6. 与学习相关的技巧
6.1 参数的更新
神经网络学习的目的是找到使损失函数尽可能小的参数, 这个过程叫最优化_(optimization_), 但是由于神经网络的参数空间复杂,
所以很难求最优解.
前几章, 我们使用参数的梯度, 沿梯度的反向更新参数, 重复多次, 从而逐渐靠近最优参数, 这个过程称为随机梯度下降_(
stochastic gradient descent_),
简称SGD
6.1.1 探险家的故事

6.1.2 SGD
SGD公式
W ← W − η ∂ L ∂ W W \gets W - \eta \frac{\partial L}{\partial W} W←W−η∂W∂L
W 是需要更新的权重参数 , 损失函数关于 W 的梯度记为 ∂ L ∂ W W是需要更新的权重参数, 损失函数关于W的梯度记为 \frac{\partial L}{\partial W} W是需要更新的权重参数,损失函数关于W的梯度记为∂W∂L
η 表示学习率 , < − 表示用右边的值更新左边的值 . S G D 是朝着梯度方向只前进一定距离的方法 \eta 表示学习率, <- 表示用右边的值更新左边的值. SGD是朝着梯度方向只前进一定距离的方法 η表示学习率,<−表示用右边的值更新左边的值.SGD是朝着梯度方向只前进一定距离的方法
# 随机梯度下降
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
# 优化过程中反复使用该方法
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
可以用该SGD类作为优化器, 更新神经网络的参数, 如下(伪代码)
network = TwoLayerNet(...)
optimizer = SGD()
for i in range(10000):
...
x_batch, t_batch = get_mini_batch(...) # mini-batch
grads = network.gradient(x_batch, t_batch)
params = network.params
optimizer.update(params, grads)
...
6.1.3 SGD的缺点
思考一下求下面这个公式的最小值问题
f ( x , y ) = 1 20 x 2 + y 2 f{(x,y)} = \frac{1}{20} x^2+y^2 f(x,y)=201x2+y2
该函数是向x轴方向延伸的"碗"状函数(椭圆状)
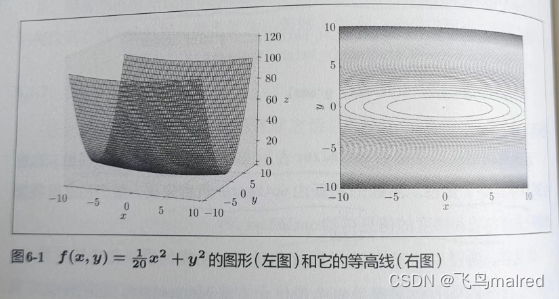
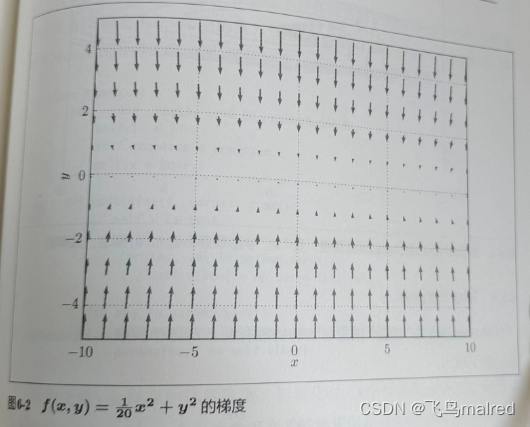
来看一下它的梯度, 特征是: y轴方向上(坡度)大, x轴方向上(坡度)小.
而且, 虽然该函数的最小值在(x,y)=(0,0), 但是梯度的很多地方没有指向(0,0)
假设从(x,y)=(-7.0,2.0)处(初始值)开始搜索, 则SGD呈Z字形移动, 这是非常低效的.
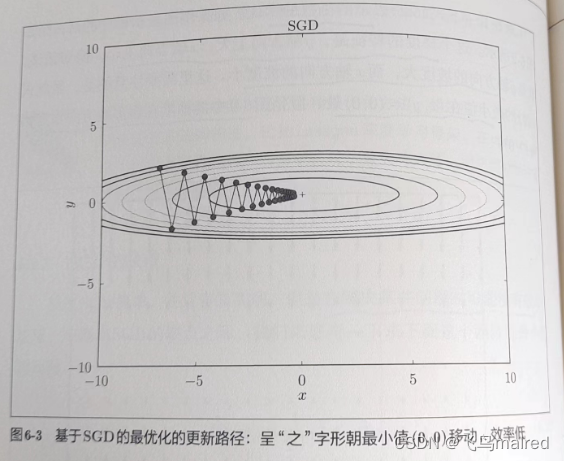
SGD的缺点是, 如果函数的形状非均向(anisotropic), 比如呈延伸状, 搜索的路径就会很低效
SGD低效的根本原因是, 梯度的方向没有指向最小值的方向
所以我们有Momentum、AdaGrad、Adam等方法取代SGD
6.1.4 Momentum(“动量”)
ϑ
←
α
ϑ
−
η
∂
L
∂
W
(6.3)
\vartheta \gets \alpha \vartheta - \eta \frac{\partial L}{\partial W} \tag{6.3}
ϑ←αϑ−η∂W∂L(6.3)
W
←
W
+
α
(6.4)
W\gets W+\alpha \tag{6.4}
W←W+α(6.4)
W 是需要更新的权重参数 , 损失函数关于 W 的梯度记为 ∂ L ∂ W , η 表示学习率 , 变量 v 对应物理上的速度 , 表示了物体在梯度方向上受力 , 在力的作用下速度增加的物理法则 W是需要更新的权重参数, 损失函数关于W的梯度记为 \frac{\partial L}{\partial W} , \eta 表示学习率 , 变量v对应物理上的速度, 表示了物体在梯度方向上受力, 在力的作用下速度增加的物理法则 W是需要更新的权重参数,损失函数关于W的梯度记为∂W∂L,η表示学习率,变量v对应物理上的速度,表示了物体在梯度方向上受力,在力的作用下速度增加的物理法则
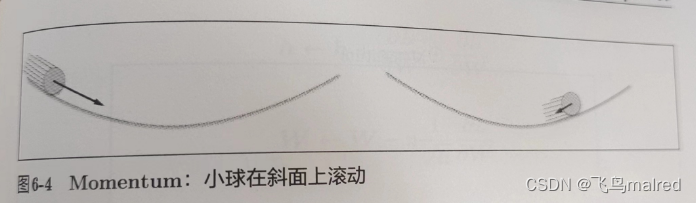
α 表示物理上的地面摩擦力或空气阻力 , 在物体不受力时使其减速 ( 设为 0.9 之类的值 ) \alpha 表示物理上的地面摩擦力或空气阻力, 在物体不受力时使其减速(设为0.9之类的值) α表示物理上的地面摩擦力或空气阻力,在物体不受力时使其减速(设为0.9之类的值)
# momentum 动量
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
相比SGD, z字形滚动的程度减轻了, 因为一直在x轴方向上受力, 虽小但是叠加加速, 而y轴力虽然大, 但是正反方向的力会抵消
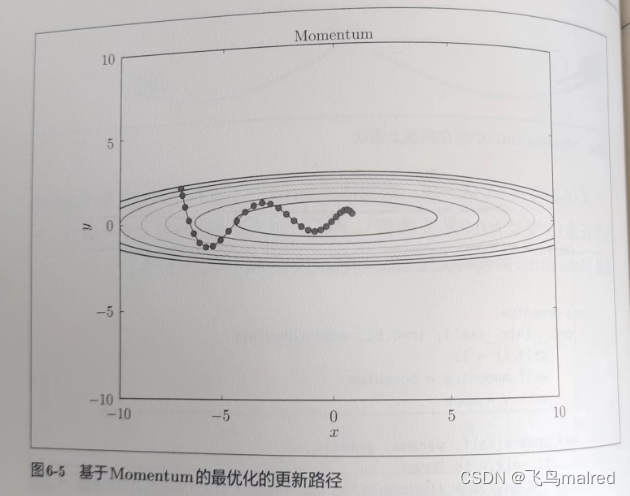
6.1.5 AdaGrad
神经网络中学习率过小会花费过多时间, 学习率过大会导致学习发散
学习率衰减 (learning rate decay) 是一种技巧, 即随着学习的进行, 使学习率逐渐减小
学习率衰减针对全体参数, 而AdaGrad则进一步, 针对每个参数进行定制的处理
AdaGrad会为参数的每个元素适当地调整学习率, Ada=Adaptive, 即适当的意思
h
←
h
+
δ
L
δ
W
⨀
δ
L
δ
W
h \gets h + \frac{\delta L}{\delta W} \bigodot \frac{\delta L}{\delta W}
h←h+δWδL⨀δWδL
W
←
W
−
η
1
h
δ
L
δ
W
W \gets W - \eta \frac{1}{\sqrt{h}} \frac{\delta L}{\delta W}
W←W−ηh1δWδL
W : 要更新的权重参数 , δ L δ W 表示损失函数关于 W 的梯度 , η 表示学习率 , 变量 h 保存了以前所有梯度值的平方和 , ⨀ 表示矩阵乘法 , 在更新参数时 , 通过乘以 1 h , 就可以调整学习的尺度 , 参数的元素中变动较大的元素学习率将变小 W: 要更新的权重参数, \frac{\delta L}{\delta W} 表示损失函数关于W的梯度, \eta表示学习率, 变量h保存了以前所有梯度值的平方和, \bigodot 表示矩阵乘法, 在更新参数时, 通过乘以 \frac{1}{\sqrt{h}}, 就可以调整学习的尺度, 参数的元素中变动较大的元素学习率将变小 W:要更新的权重参数,δWδL表示损失函数关于W的梯度,η表示学习率,变量h保存了以前所有梯度值的平方和,⨀表示矩阵乘法,在更新参数时,通过乘以h1,就可以调整学习的尺度,参数的元素中变动较大的元素学习率将变小
- AdaGrad会记录过去所有梯度的平方和, 学习越深入, 更新幅度就越小, 但是, 如果持续不断下去, 学习率就可能变为0.
- 可以使用RMSProp方法来改善, 它不会将过去的梯度全部一视同仁地加起来, 而是会逐渐遗忘过去的梯度,
加法运算时将新梯度的信息更多地反映出来
这种操作称为"指数移动平均", 呈指数函数式地减小过去的梯度
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for k, v in params.items():
self.h[k] = np.zeros_like(v)
for k in params.keys():
self.h[k] += grads[k] * grads[k]
# 加上1e-7这个微小值是为了防止self.h[key]中有0时, 将0用作除数的情况
params[k] -= self.lr * grads[k] / (np.sqrt(self.h[k]) + 1e-7)
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
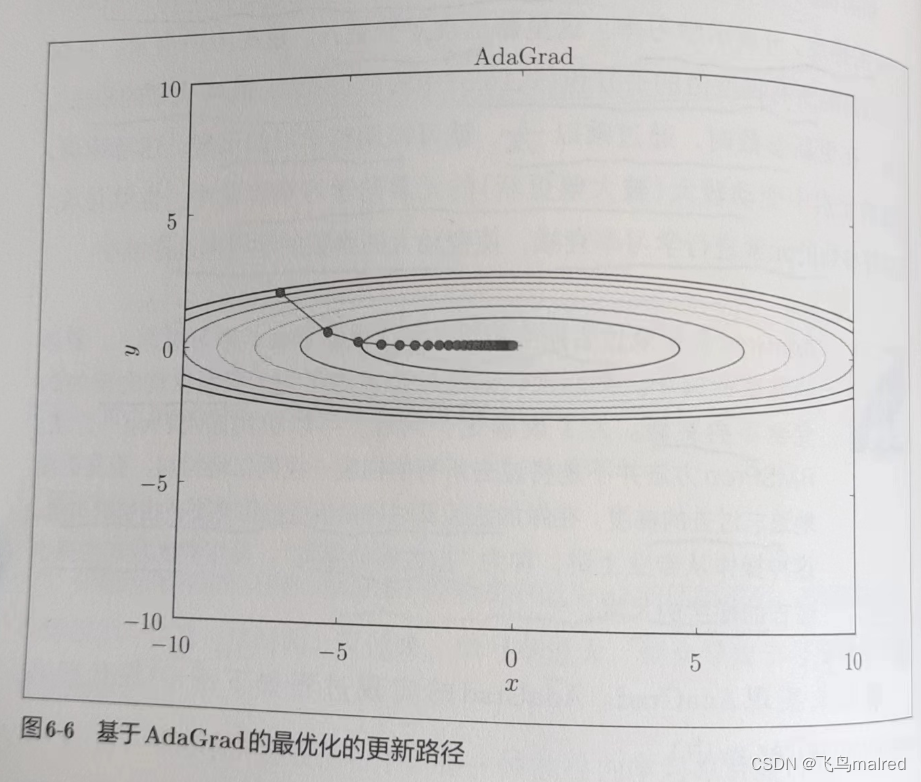
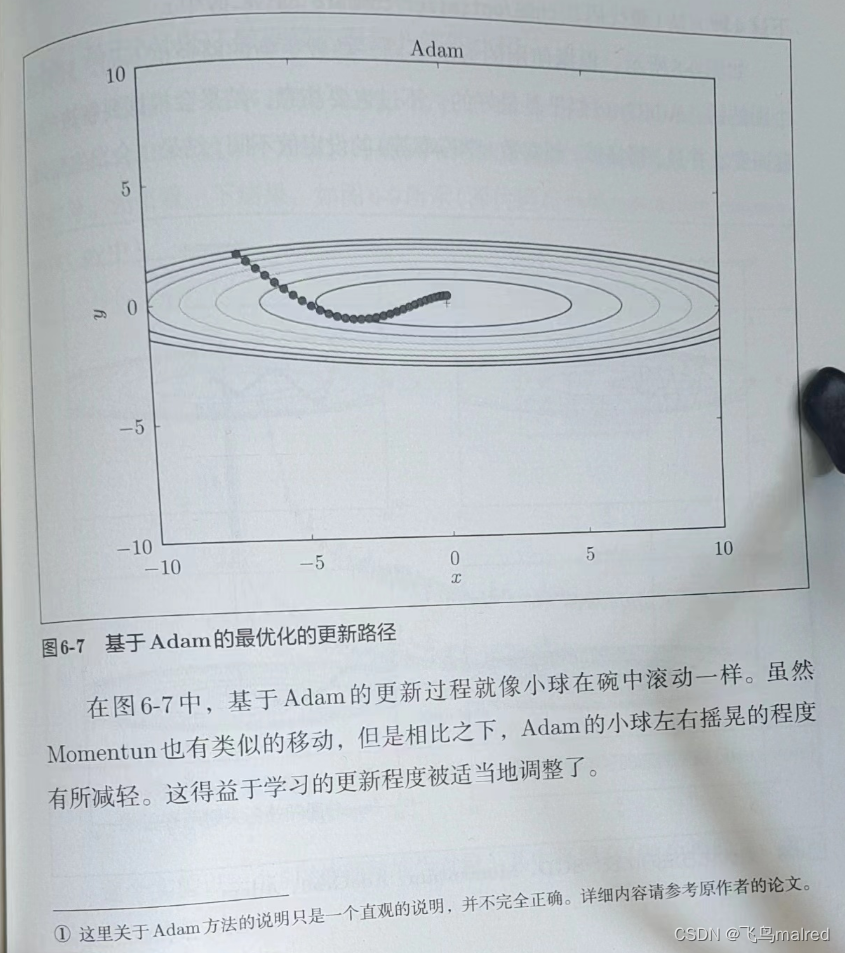
6.1.6 Adam
Adam是2015年提出的新方法, 直观地说, 就是融合了Momentum和AdaGrad的方法, 组合它们的优点, 有望实现参数空间的高效搜索
此外, 进行超参数的"偏置校正"也是Adam的特征
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]
#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias
#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias
#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)
- Adam会设置3个超参数, 一个是学习率, 另外两个是一次momentum系数β1和二次momentum系数β2,
标准的设定值是β1=0.9,β2=0.999
6.1.7 使用哪种方法呢
目前介绍的4种方法各有优点, 根据具体场景进行选择, 而最近也有很多人喜欢用Adam, 本书主要用SGD或Adam
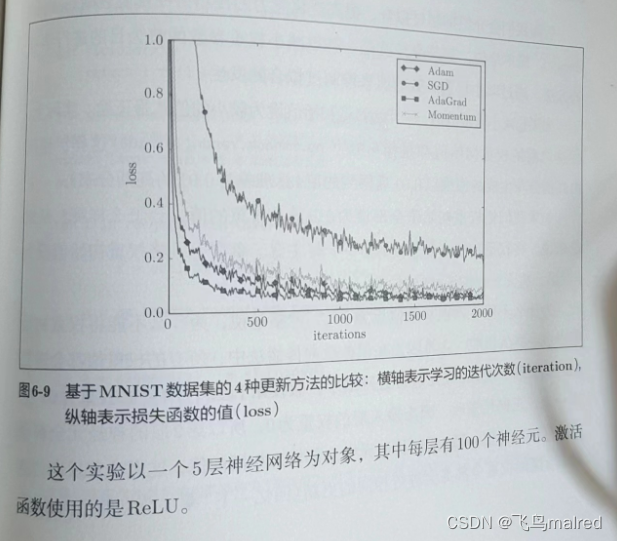
6.1.8 基于MNIST数据集的更新方法的比较
一般而言, 与SGD相比, 其他3种方法可以学习得更快
6.2 权重的初始值
6.2.1 可以将权重初始值设为0吗
抑制过拟合, 提高泛化能力的技巧 ———— 权值衰减 _(weight decay_), 简单地说就是一种以减少权重参数的值为目的进行学习的方法
如果想减小权重的值, 一开始应该设置较小的初始值, 比如0.01 * np.random.randn((10, 100))这样的,
表示用高斯分布生成的值乘以0.01后得到的值 ((标准差为0.01的高斯分布))
那么为什么不设置初始值为0或者全都一样的值呢?
因为在误差反向传播法中, 假设1、2层的权重都为0, 那么正向传播时, 因为输入层的权重为0, 所以第2层的神经元全部会被传递相同的值.
第2层神经元全部输入相同的值, 意味着反向传播时第2层的权重都会进行相同的更新, 权重就被更新为相同的值, 并拥有了对称的值((
重复的值))
这使得神经网络拥有许多不同的权重的意义丧失了, 为了防止"权重均一化"((严格地说, 为了瓦解权重的对称结构)), 必须随机生成初始值
6.2.2 隐藏层的激活值的分布
观察隐藏层的激活值((激活函数的输出数据))的分布, 观察权重初始值如何影响隐藏层的激活值的分布.
实验: 向一个5层神经网络((激活函数为sigmoid))传入随机生成的输入数据, 用直方图绘制各层激活值的数据分布.
该实验参考了斯坦福大学CS231n
# 6_与学习有关的技巧/2_weight_init_activation_histogram.py
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.random.randn(1000, 100) # 随机生成1000个数据(1000*100的矩阵)
node_num = 100 # 各隐藏层的节点(神经元)数
hidden_layer_size = 5 # 隐藏层有5层
activations = {} # 保存激活值的结果
for i in range(hidden_layer_size):
if i != 0:
# 使用上一层的激活值作为输入
x = activations[i - 1]
w = np.random.randn(node_num, node_num) * 1
z = np.dot(x, w)
a = sigmoid(z)
activations[i] = a
# 绘制直方图
for i, a in activations.items():
plt.subplot(1, len(activations), i + 1)
plt.title(str(i + 1) + "-layer")
plt.hist(a.flatten(), 30, range=(0, 1))
plt.show()
这里设5层神经网络, 每层100个神经元, 随机1000个数据((服从正态((高斯))分布))作为输入, 激活函数用sigmoid
这里需要注意权重的尺度, 我们使用标准差为1的高斯分布, 目的是通过改变尺度((标准差)), 观察激活值的分布如何变化
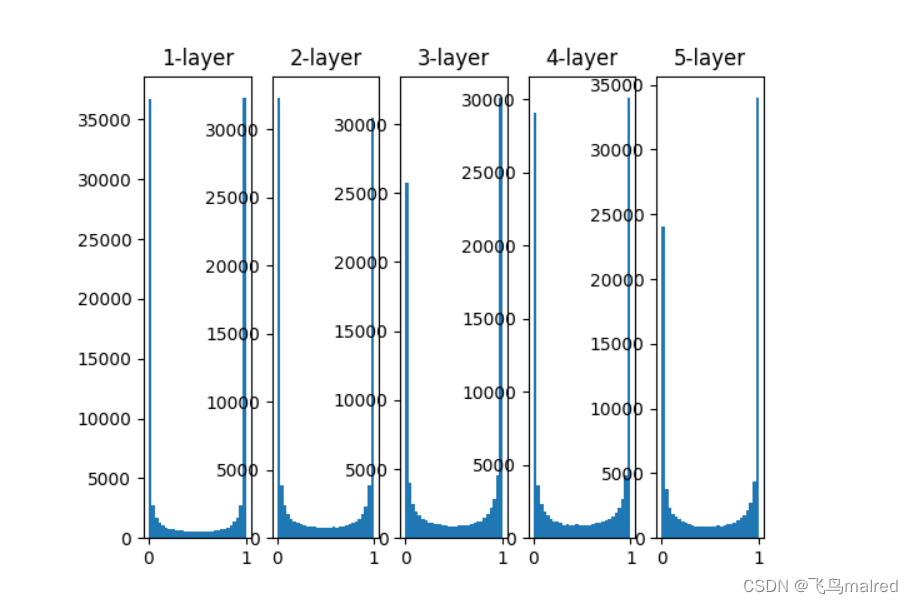
各层的激活值偏向0和1的分布. sigmoid是S型函数, 当输出不断靠近0或1, 它的导数的值逐渐接近0.
因此, 偏向0和1的数据分布会造成反向传播中梯度的值不断变小, 最后消失
这个问题称为梯度消失((gradient vanishing))
将标准差设为0.01, 进行相同的实验, 观察结果
# w = np.random.randn(node_num, node_num) * 1
w = np.random.randn(node_num, node_num) * 0.01
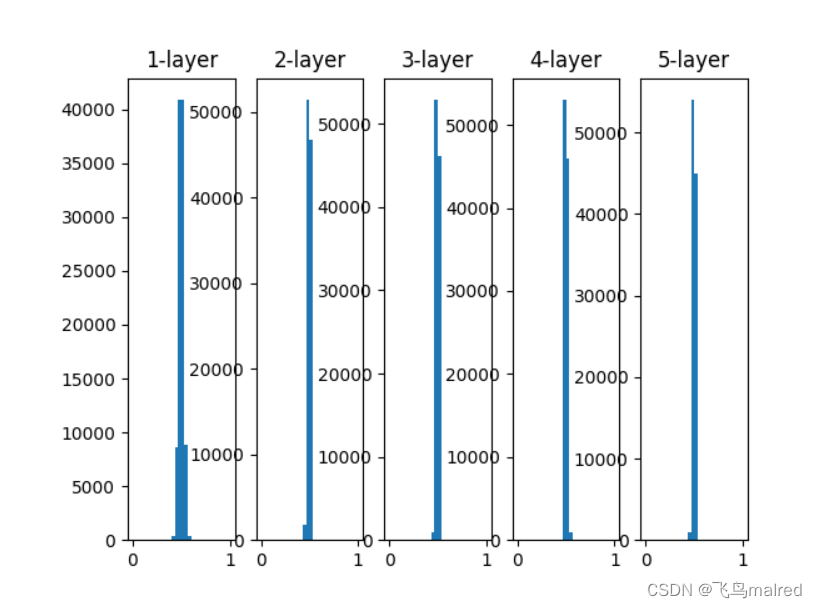
这次呈集中在0.5附加的分布, 不会发生梯度消失问题. 但是激活值的分布有所偏向((0.5)), 说明表现力上会有很大问题.
如果有多个神经元都输出几乎相同的值, 那么就没有意义了, 因为100个相同输出的神经元也可以用1个神经元来表达基本相同的事情,
因此, 激活值在分布上有偏向会出现"表现力受限"的问题
- 各层的激活值的分布都要求有适当的广度. 在各层间传递多样性数据有利于高效学习
为了使各层的激活值呈现出相同广度的分布, 我们尝试使用Xavier Glorot等人的论文中推荐的权重初始值((Xavier初始值))
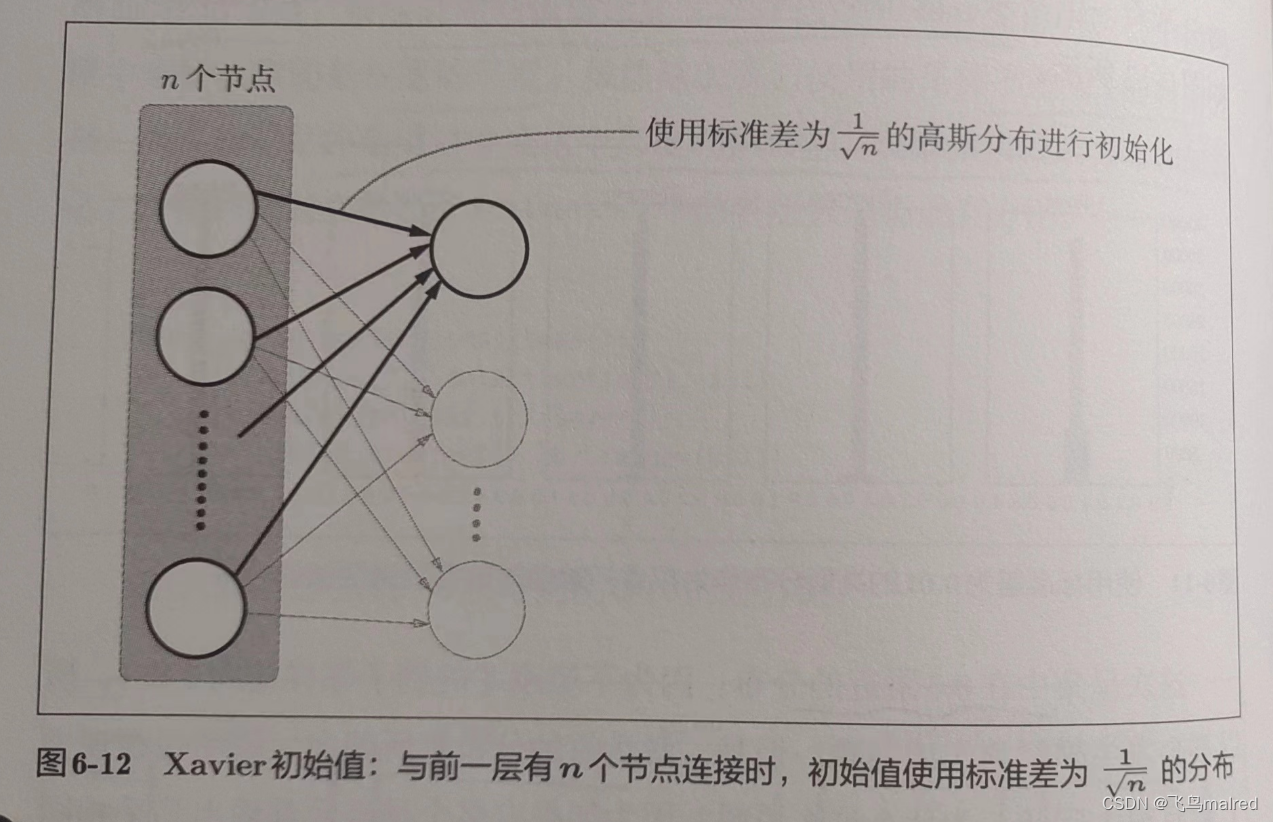
使用Xavier初始值, 前一层节点数越多, 要设定为目标节点的初始值的权重尺度就越小.
# 书上说因为所有层的节点数都是100, 所以简化了实现
w = np.random.randn(node_num, node_num) / np.sqrt(node_num)
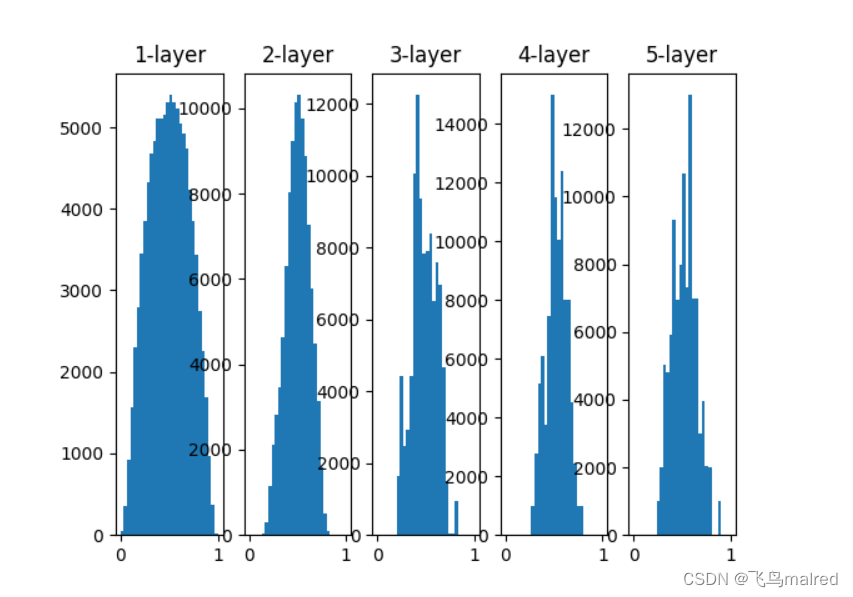
可以看出, 激活值比之前呈现更有广度的分布.
- 在图6-13中, 后面的层的分布出现歪斜的形状, 如果用tanh函数((双曲线函数)), 则会呈现吊钟型分布, tanh的图像也是S型曲线,
但是sigmoid函数关于((x,y))=((0,0.5))对称, tanh则是关于原点((0.0))对称, 而激活函数最好选择具有关于原点对称的特性的
6.2.3 ReLU的权重初始值
Xavier初始值是以激活函数是线性函数为前提而推导出来的, sigmoid函数和tanh函数左右对称, 且中央附近可以视作线性函数,
所以适合Xavier初始值.
当激活函数使用ReLU, 则推荐使用Kaiming He等人推荐的初始值, “He初始值”, 当前一层节点数为n, He初始值使用标准差为
{% mathjax %} \sqrt[]{ \frac{2}{n}} {% endmathjax %}的高斯分布.
可以直观上解释为, 因为ReLU的负值区域的值为0, 为了使他更有广度, 所以需要2倍于Xavier初始值的系数
以下是3个实验, 权重初始值依次是 1. 标准差为0.01的高斯分布((下文简写"std=0.01")), 2. Xavier初始值, 3. He初始值
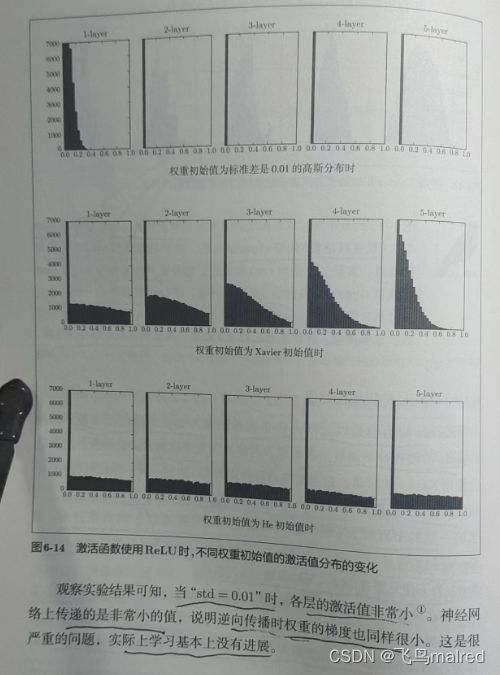
当使用Xavier初始值时, 层次越深, 激活值偏向越大, 容易出现梯度消失的问题.
而使用He初始值时, 各层中分布的广度相同, 即时层次加深也保持数据广度, 因此在逆向传播时也能传递合适的值.
总结((目前的最佳实践)): 激活函数使用ReLU, 权重初始值使用He初始值; 激活函数用sigmoid或tanh等S型曲线函数, 则使用Xavier初始值
6.2.4 基于MNIST数据集的权重初始值的比较
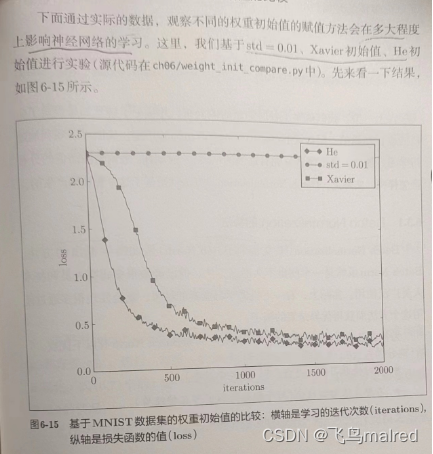
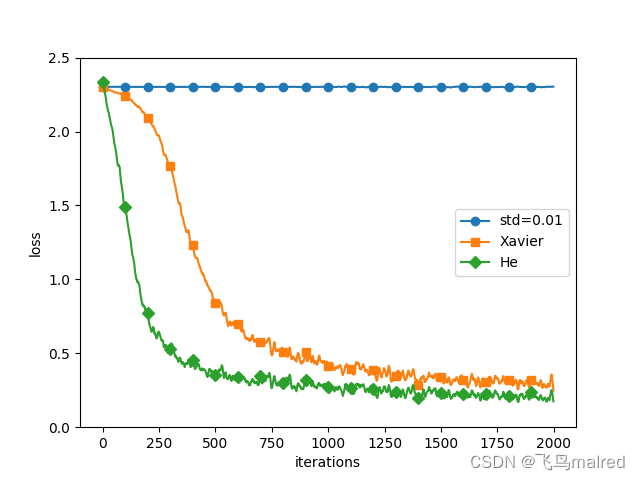
6.3 Batch Normalization
上一章讲述了我们通过合适的权重初始值可以使各层激活值拥有适当的广度, 那么如果"强制地"调整激活值的分布又会怎样?
Batch Normalization方法就是基于这个想法而产生的
6.3.1 Batch Normalization 的算法
- 内心os: 数学式子不用特意写latex, 直接用本地解析器解析然后截图不就好了… 之前还特意写, 心累
Batch Normalization(简称Batch Norm)是2015年提出的, 有以下优点
- 可以使学习快速进行((可以增大学习率))
- 不那么依赖初始值((对应初始值不用那么神经质))
- 抑制过拟合((降低Dropout等的必要性))
它的思路是调整各层的激活值分布使其拥有适当的广度. 为此, 要向神经网络中插入对数据分布进行正规化的层, 即Batch
Normalization层
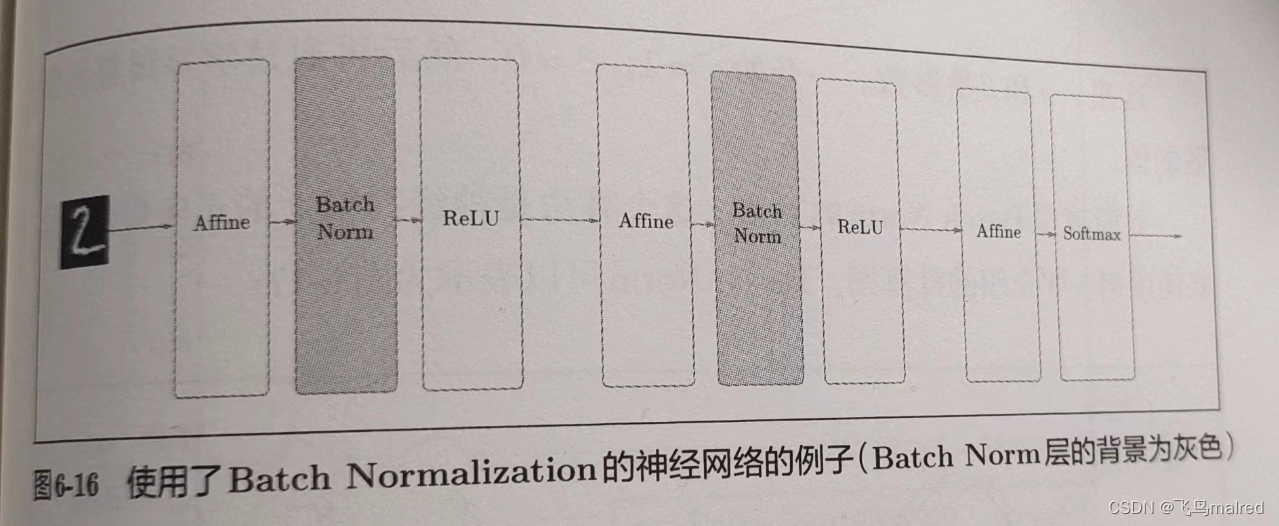
Batch Norm, 以进行学习时的mini-batch为单位, 按mini-batch进行正规化. 就是进行使数据分布的均值为0、方差为1的正规化
μ B ← 1 m ∑ i = 1 m x i \mu_B \gets \frac{1}{m} \sum_{i=1}^m x_i μB←m1i=1∑mxi
σ B 2 ← 1 m ∑ i = 1 m x i − μ B 2 \sigma^2_B \gets \frac{1}{m} \sum_{i=1}^m xi−μB ^2 σB2←m1i=1∑mxi−μB2
x i ^ ← x i − μ B σ B 2 + ε \hat{x_i} \gets \frac{x_i - \mu_B }{\sqrt[]{\sigma^2_B+ \varepsilon}} xi^←σB2+εxi−μB
这里对mini-batch的m个输入数据的集合B={x1,x2,…,xm}求均值μ 和 σ. 再对输入数据进行均值为0, 方差为1的正规化. з是微小值,
防止出现0的情况
将这个处理插入到激活函数的前面或后面, 可以减少数据分布的偏向. 接着, Batch Norm层会对正规化后的数据进行缩放和平移的变换.
y i ← γ x ^ i + β y_i \gets \gamma \hat{x}_i+ \beta yi←γx^i+β
γ和β是参数, 一开始γ=1, β=0, 然后通过学习调整到合适的值
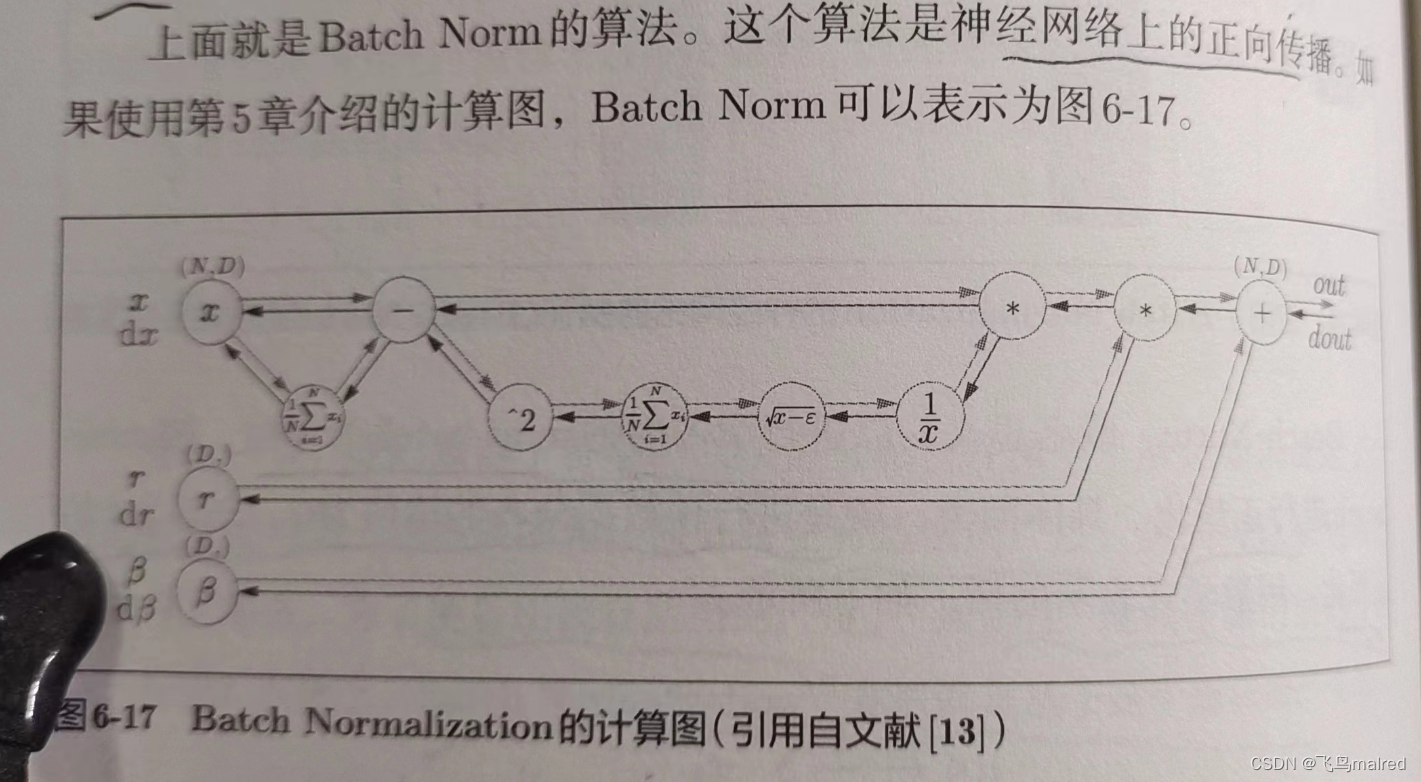
Batch Norm的反向传播可以看Frederik Kratzert的博客"Understanding the backward pass through Batch Normalization Layer"
6.3.2 Batch Normalization的评估
使用Batch Norm层进行实验((源代码: ch06/batch_norm_test.py))
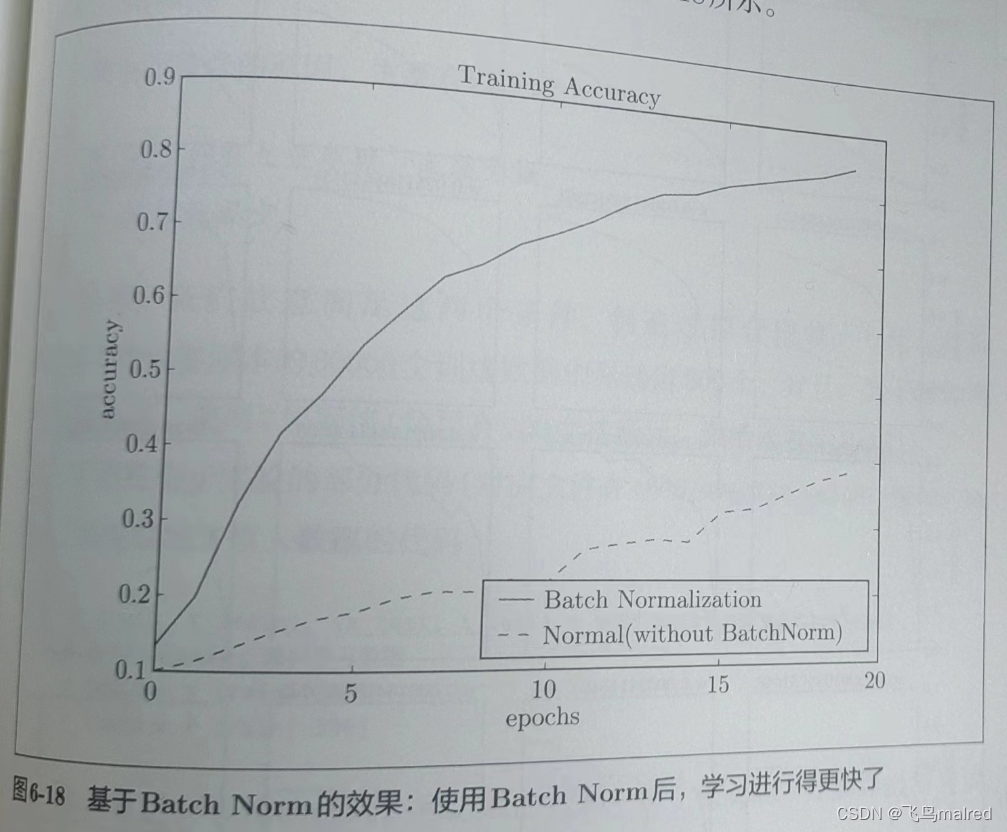
使用Batch Norm后, 学习得更快. 下面的实验给予不同的初始值尺度, 观察效果.
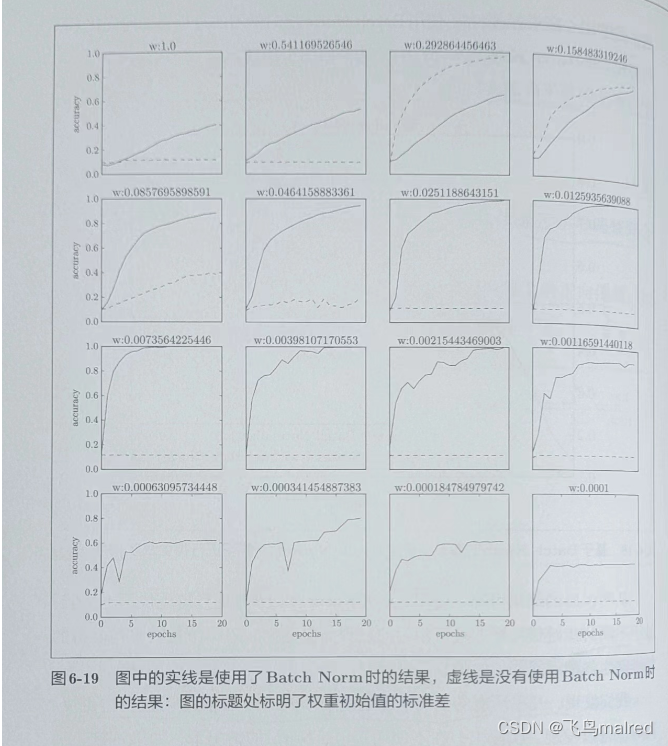
几乎所有使用Batch Norm的学习都更快, 而如果没有好的初始值, 又不使用Batch Norm, 学习将无法进行
综上, Batch Norm可以推动学习进行, 并且, 对权重初始值健壮((即不那么依赖初始值)).
6.4 正则化
过拟合指的是只能拟合训练数据, 但是不能很好地拟合不包含在训练数据中的其他数据的状态.
机器学习的目标是提高泛化能力, 即便是没有包含在训练数据里的未观测数据, 也希望模型可以进行正确的识别
6.4.1 过拟合
发生过拟合的原因主要有
- 模型拥有大量参数、表现力强
- 训练数据少
我们从MNIST数据集只拿300个((满足’训练数据少’)), 使用7层网络, 每层100个神经元, 激活函数ReLU((满足’拥有大量参数’)), 进行训练
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import SGD
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 为了再现过拟合, 减少学习数据
x_train = x_train[:300]
t_train = t_train[:300]
# 神经网络
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10)
# 优化器
optimizer = SGD(lr=0.01) # 学习率为0.01的SGD更新参数
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
grads = network.gradient(x_batch, t_batch)
# 更新梯度
optimizer.update(network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
# 绘制图形
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
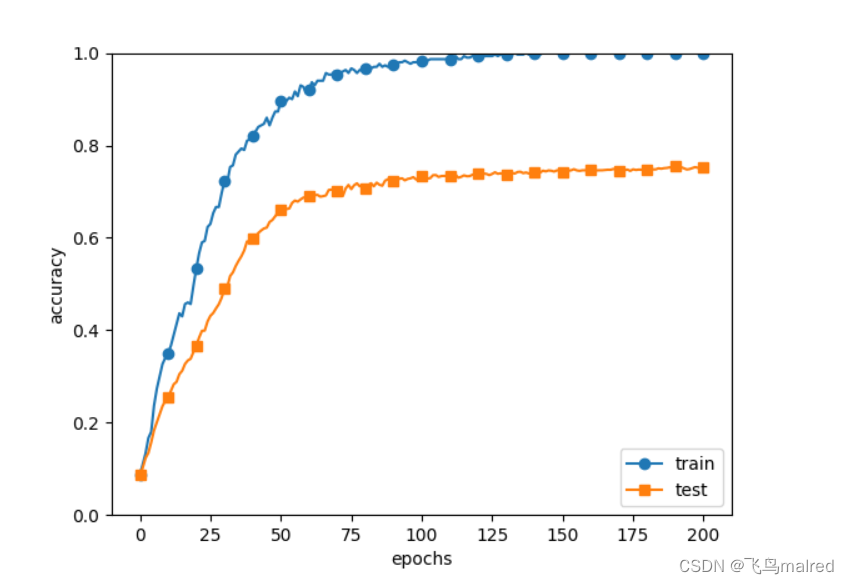
可以看出, 过了100个epoch后, 用训练数据的识别精度几乎都接近100%, 但是测试数据则差很多, 这是因为只拟合了训练数据,
而对没有使用的一般数据((测试数据))拟合得不好
6.4.2 权值衰减
很多过拟合是因为权值参数取值过大发生的, 所以权值衰减通过在学习过程中对大的权重进行惩罚来抑制过拟合
神经网络的学习目的是减小损失函数的值, 如果为损失函数加上权重的平方范数((L2范数)), 就可以抑制权重变大.



- 除了 L 2 范数 , 还有 L 1 和 L ∞ 范数 , 假设有 W = ( w 1 , w 2 , . . . ) , 则 L 2 范数是各个元素的平方和 : w 1 2 + w 2 2 + . . . + w n 2 ; 除了L2范数, 还有L1和L∞范数, 假设有W=(w1,w2,...), 则L2范数是各个元素的平方和: \sqrt[]{w_1^2+w_2^2+...+w_n^2}; 除了L2范数,还有L1和L∞范数,假设有W=(w1,w2,...),则L2范数是各个元素的平方和:w12+w22+...+wn2;
- 而 L 1 范数是各个元素的绝对值之和 : ∣ w 1 2 ∣ + ∣ w 2 2 ∣ + . . . + ∣ w n 2 ∣ ; 而L1范数是各个元素的绝对值之和: \vert w_1^2 \vert + \vert w_2^2 \vert +...+ \vert w_n^2 \vert; 而L1范数是各个元素的绝对值之和:∣w12∣+∣w22∣+...+∣wn2∣;
- L ∞ 范数也称 M a x 范数 , 是各个元素的绝对值中最大的一个 , 这几个范数都可以用作正则化项 L∞范数也称Max范数, 是各个元素的绝对值中最大的一个, 这几个范数都可以用作正则化项 L∞范数也称Max范数,是各个元素的绝对值中最大的一个,这几个范数都可以用作正则化项
为刚才的实验使用λ=0.1的权值衰减((common/multi_layer_net.py, ch06/overfit_weight_decay.py))
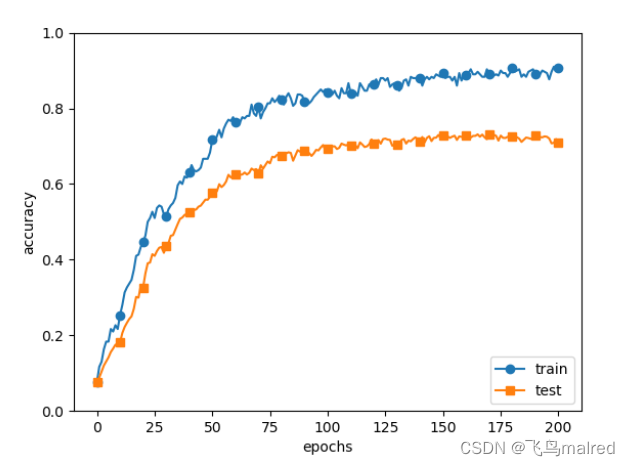
可以看到训练数据和测试数据的识别精度之间的差距变小了, 说明过拟合被抑制了, 而且训练数据的识别精度没有到100%
6.4.3 dropout
当模型变得复杂时, 只用权值衰减难以抑制过拟合, 所以有了dropout方法
Dropout是在学习过程中随机删除神经元的方法, 被删除的神经元不再进行信号传递, 而测试时, 虽然传递所有信号, 但是对各个神经元的输出,
会乘上训练时的删除比例后输出
如果训练时进行恰当的计算, 正向传播时就单纯传递数据就行, 不用乘删除比例, 所以深度学习框架作了这样的实现,
高效的实现可以参考Chainer中实现的Dropout
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
# 生成和x一样形状的数组, 并将值大于dropout的元素设为true
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
每次正向传播时, self.mask都会以False的形式保留要删除的神经元. self.mask会随机生成和x形状相同的数组,
将值大于dropout_radio的元素设为True.
反向传播时的行为和ReLU相同, 正向传播时传递了信号的神经元, 反向传播时也传递, 正向传播时没传递信号的神经元, 反向传播时不传播
现在使用7层网络, 每层100个神经元, 激活函数为ReLU 来实验
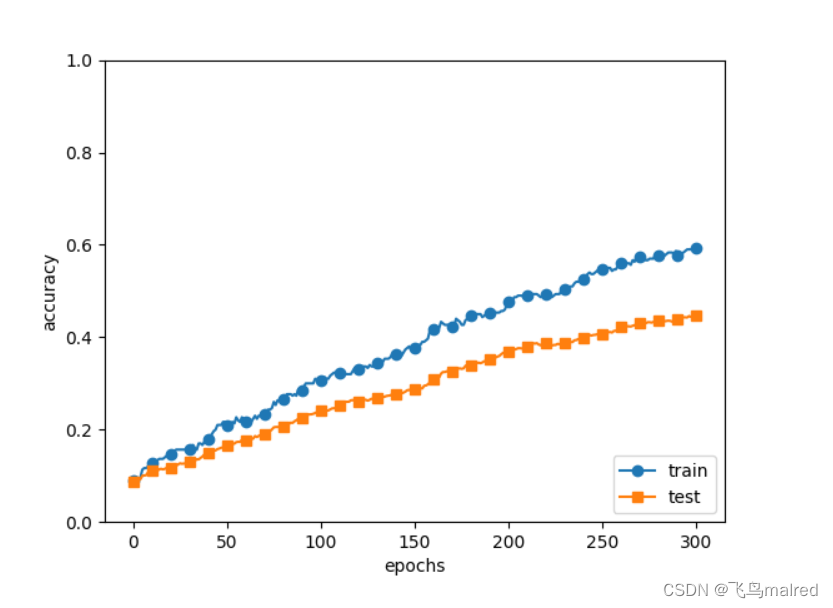
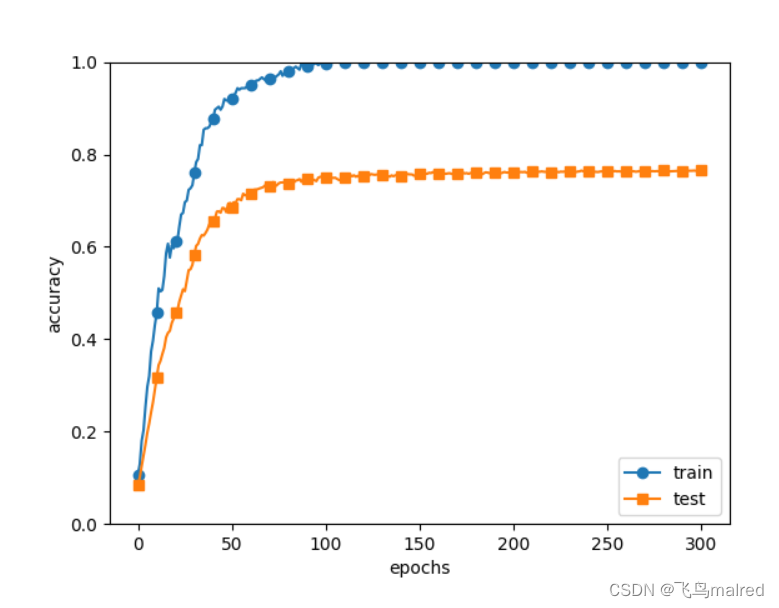
- 机器学习中经常使用集成学习, 就是让多个模型单独进行学习, 推理时再取多个模型的输出的平均值. 通过集成学习,
神经网络的识别精度可以提升好几个百分点.
而可以将dropout理解为, 通过在学习过程中随机删除神经元, 从而每一次都让不同模型进行学习. 推理时, 通过对神经元的输出乘以删除比例,
可以取得模型的平均值.
也就是说, 可以理解成, dropout将集成学习的效果 模拟地 通过一个网络实现了
6.5 超参数验证
超参数((hyper-parameter)), 比如各层神经元数量、batch大小、参数更新时的学习率或权值衰减等。都会影响模型的性能, 但是,
在确定合适的超参数的过程中, 伴随着大量的试错
6.5.1 验证数据
我们将数据集分为测试和训练数据, 但是, 却不能用测试数据来评估超参数的性能, 因为如果用测试数据评估, 那么超参数的值会对测试数据发生过拟合,
导致超参数的值被调整为只拟合测试数据. 所以, 必须使用超参数专用的确认数据, 一般称为验证数据((validation data))
- 训练数据用于参数((权重和偏置))的学习, 验证数据用于超参数的性能评估, 为了确认泛化能力, 要在最后使用测试数据
不同的数据集, 有时候划分为训练、验证、测试数据,有的只分为训练和测试数据,有的不划分数据集,用户需要自行进行分割。
对于MNIST数据集,我们从训练数据中分割20%作为验证数据
from dataset.mnist import load_mnist
from common.util import shuffle_dataset
(x_train, t_train), (x_test, t_test) = load_mnist()
# 打乱训练数据
x_train, t_train = shuffle_dataset(x_train, t_train)
# 分割验证数据
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
这里在分割数据前,先打乱了输入数据和监督标签,因为数据可能存在偏向(比如数据从0~10按顺序排列等)。
6.5.2 超参数的最优化
- 有报告显示,进行神经网络超参数最优化时,与网格搜索等有规律的搜索相比,随机采样的搜索方式效果更好。因为多个超参数中,各个超参数对最终的识别精度的影响程度不同
超参数的范围只需要大致地指定,像0.001(103)到1000(103)这样,
以“10的阶乘”的尺度指定范围(也表述为“用对数尺度(log scale)指定”)
深度学习需要很长时间(甚至几天或几周)。因此,超参数搜索时,需要尽早放弃不符合逻辑的超参数。
于是,在超参数的最优化中,减少学习的epoch,缩短一次评估所需的时间是不错的方法
- 步骤0:设定超参数的范围
- 步骤1:从设定的超参数范围中随机采样
- 步骤2:使用步骤1中采样到的超参数的值进行学习,通过验证数据评估识别精度(但是要将epoch设置得很小)
- 步骤3:重复步骤1、2(100次等),根据识别精度的结果,缩小超参数的范围,最后从中选择最好的超参数
- 这里介绍的超参数最优化方法是实践性的方法。与其说是科学方法,不如说有些实践经验的感觉。如果需要更精炼的方法,可以使用
贝叶斯最优化
(Bayesian optimization)。贝叶斯最优化运用以贝叶斯定理为中心的数学理论,能够更严密、高效地进行最优化
6.5.3 超参数最优化的实现
我们使用MNIST数据集实验。将学习率和控制权值衰减强度的系数(“权值衰减系数”)这两个超参数的搜索问题作为对象。
这个问题的设定和解决思路参考了斯坦福大学的课程“CS231n”
在该实验中,权值衰减系数的初始范围为10-8到10-4,学习率的初始范围为10-6到10-2,进行随机采样
weight_decay = 10 ** np.random.uniform(-8, -4) # 10^-8 ~ 10^-4
lr = 10 ** np.random.uniform(-6, -2) # 10^-6 ~ 10^-2
随机采样后再使用这些值进行学习,观察合乎逻辑的超参数。这里省略了实现,源码在ch06/hyperparameter_optimization.py
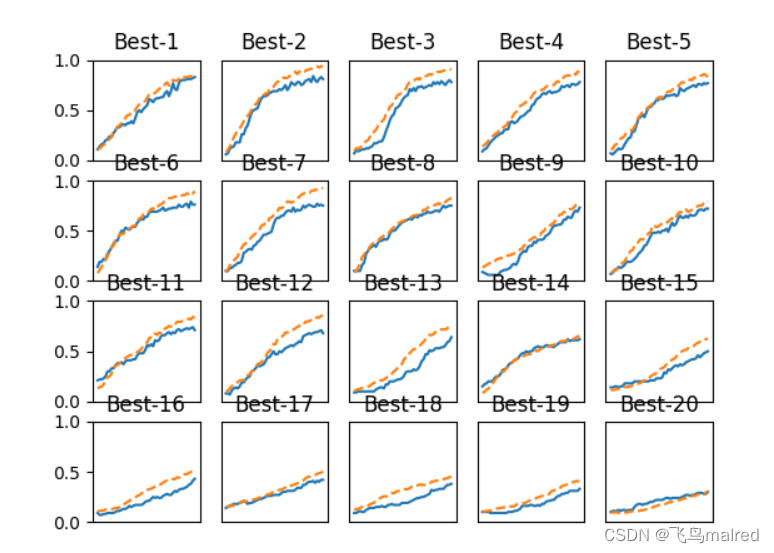
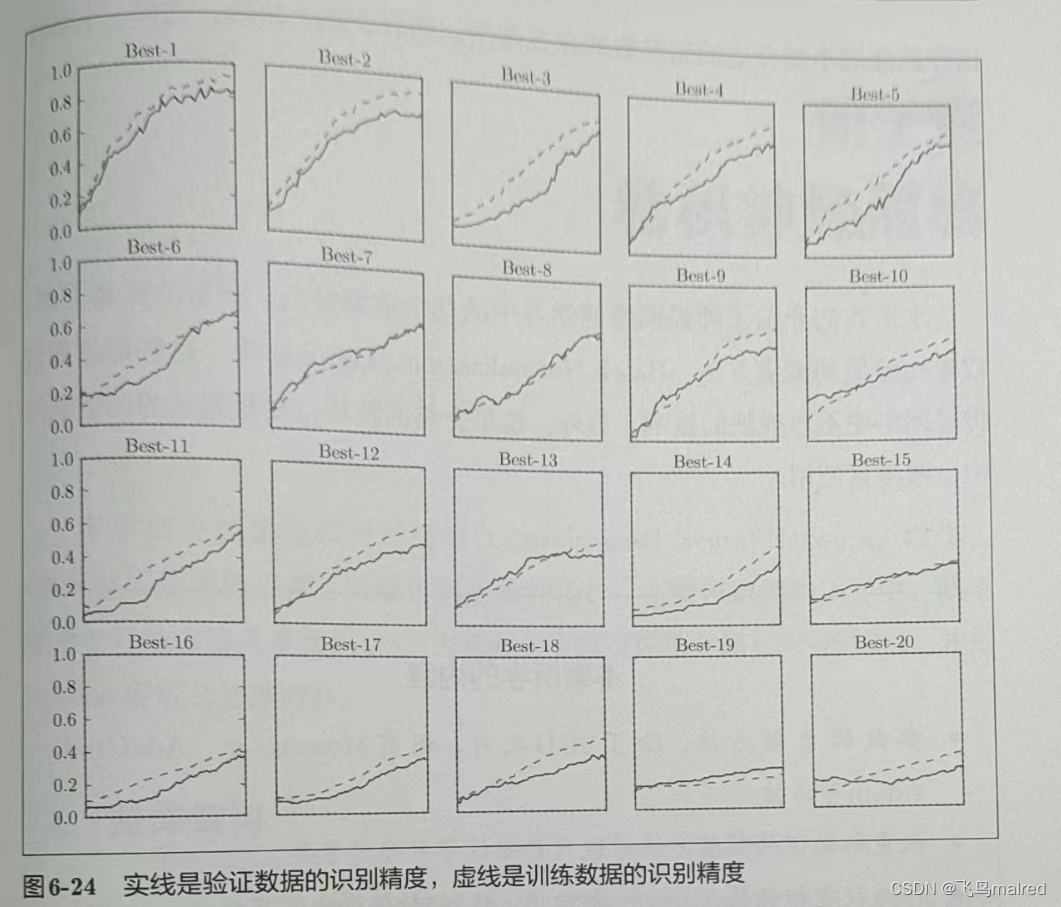
图中按识别精度从高到低排列了验证数据的学习的变化。直到Best-5左右,学习进行得都很顺利,观察一下它之前的超参数的值

可以看出学习率在0.001到0.01、权值衰减系数在10-8到10-6之间时,学习可以顺利进行。像这样,不断缩小范围,最后决定超参数的值
6.6 小结
本章介绍了神经网络的学习中的几个重要技巧。参数的更新方法、权重初始值的赋值方法、Batch Normalization、Dropout等。
本章所学的内容
- 参数的更新方法,除了SGD之外,还有Momentum、AdaGrad、Adam等方法
- 权重初始值的赋值方法对进行正确的学习非常重要
- 作为权重初始值,Xavier初始值、He初始值等比较有效
- 通过使用Batch Normalization,可以加速学习,并且对初始值变得健壮
- 抑制过拟合的正则化技术有权值衰减、Dropout等
- 逐渐缩小“好值”存在的范围是搜索超参数的一个有效方法