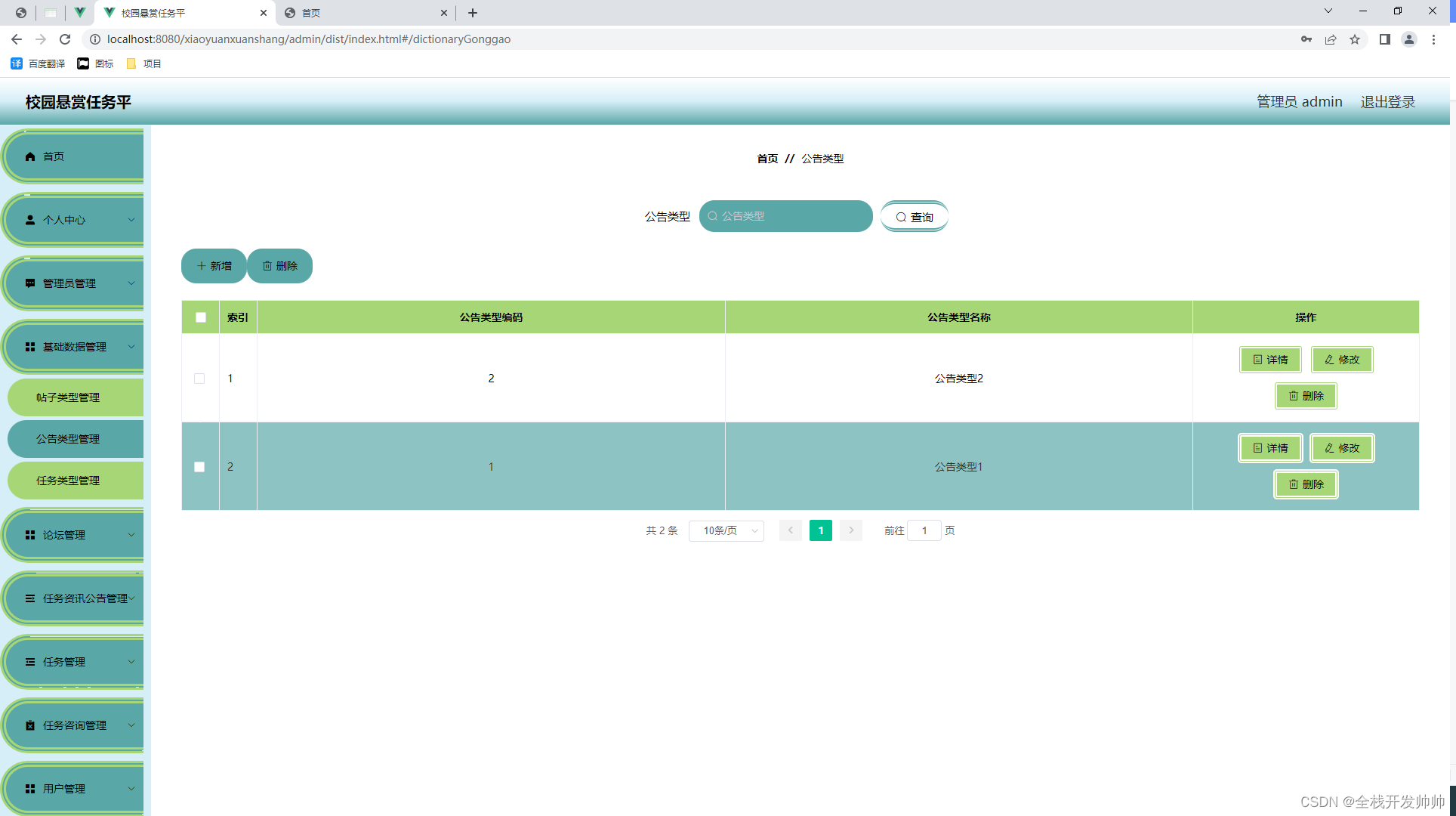
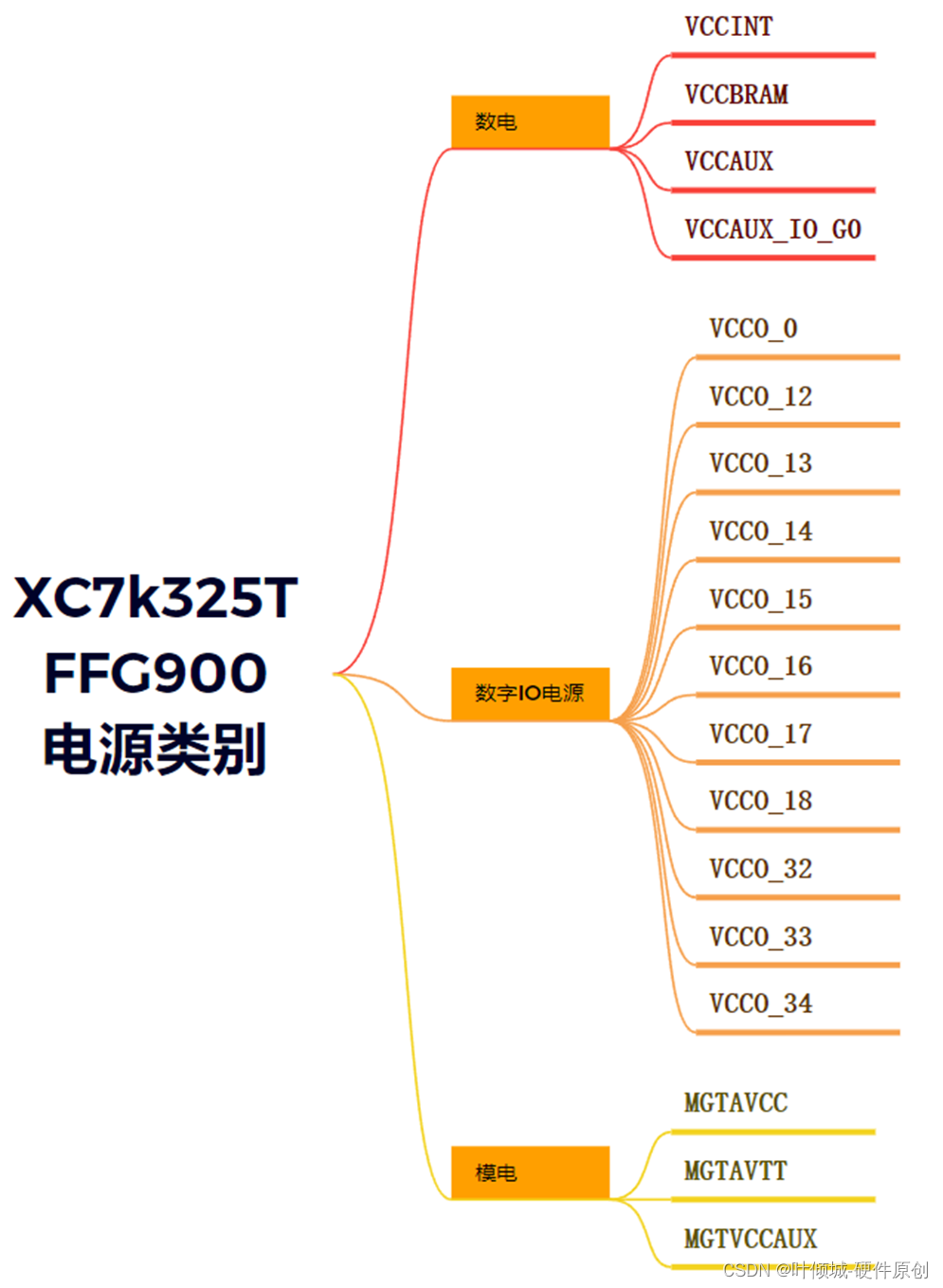
二进制
byte 在电脑中的单位换算:
kilobyte 千字节
megabyte 兆字节
gigabyte 千兆字节
1kb=210bit = 1024byte =1000b
1Mb = 220bit = 1024kb
1Gb = 230bit
1TB=1000GB
1GB=十亿字节=1000MB=10^6KB
Gb 和 GB
一般而言GB用于文件,Gb用于通信。B代表Byte,b代表比特bit,两者是八倍的关系。如果考虑到通信过程中的校验码等信息,这个实际关系差距是在十倍。
1GBps的传输速率= 8Gbps
100MBps = 800Mbps
运营商所谓的百兆宽带,千兆宽带,也都是b结尾。百兆宽带,实际上只有12.5MB每秒的文件传输速度。
32 位与 64 位电脑的区别
32 位的最大数为 43 亿左右 32 位能表示的数字:0——2的32次方-1,一共2的32次方个数
64 位的最大数为 9.2*10^18
浮点数(Floating Point Numbers):
定义:小数点可在数字间浮动的数(非整数)
表示方法:IEEE 754 标准下
用类似科学计数法的方式,存储十进制数值
-
浮点数=有效位数*指数
-
32 位数字中:第 1 位表示正负,第 2-9 位存指数。剩下 23 位存有效位数
eg.625.9=0.6259(有效位数)*10^3(指数)
美国信息交换标准代码-ASCⅡ,用来表示字符
1 全称:美国信息交换标准代码
2 作用:用数字给英文字母及符号编号
3 内容:7 位代码,可存放 128 个不同的值。
4 图示:
UNICODE,统一所有字符编码的标准
1 诞生背景:1992 诞生,随着计算机在亚洲兴起,需要解决 ASCⅡ不够表达所有语言的问题。
为提高代码的互用性,而诞生的编码标准。
2 内容:UNICODE 为 17 组的 16 位数字,有超过 100 万个位置,可满足所有语言的字符需求。
算术逻辑单元 ALU
背景
表示和存储数字是计算机的重要功能,但真正的目标是计算,有意义的处理数字 —— 比如把两个数字相加。
这些操作由计算机的"算术逻辑单元"处理,即ALU(Arithmetic and Logical Unit)。
ALU即计算机里负责运算的组件。

Intel 74181 :1970 年发布时,它是第一个封装在单个芯片内的完整 ALU。
本章我们用前面的布尔逻辑门,做一个和 74181 功能一样的 ALU 电路。
介绍
ALU有2个单元:
- 算术单元(Arithmetic Unit) :算术单元负责数字操作
- 逻辑单元(Logic Unit) :逻辑单元执行逻辑操作
算术单元
算术单元负责计算机里的所有数字操作
像加减法,还有增量运算(给某个变量+1)
实现加减法可以用单个晶体管一个个拼,做成电路。但那太麻烦了,这里用更高层的抽象,即逻辑门来做。
逻辑门有: AND 、OR、XOR、NOT
半加器

通过观察单个1和0之间的运算,发现异或可以满足前三个输入输出,第四个1+1的输出需要进位。
所以需要一根额外的进位线。让组件满足只有输入是1和1时,进位才是“True”。
发现这个条件,AND 门刚好能满足。于是加入电路中,组成半加器。

半加器:个人理解,完成加法的一半,也就是一位的运算以及进位。
多位计算需要全加器。
全加器
将半加器抽象为名为 HALF ADDER 的单独组件,进行更高层抽象:处理超过1+1的运算,需要全加器。
全加器表格:

最大的数是1 + 1 +1 ,总和是1,进位也是1 。 即两条输出线:SUM CARRY。
利用半加器组装全加器。
先输入A+B到一个半加器上,然后把C输入到第二个半加器上。最后用一个OR门检查进位是不是True。

8位加法器
把全加器进行更高一层抽象,也就是作为一个独立组件 Full Adder,三个输入 ABC,输出总和和进位。
前两位数A0、B0的加和用一个半加器 Half Adder 就好。因为前两位肯定没有进位。
-
A0和B0 的和即 输出的第一位。
-
将两者的进位,作为全加器的一个输入A。而输入B、C则是第三、第四位数据A1、B1的加和。
第三位开始有进位了。
-
然后将A1和B1的进位连接到A2和B2的输入A中,如此循环往复…


注意每个进位是怎么连到下一个全加器的,所以叫“8位行波进位加法器(8-bit ripple carry adder)。
如果最后两位加和后还有进位,就不需要连接了。
因为出现了 溢出 Overflow 现象,8位已经不足以表示更高位的结果了。
这种加法器的缺点:
- 表达的位数越多,需要的全加器越多。
- 每次进位都要一点时间,虽然因为电子移动很快用不了多少时间,但还是承受不了当今几十亿次运算的量级。
所以,现代计算机用的加法电路有点不同:使用的是更快的超前进位加法器Carry-Look-Ahead Adder 。
ALU的算术单元也支持做一些其他的运算,一般都支持这8个操作:
加法、带进位加法、减法、带进位减法,
增量、减量:+1,-1
PASS THROUGH:All bits of A are passed through unmodified
NEGATE:A is subtracted from zero, flipping its sign(from-to +,or +to -)
简单ALU不会专门为加法减法设计,而是通过循环加法或循环减法来实现。
例如电视遥控、恒温器、微波炉
有些ALU为了运算速度,会有专门的乘除法ALU。只是需要的逻辑门更多。
电脑、手机。
逻辑单元
逻辑单元执行逻辑操作。
例如AND,OR 和 NOT 操作,或者一些简单的数值测试:是不是负数?
示例:下面是一个检查输出结果是不是负数的电路。

以上即ALU的全部内容。
值得一提的是,Inter 74181 只能处理4位输入。所以你刚刚做了一个比 74181 还好的 CPU!
74181 用了大概 70 个逻辑门,但不能执行乘除,但它向小型化迈出了一大步。
工程师在使用ALU时,不需要理解ALU内部构造。所以用一个大V字来表示。

图中的8位ALU有两个8位输入。通过操作代码OPERATION CODE来告知ALU将进行哪种操作。
例如,1000代表加法,1100代表减法。输出结果也是8位。
好了。你已经掌握了ALU的大致内容了,也能够了解计算机里一批批单晶管是怎样协作运算数据的。
但制作一个CPU不仅要会运算,还要能记忆。
下一章我们将学习存储功能的实现。
寄存器&内存
ALU能执行算术(Arithmetic)和逻辑(Logic)运算,ALU 里的 A 和L因此得名。
但是结果算出来不能仍掉,还需要找地方存储。这就需要内存了。
前置知识

只能存 0 的ALU。

只能存 1 的ALU。
两个合体,变成锁存器:能存储 1 / 0 的ALU。
锁存器

门锁

-
和锁存器区别:
锁存器的
“RESET复位”还不能达到“是否允许写入”的要求。例如 : Set 为1 时,Reset 的改变会导致结果的改变。而门锁就能避免这种情况。
-
下面两次取反:
- 数据输入不变,改变允许写入时,结果不变;
- 数据输入改变,允许写入为 0 时,结果不变;
- 数据输入改变,允许写入为 1 时,结果改变;
实现了“只有允许写入改变为1后,数据输入的改变才有效。”
其他情况结果不变:如允许写入线改变,允许写入线为 0 时的数据输入改变。
所以从命名也可以看出来:
- Reset 复位 可以看成是重置输出为0,且锁定为0;
- WRITE ENABLE 允许写入 自身的改变不影响输出,只影响数据的输入是否改变输出。
这里也能看出下面两个连续取反的ALU的意义:
①当允许写入为0,结果锁定;
②当允许写入为1,数据输入为1,结果为1;数据输入为0,结果为0。

一个门锁只能存1bit数据。8个并列的门锁能存储8位的信息。
一组这样的锁存器就是寄存器。
寄存器能存一个数字,这个数字有多少位,叫"位宽。
早期电脑用 8 位寄存器,然后是16 位,32 位。如今许多计算机都有 64 位宽的寄存器。
-
我们可以用一根线连接所有"允许输入线",把它设为 1。
-
接着用8 条数据线发送数据,然后将“允许写线”设回0。
这样,一个8位信息就被记录好了。
矩阵
但很显然,上面那种并排门锁的8位寄存器还远远不够用。64 位寄存器要 64 根数据线,64 根输出线,还有一根允许输入线。这样加起来也有129根。如果存 256 位要 513 条线。
解决方法就是矩阵。


通过“门锁矩阵”能节省很多线,表达更多的位数。
"12行 8列"可以写成 11001000
例如 16x16 = 256 位,只需要 16 根行线 + 16 根 列线 + 1根数据线 + 1根允许输入线 + 1根允许读取线 = 35 根线。
-
256个门锁构成
256-bit 寄存器,但八个输入接口通过十六位多路复用器(multiplexer),每次只能激活其中一个门锁。也就是一次只能存储256位中的一位,不能并行处理了。
两个多路复用器分别处理行和列。
-
把上面的能表示256位的内存抽象成 “256-BIT MEMORY”。通过8个内存并列实现8位数字的存储。

为了实现8位数字的存储,数字的每一位依次由其中一个256-BIT 内存存取。
由于每个内存只能表示一位,所以我们同时给 8 个 256 位内存一样的地址,让他们各取一位就好了。
这意味着这里总共能存 256 个字节(byte)。
256 bit x 8个 = 256 byte
一个8位的二进制数分别被写入到8个内存的同一二进制位来记录,8个256位内存则可以存储256个8位二进制数。
或者说,一byte的数据分八bit存八个memory里面,读写时地址共用(8个register 都是同一二进制位),就到一起了
-
再次抽象,不看作是一堆独立的存储模块和电路,而是看成一个整体的可寻址内存。

这就构成了一个能存储 256B 的内存条。
实例:

这是一条真的内存,上面焊了8个内存模块。
打开其中一个,然后放大:

可以看到32个内存方块。
放大其中的一个方块,可以看到还有4个小块。

四个小块再放大,就可以看到矩阵了。

-
这个矩阵是128位x64位,总共8192位。
-
每个方格 4 个矩阵,所以一个方格有 32768 个位(8192x4=32768)
-
每个内存模块32个方格,所以一个内存模块大约有 100 万位。
-
RAM有8个内存模块,所以大概能存储800万位。
800万位大概1MB左右吧。
1GB的内存,能存数十亿字节。
我们用锁存器做了一块 SRAM(静态随机存取存储器)。还有其他类型的 RAM,如 DRAM,肉存和 NVRAM。它们功能上相似,但用不同电路存单个位。比如用不同的逻辑门,电容器,电荷捕获或忆阻器(logicgates,capacitors, charge traps, or memristors.)
但根本这些技术都是矩阵层层嵌套,来存储大量信息
就像计算机中的很多事情,底层其实都很简单,难以理解的只是一层层的抽象。
CPU 中央处理器
指令
程序由一个个操作,也就是指令构成。
数学指令,CPU会让ALU进行数学运算
内存指令,CPU会和内存通信,然后读/写值
通过指令表可以了解到指令名、对应描述、4位操作码和需要的地址/寄存器。

也就是说,计算机给CPU支持的所有指令都分配一个ID,实现区分。
本例中指令的前4位为操作码(opcode),后4位代表数据来自哪里。
CPU结构
下面CPU结构中的线只是所有必须线路的抽象,即“微体系架构(microarchitecture)”
示例中的地址有一个16位置,每个位置能存8位的内存,还有四个8位寄存器。
还有两个帮助操作的寄存器,一个追踪程序运行地址的指令地址寄存器,一个存当前指令的指令寄存器PC。
当启动计算机时,所有寄存器从0开始。

运行命令
CPU的运行共三个阶段:取指令、解码、执行。
以LOAD_A 为例: Read RAM location into register A
-
取指令阶段:本阶段负责拿到指令
将
指令地址寄存器连接到RAM。
寄存器地址值为0,因此 RAM 返回地址 0的值。
可以看到地址0的数据
00101110会复制到指令寄存器里
-
解码阶段:解释指令内容
前4位
0010是 LOAD A 指令。通过指令表可知,能将RAM的值放入寄存器A。后4位
1110是 RAM 的地址,十进制为14.区分指令内容后,由控制单元(Control Unit) 解码,识别指令,检查操作码。
控制单元同样由很多逻辑门组成。(不是很多啦)。
控制单元指挥着CPU的所有组件

-
执行阶段
用控制单元中"检查是否是 LOAD A 指令的电路”,可以打开 RAM 的允许读取线,把地址 14 传过去。RAM 拿到值,
0000 0011,十进制的 3。
因为是 LOAD_A指令,所以把读取到的值 3 只放到寄存器 A ,其他寄存器不受影响。
此时问题来了:需要一根线,把 RAM 连接到4个寄存器,让我们传值过去!
还是用控制单元中"检查是否是 LOAD A 指令的电路”,连接启动寄存器A的允许写入线。
于是把 14 放到了寄存器A中,
LOAD_A 14指令执行完成
收尾:关掉所有线路,去拿下一条指令(也就是指令地址寄存器+1)
以ADD为例:Add two registers , store result into second register.
-
取指令: 指令地址寄存器指向2,读取
10000100到指令寄存器中。 -
解码:
前四位 :
1000ADD命令后四位 :
0100, 01 为寄存器B,00为寄存器A。通过控制单元,解码,识别指令,检查操作码。
-
执行:把
register B的值加到register A中。启动寄存器B,作为ALU的第一个输入;启动寄存器A,作为ALU的第二个输入。

ALU可以执行不同操作,所以控制单元必须传递ADD操作码告诉它要做什么
最后,结果存到寄存器A。
**注意:**不能直接写入寄存器A,因为寄存器A此时正在作为输入,写入后新值会进入ALU,导致A不断和自己相加。
因此,控制单元用一个自己的寄存器暂时保存结果,关闭ALU,然后把值写入正确的寄存器。再由寄存器赋值到寄存器 A。
收尾:关掉所有线路,去拿下一条指令(也就是指令地址寄存器+1)
以store A 为例:Write from register A into RAM location
-
取指令: 指令地址寄存器指向3,读取
01001101到指令寄存器中。 -
解码:
前四位 :
0100STORE A 指令后四位 :
1101, 01 为寄存器B,00为寄存器A。
通过控制单元,解码,识别指令,检查操作码。
-
执行:
把地址传给RAM,这次不是允许读取,而是允许写入。
同时打开寄存器A的允许读取,这样可以把寄存器A的值传给RAM。
完成了!
总结:
1.通过上例可以了解,CPU运行指令,通过RAM和寄存器之间的数据传输,以及控制单元和ALU的检验、运算,从而完成一次操作。
2.RAM有配合控制单元的 允许写入线、允许读取线、地址输入线;
还有配合数据寄存器以及指令寄存器的 DATA 线。
寄存器也有允许写入线、允许读取线。
时钟
时钟负责管理CPU的节奏,区分每一步操作。
时钟以精确的间隔触发电信号,控制单元会用这个信号,推进 CPU 的内部操作,确保一切按步骤进行。
CPU"取指令一解码一执行"的速度叫 时钟速度。
单位是赫兹。
赫兹是用来表示频率的单位。1 赫兹代表一秒1个周期
超频:
意思是修改时钟速度,加快 CPU 的速度。芯片制造商经常给CPU 留一点余地,可以接受一点超频。但超频大多会让CPU 过热,或产生乱码,因为信号跟不上时钟。
降频:
有时没必要让处理器全速运行。把 CPU 的速度降下来,可以省很多电。
为了省电,很多现代处理器可以按需求 加快或减慢时钟速度,这叫动态调整频率。
高级CPU设计
从前面几章,我们从一秒一次的运算,到现在有千赫甚至兆赫CPU。现在的单位是GHz,1秒10亿次运算。多么大的计算量!
为 CPU 提升速度早期计算机到现代计算机厂商和科学家们发明了各种新技术来提高性能。
-
减少晶体管切换时间
早期提速的方式便是
减少晶体管的切换时间,使晶体管组成了逻辑门,ALU 以及前几集的其他部件。这种提速方法会遇到瓶颈。于是处理器厂商不仅让简单指令运行更快,还让它能支持更复杂的运算。
-
利用复杂电路实现算法
例如除法和乘法需要程序多次运行减法和加法,为了省去循环的功夫,现代 cpu 直接在硬件层面上设计了除法等复杂电路以节省某些运算。这让ALU更大更复杂,但也加快了运行速度。
复杂度和速度的矛盾一直存在。
举例,现代处理器有专门电路来处理图形操作,解码压缩视频,加密文档 等等。如果用标准操作来实现,要很多个时钟周期。
某些处理器有 MMX, 3DNOW, SSE,他们就拥有额外电路用于处理游戏和加密等场景。
随着指令不断增加,为了兼容旧指令集,指令数量越来越多。
英特尔4004,第一个集成CPU,有 46 条指令,足够做一台计算机。
现代处理器有上干条指令和更多巧妙复杂的电路。
-
给 CPU 增加缓存
超高的时钟速度带来另一个问题:如何快速传递数据给 CPU?
就像有强大的蒸汽机 但无法快速加煤。
RAM成了瓶颈。RAM 是 CPU 之外的独立组件,意味着数据要用线来传递,叫"总线“。总线就几厘米,而电信号传输接近光速。
但CPU每秒可以处理上亿条指令,两者执行任务的速度还是过于悬殊。一条”从内存读数据”的指令可能要多个时钟周期,CPU只能苦苦等待。
RAM 是 CPU 之外的独立组件,通过总线 (Bus) 传递数据,为了避免数据传输带来的延迟,解决的方法是为 CPU
增加一点RAM作为缓存。读取时 RAM 将一批数据提前传入 CPU 缓存,这样处理的时候 CPU 直接从离得近的缓存中获取数据就比从 RAM 中获取数据要快。
处理器空间不大,缓存一般只有KB或MB。
于是数据传输单位从一个变成了一批。
缓存命中
如果想要的数据已存在缓存中则叫做
缓存命中,否则叫做缓存未命中。同步更新:
缓存也可以作为临时空间存储一些运算过程中的中间值,适合长 / 复杂的运算。但是计算完后的值想要存储会先存入缓存中,而缓存中的值可能还有运算的中间值导致缓存和 RAM 内数据不一致,因此缓存里的数据要对 RAM 里的数据进行
同步更新。脏位:
对此缓存里的每块空间都有一个叫做
脏位的标记声明该数据是否修改过。同步更新一般是发生在缓存满了,又需要缓存时。这时会检查缓存中的脏位,如果是脏的就将数据写回 RAM 中。
另一种提升性能的方法:instruction pipelining 指令流水线。
可以通过不同的指令运行方式以提升 CPU 速度。
-
顺序串行执行
严格按照顺序上一条命令结束才执行下一条命令
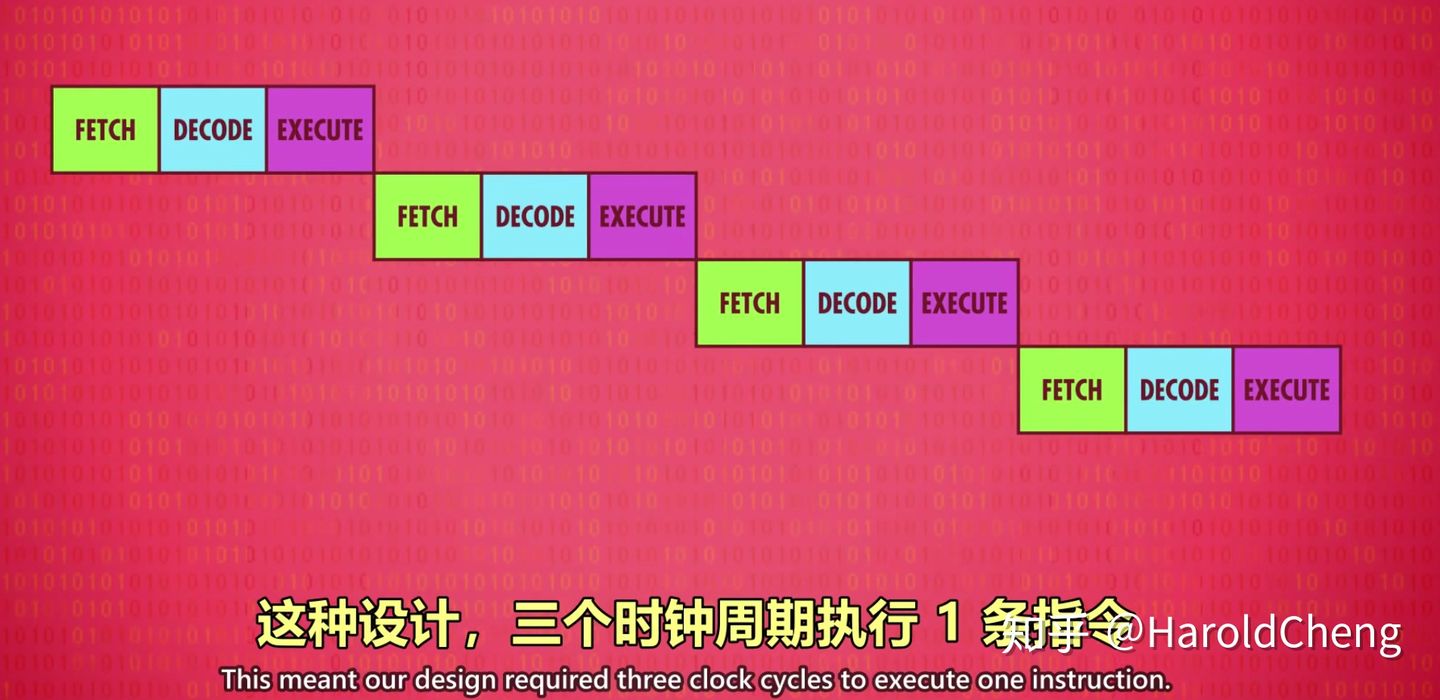
-
顺序并行执行
在上一条指令执行时就处理下一个指令的解码步骤,下下条指令的读取步骤。
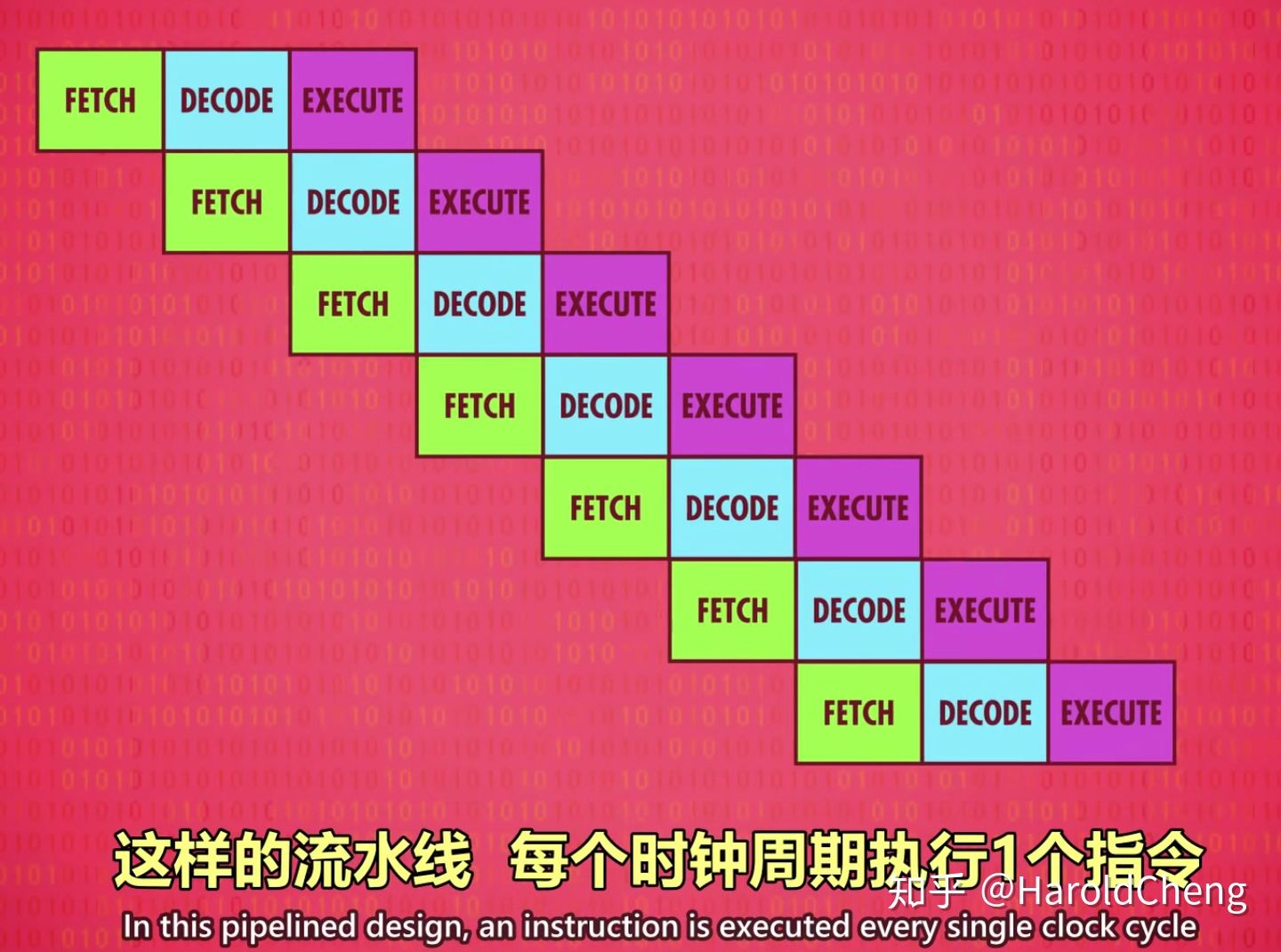
-
乱序执行
第一个问题:指令之间的依赖性
问题举例:在读取的同时,正在执行的指令在改这个数据。
这种情况需要搞清楚数据之间的依赖性,必要时停止流水线,避免出问题。
解决:
高端CPU会通过动态调整,进一步动态排序有依赖关系的指令。最小化流水线的停工时间。这叫乱序执行。
电路复杂,但很高效。几乎每个现代处理器都有流水线。
-
推测执行 | 分支预测
第二个问题:条件跳转
这些指令会改变程序的执行流。简单的流水线处理器,看到 JUMP 指令会停一会儿,等待条件值确定下来。但空等会有延迟。所以高端CPU会用一些技巧:
解决:
遇到岔路口时,猜测 JUMP 指令走哪条路的可能性更大一些,然后提前把指令放进流水线,这叫“推测执行。
猜对了可以直接执行,猜错则要清空流水线(就像走错路掉头)。
为了尽可能减少清空流水线的次数,CPU 厂商开发了复杂的方法来猜测:分支预测。
现代 CPU 的正确率超过 90%!
-
超标量处理器SUPERCALAR PROCESSOR
理想情况下,流水线一个时钟周期完成1个指令。
即便有流水线设计,在指令执行阶段,处理器里有些区域还是可能会空闲。
比如,执行一个“从内存取值”指令期间,ALU会闲置。
所以一次性处理多条指令(取指令+解码) 会更好,如果多条指令要 CPU 的不同部分,就多条同时执行。
借助
超标量处理器SUPERCALAR PROCESSOR一次性处理多条指令 (类似多线程)。为出现频率很高的指令加多几个相同的电路,ALU 执行。 -
目前说过的方法,都是优化1个指令流的吞吐量。
另一个思路是运行多个指令流,也就是多核处理器。
CPU 芯片内的多个独立处理单元 (多核) 就像有多个 CPU 能够合作运算 (共用一个 CPU 的缓存)。如果多核还不够就用多个 cpu。
集成电路
在大概50年里,软件从纸带打孔变成面向对象编程语言,在集成开发环境中写程序,没有硬件的大幅度进步,软件不可能做到这些。
回到电子计算机的诞生年代:
电子管
大约 1940年代~1960年代中期这段时间里 , 计算机都由独立部件组成。
这些独立部件叫"分立元件" ,然后不同组件再用线连在一起

举例, ENIAC 有1万7千多个真空管, 7万个电阻 , 1万个电容器, 7千个二极管, 5百万个手工焊点

如果想提升性能,就要加更多部件。 这导致更多电线,更复杂;这个问题叫 "数字暴政’'。
晶体管

1950 年代中期,晶体管开始商业化(市场上买得到) \N 开始用在计算机里。晶体管比电子管 更小更快更可靠。但晶体管依然是分立元件
1959年,IBM 把 709 计算机从原本的电子管全部换成晶体管。
诞生的新机器 IBM 7090 速度快 6 倍,价格只有一半!
晶体管标志着"计算 2.0 时代"的到来。
虽然更快更小 但晶体管的出现 还是没有解决"数字暴政"的问题。
有几十万个独立元件的计算机不但难设计,而且难生产。
集成电路
1960 年代,这个问题的严重性达到顶点 电脑内部常常一大堆电线缠绕在一起。
看看这个 1965 年 PDP-8 计算机的内部:

解决办法是封装复杂性:也就是电路的所有组件都集成在一起。
与其努力把多个独立部件用电线连起来,拼装出计算机,还不如专注于把多个组件包在一起,变成一个新的独立组件。
这就是 **集成电路(Integrated Circuit)**的诞生。
几个月后,在1959年 Robert Noyce 的仙童半导体 ,让集成电路变为了现实。Kilby 用锗来做集成电路,锗很稀少而且不稳定。仙童半导体公司用硅 \N 硅的蕴藏量丰富,占地壳四分之一,也更稳定可靠。所以 Noyce 被公认为现代集成电路之父,他开创了电子时代,创造了硅谷(仙童公司所在地)

起初,一个 IC 只有几个晶体管。例如这块早期样品,由西屋公司制造:

即使只有几个品体管也可以把简单电路,第 3 集的逻辑门,能封装成单独组件。
IC就像电脑工程师的乐高积木,可以组合出无数种设计。
印刷电路板 PCB Printed Circuit Board

为了解决集成电路仍需通过电路连接制造计算机的问题,工程师们制造了印刷电路板PCB,PCB 可以大规模生产而无需焊接或用一大堆线,它通过蚀刻金属线的方式将零件连接到一起。
把 PCB 和 IC 结合使用 \N 可以大幅减少独立组件和电线,但做到相同的功能。
而且更小,更便宜,更可靠. 三赢!
许多早期 IC 都是把很小的分立元件 \N 封装成一个独立单元,例如这块 1964 年的IBM样品:

光刻
不过,即使组件很小 , 塞5个以上的晶体管还是很困难。
为了实现更复杂的设计,需要全新的制作工艺 \N "光刻"登场!
光刻简单说就是把复杂图案印到如半导体等材料上,可以通过这种技术将复杂金属电路印在半导体上面以集成个多的元件制造复杂电路。
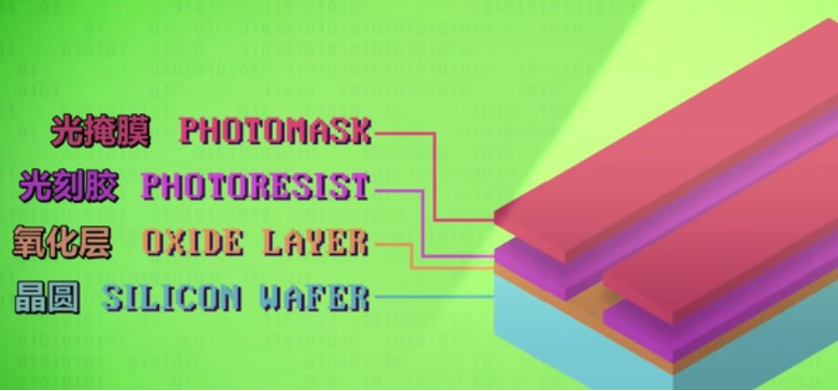
光刻机光刻电路的流程:
-
首先是一块硅 (晶圆):
硅很特别。它有时导电,有时不导电。我们可以控制利用其特性控制导电时机。
我们可以用晶圆做基础,把复杂金属电路放上面,集成所有东西 。
-
在硅片顶部加一层薄薄的氧化层,作为保护层。
-
加一层特殊化学品,叫"光刻胶”。
光刻胶被光照射后 会变得可溶。可以用一种特殊化学药剂洗掉。
-
把光掩膜盖到晶圆上,用强光照射。挡住光的地方,光刻胶不会变化。光照到的地方,光刻胶会发生化学变化洗掉它之后,暴露出氧化层。

-
用另一种化学物质·通常是一种酸,可以洗掉”氧化层"露出的部分,蚀刻到硅层。
注意,氧化层被光刻胶保护住了。
-
为了清理光刻胶,我们用另一种化学药品洗掉它
现在硅又露出来了。我们想修改硅露出来的区域 ,让它导电性更好。

所以用一种化学过程来改变它,叫"掺杂”
"掺杂"通常用高温气体来做,比如磷渗透进暴露出的硅,改变电学性质。

-
但我们还需要几轮光刻法 来做晶体管。
过程基本一样,先盖氧化层,再盖光刻胶。然后用新的光掩膜,这次图案不同。
在掺杂区域上方开一个缺口,洗掉光刻胶,然后用另一种气体掺杂把一部分硅转成另一种形式。

为了控制深度,时机很重要我们不想超过之前的区域。
-
最后一步,在氧化层上做通道这样可以用细小金属导线,连接不同品体管。再次用光刻胶和光掩膜蚀刻岀小通道。
-
现在用新的处理方法 叫"金属化”放一民道道的全属,比如铝或铜。
-
但我们不想用金属盖住所有东西我们想蚀刻出具体的电路。

所以又是类似的步骤:
用光刻胶+光掩膜,然后溶掉暴露的光刻胶,暴露的金属
我们可以把光掩膜聚焦到极小的区域,制作出非常精细的细节。
一片晶圆可以做很多IC整块都做完后,可以切割然后包进微型芯片。
微型芯片就是在电子设备中那些小长方体 。
记住,芯片的核心都是一小片IC>
芯片放大:

摩尔定律
1965 年,摩尔看到了趋势:每两年左右,得益于材料和制造技术的发展,同样大小的空间,能塞进两倍数量的晶体管。这叫摩尔定律。芯片的价格也不断下降。即集成电路上可以容纳的晶体管数目在大约每经过18个月到24个月便会增加一倍
但是摩尔定律现在也在接近极限,进一步做小,会面临两个问题。
- 用光掩膜把图案加到晶圆上,因为光的波长,精度已经达到极限。
- 当晶体管非常小,电极之间可能只距离几个原子,电子会跳过间隙,叫量子隧道贯穿效应
控制单元(Control Unit) :
负责程序的流程管理。正如工厂的物流分配部门,控制单元是整个CPU的指挥控制中心,由指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)和操作控制器OC(Operation Controller)三个部件组成,对协调整个电脑有序工作极为重要。
控制单元可以作为CPU的一部分,也可以安装于CPU外部。









![[每周一更]-第90期:认识Intel的CPU](https://img-blog.csdnimg.cn/direct/046810e3b78c4ac890d7b5da7750fcbf.jpeg#pic_center)