔的值。
DictReader和DictWriter CSV 对象
对于包含标题行的 CSV 文件,使用DictReader和DictWriter对象通常比使用reader和writer对象更方便。
reader和writer对象通过使用列表读写 CSV 文件行。DictReader和DictWriter CSV 对象执行相同的功能,但是使用字典,它们使用 CSV 文件的第一行作为这些字典的键。
前往下载exampleWithHeader.csv文件。这个文件与example.csv相同,除了它在第一行中有时间戳、水果和数量作为列标题。
要读取该文件,请在交互式 Shell 中输入以下内容:
>>> import csv
>>> exampleFile = open('exampleWithHeader.csv')
>>> exampleDictReader = csv.DictReader(exampleFile)
>>> for row in exampleDictReader:
... print(row['Timestamp'], row['Fruit'], row['Quantity'])
...
4/5/2015 13:34 Apples 73
4/5/2015 3:41 Cherries 85
4/6/2015 12:46 Pears 14
4/8/2015 8:59 Oranges 52
4/10/2015 2:07 Apples 152
4/10/2015 18:10 Bananas 23
4/10/2015 2:40 Strawberries 98
在循环内部,DictReader object 将row设置为一个字典对象,其键来自第一行的标题。(嗯,从技术上来说,它将row设置为一个OrderedDict对象,你可以像使用字典一样使用它;它们之间的区别超出了本书的范围。)使用一个DictReader对象意味着你不需要额外的代码来跳过第一行的标题信息,因为DictReader对象为你做了这件事。
如果您试图将DictReader对象与第一行没有列标题的example.csv一起使用,DictReader对象将使用'4/5/2015 13:34'、'Apples'和'73'作为字典键。为了避免这种情况,您可以为DictReader()函数提供第二个参数,其中包含虚构的头名称:
>>> import csv
>>> exampleFile = open('example.csv')
>>> exampleDictReader = csv.DictReader(exampleFile, ['time', 'name',
'amount'])
>>> for row in exampleDictReader:
... print(row['time'], row['name'], row['amount'])
...
4/5/2015 13:34 Apples 73
4/5/2015 3:41 Cherries 85
4/6/2015 12:46 Pears 14
4/8/2015 8:59 Oranges 52
4/10/2015 2:07 Apples 152
4/10/2015 18:10 Bananas 23
4/10/2015 2:40 Strawberries 98
因为example.csv的第一行没有任何用于每列标题的文本,所以我们创建了自己的:'time'、'name'和'amount'。
DictWriter对象使用字典创建 CSV 文件。
>>> import csv
>>> outputFile = open('output.csv', 'w', newline='')
>>> outputDictWriter = csv.DictWriter(outputFile, ['Name', 'Pet', 'Phone'])
>>> outputDictWriter.writeheader()
>>> outputDictWriter.writerow({'Name': 'Alice', 'Pet': 'cat', 'Phone': '555-
1234'})
20
>>> outputDictWriter.writerow({'Name': 'Bob', 'Phone': '555-9999'})
15
>>> outputDictWriter.writerow({'Phone': '555-5555', 'Name': 'Carol', 'Pet':
'dog'})
20
>>> outputFile.close()
如果您希望您的文件包含一个标题行,通过调用writeheader()来编写该行。否则,跳过调用writeheader()从文件中省略一个标题行。然后用一个writerow()方法调用写入 CSV 文件的每一行,传递一个字典,该字典使用文件头作为键,包含要写入文件的数据。
这段代码创建的output.csv文件如下所示:
Name,Pet,Phone
Alice,cat,555-1234
Bob,,555-9999
Carol,dog,555-5555
注意,你传递给writerow()的字典中键-值对的顺序并不重要:它们是按照给DictWriter()的键的顺序编写的。例如,即使您在第四行的Name和Pet键和值之前传递了Phone键和值,电话号码仍然出现在输出的最后。
还要注意,任何丢失的键,比如{'Name': 'Bob', 'Phone': '555-9999'}中的'Pet',在 CSV 文件中都会是空的。
项目:从 CSV 文件中移除文件头
假设您有一份从数百个 CSV 文件中删除第一行的枯燥工作。也许您会将它们输入到一个自动化的流程中,该流程只需要数据,而不需要列顶部的标题。你可以在 Excel 中打开每个文件,删除第一行,然后重新保存文件——但这需要几个小时。让我们写一个程序来代替它。
该程序将需要打开当前工作目录下每个csv扩展名的文件,读入 CSV 文件的内容,将没有第一行的内容重写到同名文件中。这将用新的无头内容替换 CSV 文件的旧内容。
警告
和往常一样,每当你编写一个修改文件的程序时,一定要先备份这些文件,以防你的程序不按你期望的方式运行。你不想意外删除你的原始文件。
在高层次上,程序必须做到以下几点:
- 在当前工作目录中查找所有 CSV 文件。
- 读入每个文件的全部内容。
- 跳过第一行,将内容写入一个新的 CSV 文件。
在代码级别,这意味着程序需要做以下事情:
- 从
os.listdir()开始循环文件列表,跳过非 CSV 文件。 - 创建一个 CSV
reader对象并读入文件的内容,使用line_num属性来决定跳过哪一行。 - 创建一个 CSV
writer对象并将读入的数据写出到新文件中。
对于这个项目,打开一个新的文件编辑器窗口,保存为removeCsvHeader.py。
第一步:遍历每个 CSV 文件
您的程序需要做的第一件事是遍历当前工作目录的所有 CSV 文件名的列表。让您的removeCsvHeader.py看起来像这样:
#! python3
# removeCsvHeader.py - Removes the header from all CSV files in the current
# working directory.
import csv, os
os.makedirs('headerRemoved', exist_ok=True)
# Loop through every file in the current working directory.
for csvFilename in os.listdir('.'):
if not csvFilename.endswith('.csv'):
continue # skip non-csv files # ➊
print('Removing header from ' + csvFilename + '...')
# TODO: Read the CSV file in (skipping first row).
# TODO: Write out the CSV file.
调用os.makedirs()将创建一个headerRemoved文件夹,所有的无头 CSV 文件将被写入其中。在os.listdir('.')上的一个for循环可以让你完成一部分,但是它会遍历工作目录中的所有文件,所以你需要在循环的开始添加一些代码,跳过不以.csv结尾的文件名。当遇到非 CSV 文件时,continue语句 ➊ 使for循环移动到下一个文件名。
程序运行时会有一些输出,打印出一条消息,说明程序正在处理哪个 CSV 文件。然后,添加一些关于程序其余部分应该做什么的TODO注释。
第二步:读入 CSV 文件
程序不会删除 CSV 文件的第一行。相反,它创建一个没有第一行的 CSV 文件的新副本。由于副本的文件名与原始文件名相同,副本将覆盖原始文件名。
程序需要一种方法来跟踪它当前是否在第一行循环。将以下内容添加到removeCsvHeader.py中。
#! python3
# removeCsvHeader.py - Removes the header from all CSV files in the current
# working directory.
--snip--
# Read the CSV file in (skipping first row).
csvRows = []
csvFileObj = open(csvFilename)
readerObj = csv.reader(csvFileObj)
for row in readerObj:
if readerObj.line_num == 1:
continue # skip first row
csvRows.append(row)
csvFileObj.close()
# TODO: Write out the CSV file.
reader对象的line_num属性可用于确定它当前正在读取 CSV 文件中的哪一行。另一个for循环将遍历从 CSV reader对象返回的行,除了第一行之外的所有行将被附加到csvRows。
当for循环遍历每一行时,代码检查readerObj.line_num是否被设置为1。如果是,它执行一个continue来移动到下一行,而不把它附加到csvRows。对于之后的每一行,条件将始终为False,并且该行将被附加到csvRows。
第三步:写出没有第一行的 CSV 文件
现在csvRows包含了除第一行之外的所有行,这个列表需要写到headerRemoved文件夹中的一个 CSV 文件中。将以下内容添加到removeCsvHeader.py :
#! python3
# removeCsvHeader.py - Removes the header from all CSV files in the current
# working directory.
--snip--
# Loop through every file in the current working directory.
for csvFilename in os.listdir('.'): # ➊
if not csvFilename.endswith('.csv'):
continue # skip non-CSV files
--snip--
# Write out the CSV file.
csvFileObj = open(os.path.join('headerRemoved', csvFilename), 'w',
newline='')
csvWriter = csv.writer(csvFileObj)
for row in csvRows:
csvWriter.writerow(row)
csvFileObj.close()
CSV writer对象将使用csvFilename(我们在 CSV 读取器中也使用了它)将列表写入到headerRemoved中的 CSV 文件中。这将覆盖原始文件。
一旦我们创建了writer对象,我们就遍历存储在csvRows中的子列表,并将每个子列表写入文件。
代码执行后,外层for循环 ➊ 将从os.listdir('.')开始循环到下一个文件名。当这个循环结束时,程序就完成了。
为了测试你的程序,从nostarch.com/automatestuff2下载removeCsvHeader.zip并解压到一个文件夹中。运行该文件夹中的removeCsvHeader.py程序。输出将如下所示:
Removing header from NAICS_data_1048.csv...
Removing header from NAICS_data_1218.csv...
--snip--
Removing header from NAICS_data_9834.csv...
Removing header from NAICS_data_9986.csv...
这个程序应该在每次从 CSV 文件中删除第一行时打印一个文件名。
类似程序的创意
您可以为 CSV 文件编写的程序类似于您可以为 Excel 文件编写的程序,因为它们都是电子表格文件。您可以编写程序来完成以下任务:
- 比较一个 CSV 文件中不同行之间或多个 CSV 文件之间的数据。
- 将特定数据从 CSV 文件复制到 Excel 文件,反之亦然。
- 检查 CSV 文件中的无效数据或格式错误,并提醒用户注意这些错误。
- 从 CSV 文件中读取数据作为 Python 程序的输入。
JSON 和 API
JavaScript 对象符号是将数据格式化为单个人类可读字符串的一种流行方式。JSON 是 JavaScript 程序编写数据结构的原生方式,通常类似于 Python 的pprint()函数会产生的结果。为了处理 JSON 格式的数据,您不需要了解 JavaScript。
下面是一个格式化为 JSON 的数据示例:
{"name": "Zophie", "isCat": true,
"miceCaught": 0, "napsTaken": 37.5,
"felineIQ": null}
了解 JSON 是很有用的,因为许多网站提供 JSON 内容作为程序与网站交互的一种方式。这被称为提供应用编程接口(API) 。访问 API 与通过 URL 访问任何其他网页是一样的。区别在于 API 返回的数据是为机器格式化的(例如用 JSON );API 不容易让人读懂。
许多网站以 JSON 格式提供数据。Data.gov、推特、雅虎、谷歌、Tumblr、维基百科、Flickr、Reddit、IMDb、烂番茄、LinkedIn 和许多其他流行的网站都提供 API 供程序使用。其中一些网站需要注册,而注册几乎总是免费的。为了获得想要的数据,您必须找到程序需要请求哪些 URL 的文档,以及返回的 JSON 数据结构的一般格式。这个文档应该由提供 API 的任何站点提供;如果他们有一个“开发者”页面,在那里寻找文档。
使用 API,您可以编写执行以下操作的程序:
- 从网站上搜集原始数据。(访问 API 往往比下载网页和用 BeautifulSoup 解析 HTML 更方便。)
- 自动从您的一个社交网络帐户下载新帖子,并将其发布到另一个帐户。例如,你可以把你的 Tumblr 帖子发到脸书。
- 从 IMDb、烂番茄和维基百科中提取数据,放入你电脑上的一个文本文件中,为你的个人电影收藏创建一个“电影百科全书”。
您可以在参考资料中的看到一些 JSON APIs 的例子。
JSON 并不是将数据格式化为可读字符串的唯一方法。还有许多其他格式,包括 XML(可扩展标记语言)、TOML (Tom 的显而易见的最小化语言)、YML(另一种标记语言)、INI(初始化),甚至是过时的 ASN.1(抽象语法符号一)格式,所有这些都提供了一种将数据表示为人类可读文本的结构。本书不会涉及这些,因为 JSON 已经迅速成为使用最广泛的替代格式,但是有第三方 Python 模块可以轻松处理它们。
json模块
Python 的json模块为json.loads()和json.dumps()函数处理带有 JSON 数据的字符串和 Python 值之间转换的所有细节。JSON 不能存储每一种 Python 值。它只能包含以下数据类型的值:字符串、整数、浮点、布尔、列表、字典和NoneType。JSON 不能表示特定于 Python 的对象,比如File对象、CSV reader或writer对象、Regex对象或 Selenium WebElement对象。
用loads()函数读取 JSON
要将包含 JSON 数据的字符串转换成 Python 值,请将其传递给json.loads()函数。(该名称的意思是“加载字符串”,而不是“加载”)在交互式 Shell 中输入以下内容:
>>> stringOfJsonData = '{"name": "Zophie", "isCat": true, "miceCaught": 0,
"felineIQ": null}'
>>> import json
>>> jsonDataAsPythonValue = json.loads(stringOfJsonData)
>>> jsonDataAsPythonValue
{'isCat': True, 'miceCaught': 0, 'name': 'Zophie', 'felineIQ': None}
导入json模块后,可以调用loads()并向其传递一串 JSON 数据。注意,JSON 字符串总是使用双引号。它将以 Python 字典的形式返回数据。Python 字典不是按顺序排列的,所以在打印jsonDataAsPythonValue时,键值对可能会以不同的顺序出现。
编写 JSON 与dumps()函数
json.dumps()函数(意思是“转储字符串”,而不是“转储”)将把 Python 值转换成 JSON 格式的数据字符串。在交互式 Shell 中输入以下内容:
>>> pythonValue = {'isCat': True, 'miceCaught': 0, 'name': 'Zophie',
'felineIQ': None}
>>> import json
>>> stringOfJsonData = json.dumps(pythonValue)
>>> stringOfJsonData
'{"isCat": true, "felineIQ": null, "miceCaught": 0, "name": "Zophie" }'
该值只能是以下基本 Python 数据类型之一:字典、列表、整数、浮点、字符串、布尔或None。
项目:获取当前天气数据
查看天气似乎很简单:打开你的网络浏览器,点击地址栏,输入一个天气网站的 URL(或者搜索一个然后点击链接),等待页面加载,浏览所有的广告,等等。
实际上,如果你有一个程序可以下载未来几天的天气预报并以纯文本格式打印出来,那么你可以跳过很多无聊的步骤。这个程序使用第 12 章中的requests模块从网上下载数据。
总的来说,该程序完成了以下工作:
- 从命令行读取请求的位置
- 从 OpenWeatherMap.org 下载 JSON 天气数据
- 将 JSON 数据的字符串转换为 Python 数据结构
- 打印今天和未来两天的天气
因此,代码需要执行以下操作:
- 连接
sys.argv中的字符串以获得位置。 - 调用
requests.get()下载天气数据。 - 调用
json.loads()将 JSON 数据转换成 Python 数据结构。 - 打印天气预报。
对于这个项目,打开一个新的文件编辑器窗口,并将其保存为getOpenWeather.py。然后在你的浏览器中访问openweathermap.org/api并注册一个免费帐户,以获得一个 API 密钥,也称为应用 ID,对于 OpenWeatherMap 服务来说,它是一个类似于'30144aba38018987d84710d0e319281e'的字符串代码。除非你计划每分钟进行 60 次以上的 API 调用,否则你不需要为这项服务付费。对 API 密钥保密;任何知道它的人都可以编写使用您帐户的使用配额的脚本。
第一步:从命令行参数获取位置
这个程序的输入将来自命令行。使getOpenWeather.py看起来像这样:
#! python3
# getOpenWeather.py - Prints the weather for a location from the command line.
APPID = 'YOUR_APPID_HERE'
import json, requests, sys
# Compute location from command line arguments.
if len(sys.argv) < 2:
print('Usage: getOpenWeather.py city_name, 2-letter_country_code')
sys.exit()
location = ' '.join(sys.argv[1:])
# TODO: Download the JSON data from OpenWeatherMap.org's API.
# TODO: Load JSON data into a Python variable.
在 Python 中,命令行参数存储在sys.argv列表中。APPID变量应该设置为您的帐户的 API 密钥。没有这个密钥,您对天气服务的请求将会失败。在#! shebang 行和import语句之后,程序将检查是否有多个命令行参数。(回想一下,sys.argv总是至少有一个元素sys.argv[0],它包含 Python 脚本的文件名。)如果列表中只有一个元素,那么用户没有在命令行上提供位置,并且在程序结束之前将向用户提供“用法”消息。
OpenWeatherMap 服务要求查询格式为城市名、逗号和两个字母的国家代码(如“US”代表美国)。你可以在en.wikipedia.org/wiki/ISO_3166-1_alpha-2找到这些代码的列表。我们的脚本显示检索到的 JSON 文本中列出的第一个城市的天气。不幸的是,同名的城市,如俄勒冈州的波特兰和缅因州的波特兰,都将被包括在内,尽管 JSON 文本将包括经度和纬度信息以区分这两个城市。
命令行参数按空格拆分。命令行参数San Francisco, US将使sys.argv保持['getOpenWeather.py', 'San', 'Francisco,', 'US']。因此,调用join()方法来连接除了sys.argv中第一个以外的所有字符串。将这个连接的字符串存储在一个名为location的变量中。
第二步:下载 JSON 数据
OpenWeatherMap.org以 JSON 格式提供实时天气信息。首先你必须在网站上注册一个免费的 API 密匙。(此键用于限制您在他们的服务器上发出请求的频率,以降低他们的带宽成本。)您的程序只需下载位于api.openweathermap.org/data/2.5/forecast/daily?q=<LOC>&cnt=3&appid=<APIkey>的页面,其中位置<LOC>是您想要了解其天气的城市名称,<APIkey>是您的个人 API key。将以下内容添加到getOpenWeather.py中。
#! python3
# getOpenWeather.py - Prints the weather for a location from the command line.
--snip--
# Download the JSON data from OpenWeatherMap.org's API.
url ='https://api.openweathermap.org/data/2.5/forecast/daily?q=%s&cnt=3&APPID=%s ' % (location,
APPID)
response = requests.get(url)
response.raise_for_status()
# Uncomment to see the raw JSON text:
#print(response.text)
# TODO: Load JSON data into a Python variable.
我们从命令行参数中得到location。为了创建我们想要访问的 URL,我们使用了%s占位符,并将存储在location中的任何字符串插入到 URL 字符串中的那个位置。我们将结果存储在url中,并将url传递给requests.get()。requests.get()调用返回一个Response对象,您可以通过调用raise_for_status()来检查它的错误。如果没有出现异常,下载的文本将在response.text中。
第三步:加载 JSON 数据并打印天气
response.text成员变量保存一大串 JSON 格式的数据。要将其转换为 Python 值,请调用json.loads()函数。JSON 数据将如下所示:
{'city': {'coord': {'lat': 37.7771, 'lon': -122.42},
'country': 'United States of America',
'id': '5391959',
'name': 'San Francisco',
'population': 0},
'cnt': 3,
'cod': '200',
'list': [{'clouds': 0,
'deg': 233,
'dt': 1402344000,
'humidity': 58,
'pressure': 1012.23,
'speed': 1.96,
'temp': {'day': 302.29,
'eve': 296.46,
'max': 302.29,
'min': 289.77,
'morn': 294.59,
'night': 289.77},
'weather': [{'description': 'sky is clear',
'icon': '01d',
--snip--
您可以通过将weatherData传递给pprint.pprint()来查看这些数据。你可能想查看openweathermap.org以获得更多关于这些字段含义的文档。例如,在线文档会告诉你'day'后的302.29是白天的开尔文温度,而不是摄氏度或华氏度。
你要的天气描述在'main'和'description'之后。为了整齐地打印出来,将以下内容添加到getOpenWeather.py中。
! python3
# getOpenWeather.py - Prints the weather for a location from the command line.
--snip--
# Load JSON data into a Python variable.
weatherData = json.loads(response.text)
# Print weather descriptions.
w = weatherData['list'] # ➊
print('Current weather in %s:' % (location))
print(w[0]['weather'][0]['main'], '-', w[0]['weather'][0]['description'])
print()
print('Tomorrow:')
print(w[1]['weather'][0]['main'], '-', w[1]['weather'][0]['description'])
print()
print('Day after tomorrow:')
print(w[2]['weather'][0]['main'], '-', w[2]['weather'][0]['description'])
请注意代码是如何将weatherData['list']存储在变量w中的,以节省您键入 ➊ 的时间。您使用w[0]、w[1]和w[2]分别检索今天、明天和后天天气的字典。每个字典都有一个'weather'键,其中包含一个列表值。您感兴趣的是第一个列表项,它是一个嵌套字典,在索引 0 处还有几个键。这里,我们打印存储在'main'和'description'键中的值,用连字符分隔。
当使用命令行参数getOpenWeather.py San Francisco, CA运行该程序时,输出如下所示:
Current weather in San Francisco, CA:
Clear - sky is clear
Tomorrow:
Clouds - few clouds
Day after tomorrow:
Clear - sky is clear
(天气是我喜欢住在旧金山的原因之一!)
类似程序的创意
访问天气数据可以构成许多类型程序的基础。您可以创建类似的程序来执行以下操作:
- 收集几个露营地或徒步旅行路线的天气预报,看看哪个会有最好的天气。
- 制定一个计划,定期检查天气,如果你需要将植物移到室内,会给你发送霜冻警告。(第 17 章讲述日程安排,第 18 章解释如何发送电子邮件。)
- 从多个站点获取天气数据并一次显示,或者计算并显示多个天气预测的平均值。
总结
CSV 和 JSON 是存储数据的常见纯文本格式。它们很容易被程序解析,同时仍然是人类可读的,所以它们通常用于简单的电子表格或 Web 应用数据。csv和json模块大大简化了 CSV 和 JSON 文件的读写过程。
前几章已经教你如何使用 Python 来解析各种文件格式的信息。一个常见的任务是从各种格式中提取数据,并对其进行解析以获得您需要的特定信息。这些任务通常特定于商业软件没有最佳帮助的情况。通过编写自己的脚本,您可以让计算机处理以这些格式渲染的大量数据。
在第 18 章中,你将脱离数据格式,学习如何让你的程序通过发送电子邮件和文本信息与你交流。
练习题
-
Excel 电子表格有哪些 CSV 电子表格没有的功能?
-
你传递给
csv.reader()和csv.writer()什么来创建reader和writer对象? -
reader和writer对象的File对象需要在什么模式下打开? -
什么方法获取列表参数并将其写入 CSV 文件?
-
delimiter和lineterminator关键字参数是做什么的? -
什么函数接受一串 JSON 数据并返回一个 Python 数据结构?
-
哪个函数采用 Python 数据结构并返回一串 JSON 数据?
实践项目
为了练习,编写一个程序来完成以下任务。
Excel 到 CSV 转换器
Excel 只需点击几下鼠标就可以将电子表格保存为 CSV 文件,但是如果您必须将数百个 Excel 文件转换为 CSV 文件,则需要花费数小时的点击时间。使用第十二章的中的openpyxl模块,编写一个程序,读取当前工作目录中的所有 Excel 文件,并将其输出为 CSV 文件。
一个 Excel 文件可能包含多个工作表;您必须为每张工作表创建一个 CSV 文件。CSV 文件的文件名应为<excel_file_name>_<worksheet_title>.csv,其中<excel_file_name>是不带文件扩展名的 Excel 文件的文件名(例如,'spam_data',而不是'spam_data.xlsx'),<worksheet_title>是来自Worksheet对象的title变量的字符串。
这个程序将包含许多嵌套的for循环。程序的框架看起来会像这样:
for excelFile in os.listdir('.'):
# Skip non-xlsx files, load the workbook object.
for sheetName in wb.get_sheet_names():
# Loop through every sheet in the workbook.
sheet = wb.get_sheet_by_name(sheetName)
# Create the CSV filename from the Excel filename and sheet title.
# Create the csv.writer object for this CSV file.
# Loop through every row in the sheet.
for rowNum in range(1, sheet.max_row + 1):
rowData = [] # append each cell to this list
# Loop through each cell in the row.
for colNum in range(1, sheet.max_column + 1):
# Append each cell's data to rowData.
# Write the rowData list to the CSV file.
csvFile.close()
从nostarch.com/automatestuff2下载 ZIP 文件excelSpreadsheets.zip并将电子表格解压到与你的程序相同的目录下。您可以将这些文件用作测试程序的文件。