0.相关概念
1.什么是NameNode?
NameNode是整个文件系统的管理节点,它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。并接收用户的操作请求。
2.SecondaryNameNode的主要作用?
SecondaryNameNode定期合并fsimage和edits日志,将edits日志文件大小控制在一个限度下。
1.HDFS写入流程(hdfs dfs -put /a.avi /aaa/bbb)
- (0)HDFS的客户端可以创建FileSystem对象实例,该类中封装了HDFS文件系统操作的相关操作。
- (1)客户端Client通过调用FileSystem对象的create()方法,通过RPC向NameNode发起文件上传请求,NameNode执行各种检查判断:目标文件是否存在,父目录是否存在以及客户端是否具有创建文件的权限,并返回是否可以上传,可以则会返回FSDataOutputStream输出流对象给客户端用于写数据。
- (2)客户端Client将文件进行切分,切分为几个数据块
- (3)客户端请求第一个数据块block该传到哪些DataNode服务器上。
- (4)NameNode会返回可用的DataNode的地址
- (5)客户端通过FSDataOutputStream开始请求向第一个DataNode上传数据,第一个DataNode收到请求后会向第二个DataNode请求,直到整个通信管道pipeline的建立。
- (6)通信管道pipeline建立后,客户端开始向第一个DataNode上传第一个数据块,在上传的过程中会将数据拆分为一个个数据包packet,默认大小为64k,第一个DataNode收到packet后会传给第二个DataNode,再传给第三个DataNode。
- (7)数据以packet大小在通信管道上传输着,在传输的反方向上,会通过ACK应答机制校验数据包是否传输成功,最后由pipeline第一个DataNode结点将ack消息发送给客户端Client。
- (8)当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个 block 到服务器,待所有的数据块传输完成后,FSDataOutputStream调用close()方法关闭输出流。

1.HDFS读取流程(hdfs dfs -get /aaa/bbb/a.avi /)
- (1)Client会向NameNode发起RPC请求,NameNode接收读取的请求,然后检查用户是否具有读取数据的权限以及判断在指定路径下是否存在这个文件。
- (2)NameNode会视情况返回文件的部分或者全部的block列表,对于每个block,NameNode都会返回含有该block副本的DataNode地址,这些返回的DataNode地址会按照集群拓扑结构计算出DataNode与客户端的距离,然后进行排序。
- (3)客户端Client选取排序靠前的DataNode读取block,底层本质上是通过类FSDataInputStream建立Socket Stream,重复地调用父类DataInputStream的read方法,直到这个块上的数据读取完毕。
- (4)最终读取来的所有的block会合并成一个完整的文件。

2.NameNode和SecondaryNameNode工作机制
2.1 名词熟悉:
1、元数据
·元数据必须存储在内存当中(保证快速检索);
·元数据必须持久化(保证数据的安全持久);
·将元数据信息保存在fsimage镜像文件当中
2.fsimage文件
·保存元数据信息的文件
·是NameNode中关于元数据的镜像
·包含了NameNode管理下的所有DataNode中文件以及文件Block以及block所在的DataNode的元数据信息
3.Edits文件
·edits编辑日志文件记录了客户端操作元数据的信息
2.2 NameNode端的工作流程
- (0)首先得明白:Namenode始终在内存中保存metadata元数据,用于处理客户端对元数据的增删改查的请求,而Hadoop会维护一个fsimage文件,也就是NameNode中元数据metadata的镜像,但是fsimage并不会随时都与NameNode内存中的元数据metadata保持一致,而是每隔一段时间通过合并edits文件来更新内容。
- (1)第一次启动NameNode格式化后,会创建fsimage镜像文件和edits编辑日志文件(若不是第一次启动,则直接加载fsimage镜像文件和edits编辑日志文件到内存)。
- (2)客户端对元数据发起增删改查的请求。
- (3)NameNode记录操作日志,更新滚动日志
- (4)NameNode对内存中的数据进行增删改查操作。
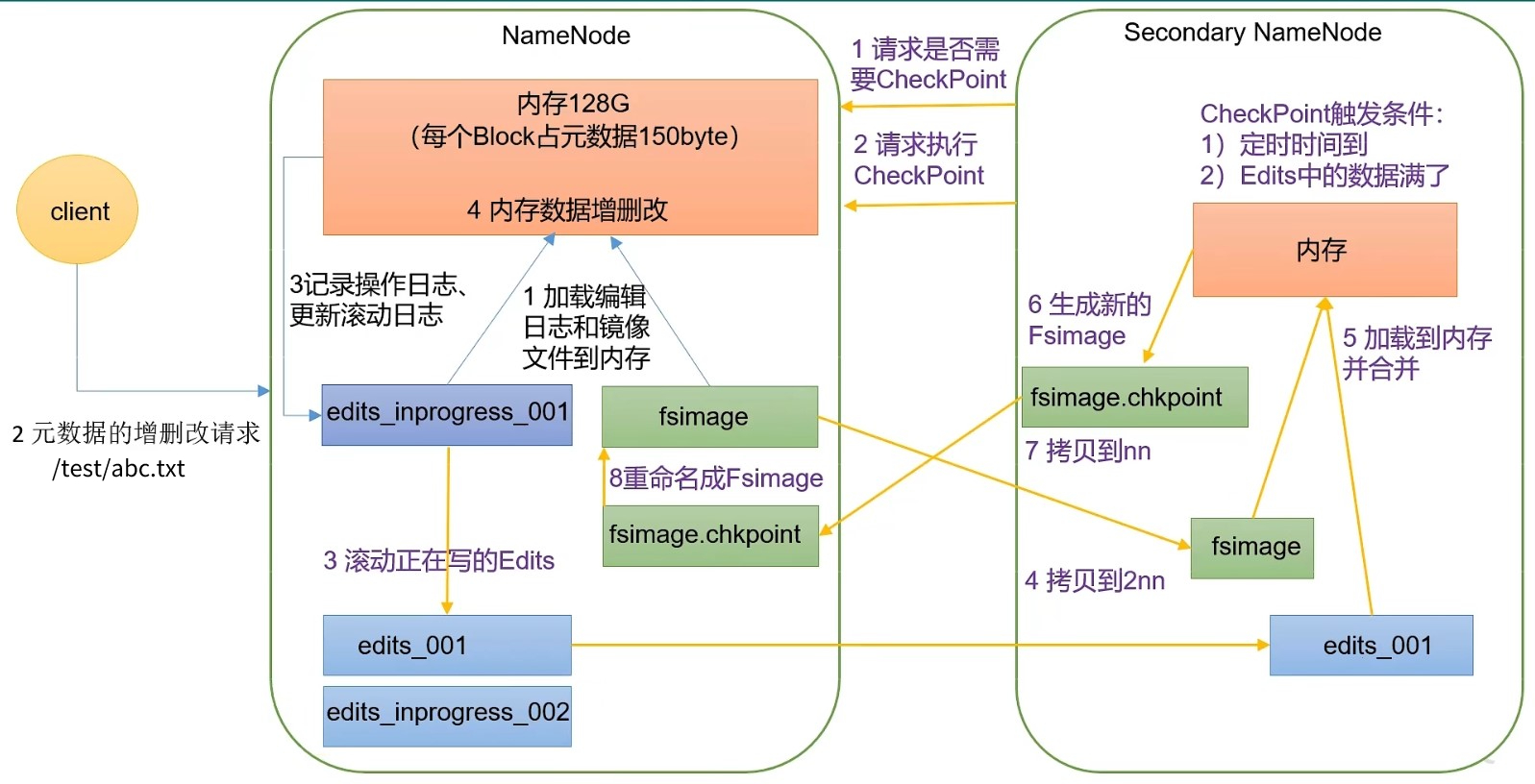
2.3 Secondary NameNode工作流程
- (1)Secondary NameNode询问NameNode是否需要执行checkpoint检查点(默认Edits记录的修改次数达到一定值,或者距离上个checkpoint时间间隔了一定时间)
- Secondary NameNode请求执行check point
- NameNode的edit_inprogress_001(
edits_inprogress_xxx存储的是还没有更新到edits中的数据)中存储的改变向量滚动写入到Edits,如果客户端此时有向NameNode发出改变元数据的请求,那么新的改变向量会被暂时写入到edit_inprogress_002中。 - 将NameNode中的Edits和fsimage拷贝到SecondaryNameNode
- Secondary NameNode将Edits、fsimage信息加载到自己的内存当中,在fsimage基础上顺序执行Edits中改变向量。
- 将内存中的计算结果生成新的镜像文件fsimage.checkpoint
- 将fsimage.checkpoint拷贝给NameNode
- NameNode将fsimage.checkpoint重命名为fsimage,覆盖原有的fsimage
-
Mapreduce流程
- (1)首先会进行分片与格式化数据,将源文件划分成大小相等的数据块,也就是分片spilt,Hadoop会为每一个分片构建一个Map任务,并由该任务运行自定义的map函数,来处理分片里每一条记录.
- (2)格式化操作就是将划分好的分片spilt格式化成键值对<key,value>的形式,其中key代表着偏移量,value代表着每一行的内容,将处理的键值对<key,value>传给mapper函数进行输入
- (3)mapper对传入的键值对<key,value>进行逻辑运算,然后将输出的结果通过context.write输出给outputcollector.
- (4)mapper的输出结果会写到内存当中的环形缓冲区中,在写入环形缓冲区中会按照一定的规则对mapper的输出的键值对进行分区(partitioner),默认情况下是一个分区,那么就只会开启一个reduceTask.
- (5)因此存入环形缓冲区的数据会带有分区的信息,当环形缓冲区的数据达到80%后,会进行溢写操作,在溢写前会进行排序,采取的是快排的方式.
- (6)每次数据量达到环形缓冲区的80%时,就会产生一次溢写,每一次溢写就会产生一个溢写文件,虽然有多个分区,但是这些分区都存储在一个溢写文件当中,只是会将他们分隔开来
- (7)对产生大量的溢写文件会进行合并和排序,由于每一个溢写文件都是有序的,因此溢写文件的内部是有序的,再对这些文件排序时会使用归并排序.
- (8)在进入到reduce之前还可以采用预聚合的方式,对分区内具有相同key的键值对进行聚合.
- (9)reducetask主动拉去指定分区的数据,由于reducetask可能拉取多个分区的,因此还需要对数据进行归并和排序.
Reduce join和map join
reduce join
Map端的主要工作:是通过Mapper阶段将两张表共有的字段作为key,同时处理两张表,通过设置标签Flag的方式来标注不通过数据的来源,将其余字段和新加的标志作为value,最后进行输出.
recude端的主要工作:是在reduce之前,通过共有字段连接连接两张表的工作已经完成,此时在reduce端只需要将不同的来源再分开,最后进行逻辑业务编写就行了.
缺点:这种方式很明显会造成map和reduce端也就是shufflle阶段出现大量的数据传输,效率很低,此外最后的拆分再合并的操作都在reduce阶段完成,reduce端的处理压力很大,而map节点的运算负载很低,资源利用率不高,在reduce阶段极易产生数据倾斜.
map join
map join适用于一张小表和一张大表的场景
使用map join可以将全部的操作都在map阶段执行,不需要使用reduce,所有的工作都在map阶段完成,极大地减少了网络传输和io的代价
- (1)在driver中设置加载缓存文件,这样子每个maptask就都可以获取到该文件,设置reducetask的个数为0,去除掉reduce阶段
- (2)mapper在setup()方法中读取缓存文件,并将结果以kv的形式存入到hashmap当中,方便查找
- (3)在map中正常读取大表,通过hashmap找到对应所需要替换的信息,进行替换,写出结果.
Yarn的工作流程
Yarn是用于进行任务调度和资源管理的框架
Yarn的主要组件为
- ResourceManager:资源管理
- Application Master:任务调度
- NodeManager:节点管理,负责执行任务
工作流程:
- (1)首先客户端Client向ResourceManager提交作业job,调用job.waitForApplication申请作业id
- (2)Resource Manager返回作业id以及作业资源提交路径
- (3)客户端需要上传计算所需资源至ResouceManager指定的路径.
- (4)Client提交完资源后会向Resource Manager发送执行作业请求,ResouceManager收到资源后会创建Application manager来管理这个作业job
- (5)新创建的Application Manager会将job作业添加到Resource Scheduler资源调度器单中,Resource Scheduler内部维护了一个队列,所有需要执行的job都会保存到此队列当中,并按照一定的规则等待执行
- (6)当轮到job执行时,Resource Scheduler会通知Application Manager,Application Manager就会调用分配给它的NodeManager,在NodeManager中会开辟一个容器,并在这个container启动对应所需要执行的job的Application Master
- (7)Application Master会通过HDFS活区之前提交的文件,根据分片信息生成Task
- (8)Application Master会向Resource Manager申请运行Task的任务资源
- (9)Resource Manager会将Task任务分配给空闲的NodeManager
- (10)NodeManager启动Task计算
Hive的工作流程
- (1)Hive通过客户端,包括命令行界面,编程API)等一系列交互接口,接收用户的指定SQL
- (2)使用Hive Driver驱动器解析并转换为内部的数据结构(抽象语法树AST)
- (3)Hive Driver与元数据metastore交互,获取表的元数据信息,包括表的索引,分区和存储位置等
- (4)Hive Driver将AST发送给查询解析器,解析器根据HIveSQL语法和语义规则,生成查询计划,根据查询计划转化成一系列的任务,可以交给mapreduce执行
优缺点
1.优点
1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
2)避免了去写MapReduce,减少开发人员的学习成本。
3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
2.缺点
1.Hive的HQL表达能力有限
(1)迭代式算法无法表达(MapReduce本身就不支持)
(2)数据挖掘方面不擅长
2.Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗