目录
- 1.文件描述符fd
- 2.文件描述符的分配规则
- 3.重定向
- 模拟实现<(输入重定向)
- 模拟实现>(将命令的输出结果重定向到一个文件中)
- 模拟实现>>(将命令的输出结果追加到一个文件中)
- 使用 dup2 系统调用
- 重定向stdout
- 重定向stdin
- 4.缓冲区
- 5. FILE
1.文件描述符fd
通过对open函数的学习,我们知道了文件描述符就是一个小整数
而现在知道,文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件
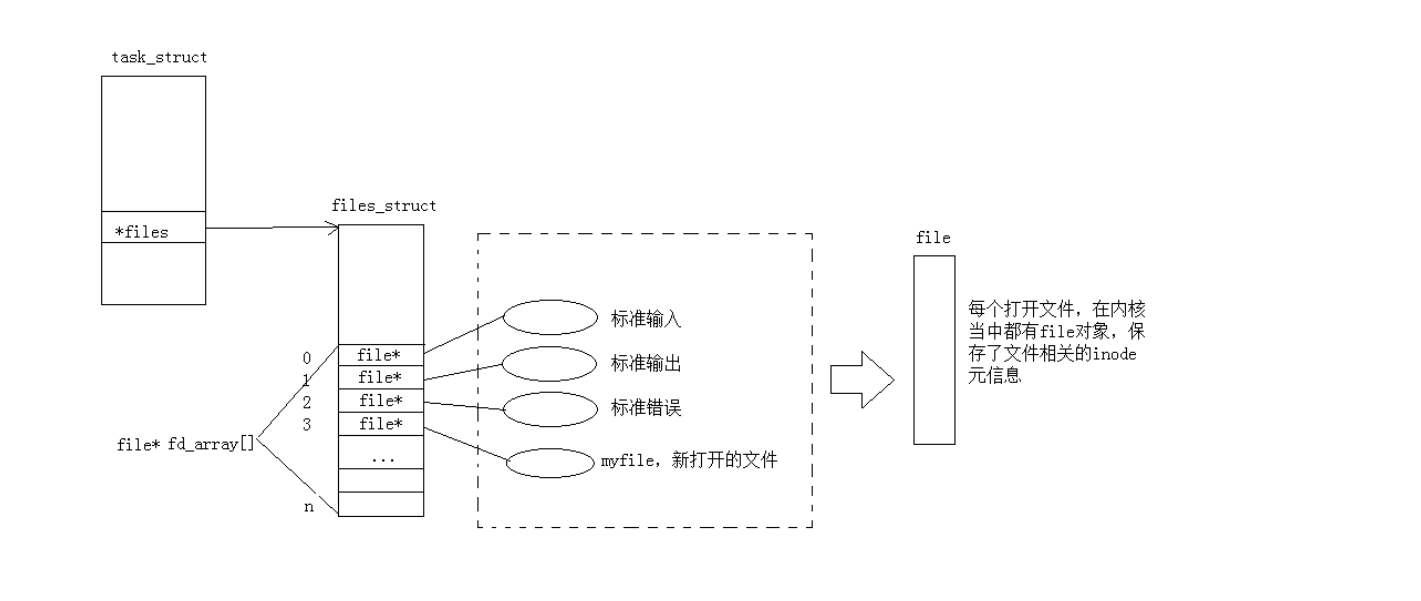
现在我们再来理解,什么才叫是一切皆文件呢?
我们在底层当中一定会有许多硬件,如:键盘、显示器、磁盘、网卡等。在我们眼里,这每一个硬件都是一个单独的个体,这些设备对应的操作方法一定是不一样的
-
对键盘:
读:read_keyboard();
写:write_keyboard(); -
对显示器:
读:read_screen(); (空的)
写:write_screen();
我们是无法从显示器上读到数据的,所以对于显示器读为空 -
对磁盘:
读:read_disk();
写:write_disk();
我们每一个文件都会对应一个文件结构体便于存储
struct file
{
int type;
int mode;
int pos;
int flag;
........
//函数指针--方法集
size_t(*read)(xxxx); //读方法
size_t(*write)(xxx); //写方法
struct file *next; //下一个文件的指针
....
}
文件对每一个键盘都会开一个文件结构体与其对应的硬件相链接
1. 文件对键盘:
读:size_t(*read)(xxxx); ---指向---> read_keyboard();
写:size_t(*write)(xxx); ---指向---> write_keyboard();
2. 文件对显示器:
读:size_t(*read)(xxxx); ---指向---> read_screen(); (空的)
写:size_t(*write)(xxx); ---指向---> write_screen();
3. 文件对磁盘:
读:size_t(*read)(xxxx); ---指向---> read_disk();
写:size_t(*write)(xxx); ---指向---> write_disk();
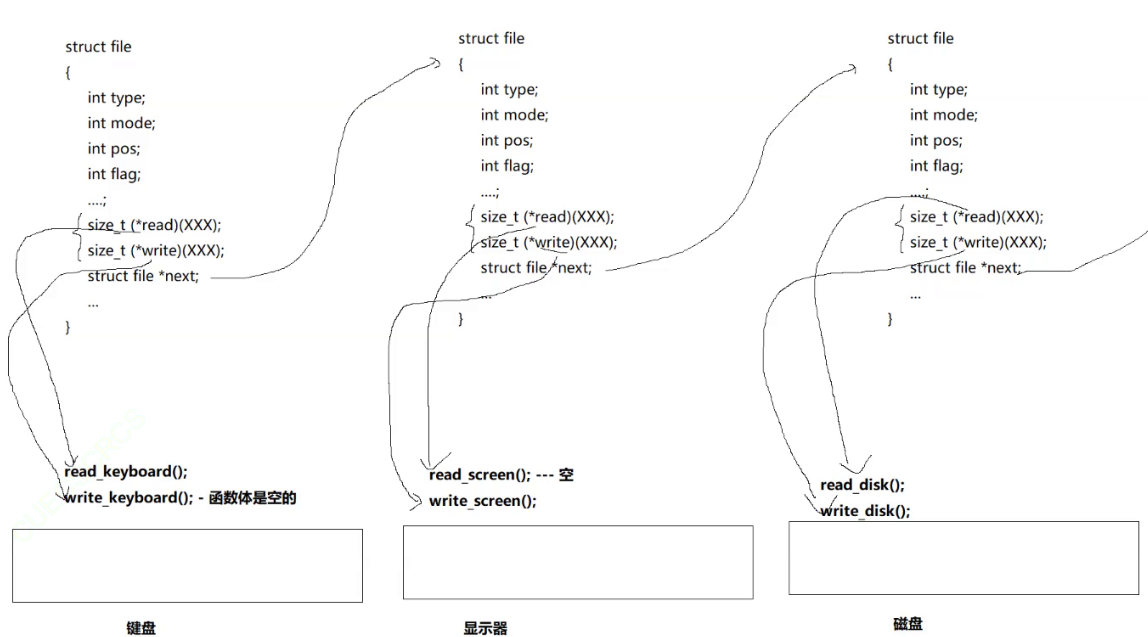
我们读键盘,就会调用键盘对应的函数接口,其他的同理,在上层我们只需要对文件函数指针进行调用就可以,因为有函数指针的存在,对于上层用户就可以认为一切皆指针,对我们来说硬件的差异已经被文件结构体屏蔽掉了。
这就相当于我们使用C语言实现了面向对象,对于不同的对象实现不同的功能,其函数指针也就相当于我们C++的多态调用!
2.文件描述符的分配规则
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd == -1)
{
perror("open");
return 1;
}
printf("fd: %d\n",fd);
return 0;
}

输出是fd:3,原因上一节也讲过,这是因为012默认打开了
- 我们将0标准输入关掉会发生什么?
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
close(0); //将0标准输入关掉
int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd == -1)
{
perror("open");
return 1;
}
printf("fd: %d\n",fd);
return 0;
}

发现是结果是:
fd: 0
可见,文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
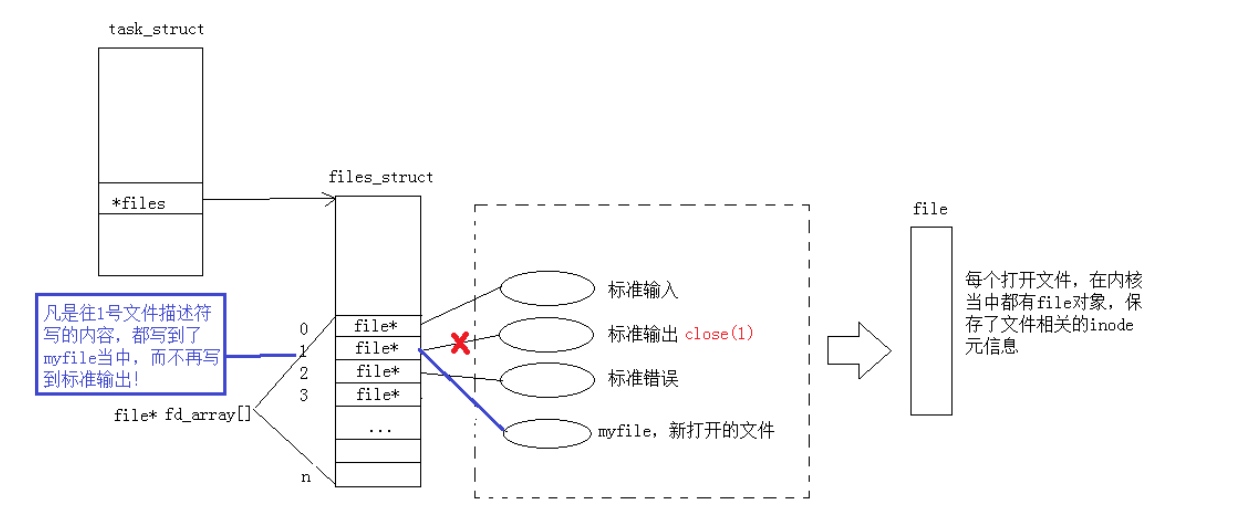
3.重定向
我们关掉标准输出1
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
close(1);
int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd == -1)
{
perror("open");
return 1;
}
printf("fd: %d\n",fd);
return 0;
}

此时,我们发现,本来应该输出到显示器上的内容,输出到了文件
log.txt(myfile)当中,其中,fd=1。
这种现象叫做输出重定向。常见的重定向有:>, >>, <
那重定向的本质是什么呢?
模拟实现<(输入重定向)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
close(0);
open("log.txt",O_RDONLY); //0
int a = 0;
scanf("%d",&a); //scanf认定的是标准输入stdin -> _fileno = 0
printf("%d\n",a);
return 0;
}

在这里就是将下标为0的文件描述符指针指向了我们的文件log.txt,这样就实现了我们输入重定向,直接从文件里面读的数据,因为scanf并没有从我们的键盘读入数据
模拟实现>(将命令的输出结果重定向到一个文件中)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
close(1);
open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666); //0
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
return 0;
}
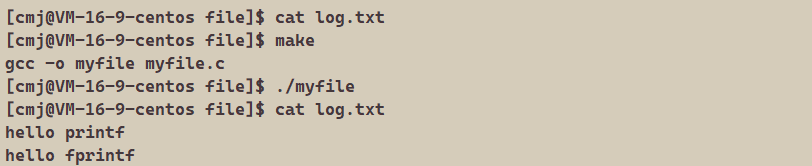
我们就实现了直接对文件进行写入
在这里就是将下标为1的文件描述符指针指向了我们的文件log.txt,这样就实现了我们输出重定向
模拟实现>>(将命令的输出结果追加到一个文件中)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
close(1);
open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
return 0;
}
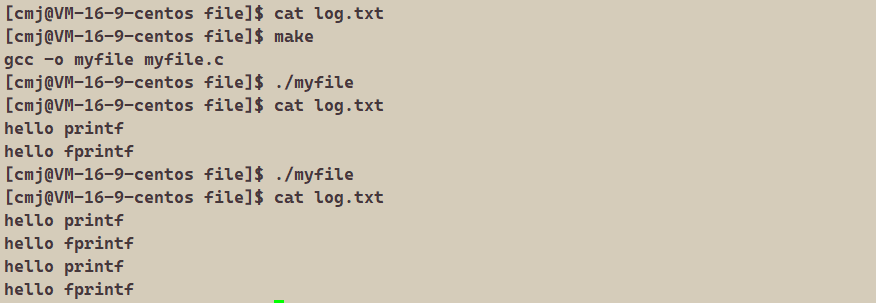
使用 dup2 系统调用
我们上面几个方式还是太复杂了,接下来我们来感受一个新的函数–dup2函数
在Linux中,dup2函数是用于复制文件描述符的函数。它的原型如下:
#include <unistd.h>
int dup2(int oldfd, int newfd);
-
该函数的作用是将oldfd指向的文件描述符复制到newfd指向的文件描述符。如果newfd已经打开,则会先关闭newfd指向的文件描述符,然后再复制oldfd。
-
dup2函数的返回值为新的文件描述符,如果复制成功,则返回newfd;如果出错,则返回-1,并设置errno来指示错误类型。
-
使用dup2函数可以实现重定向标准输入、输出和错误输出。例如,可以将标准输出重定向到一个文件中,或者将标准错误输出重定向到一个套接字中。
重定向stdout
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd = open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
dup2(fd, 1);
printf("hello hahahaha\n");
return 0;
}

要想使用重定向,使用dup2函数就可以了
其实我们使用的
printf/scanf/fprintf/fscanf/sscanf/sprintf....这些是只认stdin/stdout的,也就是说只认文件描述符为0/1的
重定向stdin
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd = open("log.txt",O_RDONLY);
dup2(fd, 0);
char buffer[1024];
while(1)
{
char* s =fgets(buffer, sizeof(buffer), stdin);
if(s == NULL) break;
printf("file content: %s", buffer);
}
return 0;
}

我们将stdin指向了文件log.txt,于是我们从log.txt中读取数据
4.缓冲区
缓冲区它就是一块内存区
为什么要有缓冲区?
比如说这里有你的宿舍和你朋友的宿舍,你们不在同一个城市,相隔较远,但是你朋友今天过生日,你给他买了一个键盘,你就抱着键盘,坐火车去你朋友的城市,再去到他的学校门口,最后喊他出来拿生日礼物。这个方式是不是效率太低了?
- 我们其实可以通过寄快递的方式,将你的礼物送给你的朋友,你也只需要出宿舍进到快递站,这个快递站就相当于我们的缓冲区,缓冲区的存在意义就在于提高我们使用者的效率。因为有快递站的存在,我们就可以把东西给他就可以实现目的,同样的,我们只需要将数据拷贝到缓冲区就可以了;我们将东西送到快递站之后,快递站也不是一收到你的东西他就会立马给你送,它会收到很多东西后,一起进行发送,同样的,我们的缓冲区也会聚集数据,一次拷贝,提供整体效率,有了缓冲区,就可以减少我们拷贝的次数,缓冲区的主要目的就是提高效率
从技术角度来说,缓冲区的本质就是一块内存区域,其提高效率的本质就是使用空间换时间。
- 我们平时所用的缓冲区,和操作系统内核本身没有任何关系(尽管他有),我们这个缓冲区是语言层面的缓冲区,对于我们遇到的就可以解释为C语言会自带缓冲区
- 进程的pcb指向自己的文件描述表,文件描述表指向我们的文件结构体,文件结构体里有指针指向我们的文件缓冲区,再由文件缓冲区会将我们的数据刷新到磁盘里。
- 调用系统调用是有成本的,时间&&空间,例如:创建一个进程是需要fork的,在系统里要对其申请一大堆东西,这是需要大量时间空间的,所以系统会提前申请好一大堆空间,我们需要用的时候直接用。
- C语言在它自己的语言层定义了一层缓冲区,我们写数据是将数据写到C语言的缓冲区里,再由它调用系统调用帮我们写入内核。
- 为什么C语言要维护这么一个缓冲区?
提供C语言的缓冲区可以让我们在调用fwrite的函数调用系统调用的过程中减少我们对系统调用的次数,我们将一次调用的结果拷贝到缓冲区,之后每次调用就可以直接调用,不用再重复进行系统调用了,系统调用是需要成本的,通过缓冲区可以整体提高我们的拷贝效率,直接提高C接口的使用效率!
缓冲区是如何刷新数据的?
应用层缓冲区刷新策略
- 无刷新,无缓冲
- 行刷新 — 显示器 — xxx\nyyy 将\n之前的数据xxx给你刷新出去
- 全刷新,全部刷新 — 普通文件,我们访问普通文件会将缓冲区写满再刷新
- 用户强制刷新
- 进程退出时自动刷新
内核缓冲区是由操作系统自主决定的
5. FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。
所以C库当中的FILE结构体内部,必定封装了fd。
缓冲区具体在哪里?
我们的
stdin,stdout,stderr,fp都是FILE*的文件,每一个文件都对应一个缓冲区,缓冲区是在FILE结构体中维护的。所以我们平时使用的fwrite和fputs,的参数都有FILE*的参数,我们输入的字符串都会在FILE*内部的缓冲区进行拷贝,我们调用十次百次都会在其中进行调用,就不需要重复调用系统调用,提高效率
size_t fwrite(const void *ptr, size_t size, size_t nmemb,FILE *stream);
int fputs(const char *s, FILE *stream);
来段代码研究一下:
#include <stdio.h>
#include <string.h>
int main()
{
const char *msg0="hello printf\n";
const char *msg1="hello fwrite\n";
const char *msg2="hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}

但如果对进程实现输出重定向呢? ./hello > file , 我们发现结果变成了:

我们发现 printf 和 fwrite (库函数)都输出了2次,而 write 只输出了一次(系统调用)。为什么呢?肯定和fork有关!
- 一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
- printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
- 而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
- 但是进程退出之后,会统一刷新,写入文件当中。
- 但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
- write 没有变化,说明没有所谓的缓冲
综上:
printf fwrite库函数会自带缓冲区,而write系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。- 那这个缓冲区谁提供呢?
printf fwrite是库函数,write是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是write没有缓冲区,而printf fwrite有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供
如果有兴趣,可以看看FILE结构体
typedef struct _IO_FILE FILE; 在/usr/include/stdio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};