目录
- 一、下载并加载中文数据集
- 二、中文数据集处理
- 1、数据格式
- 2、数据集处理之tokenizer训练格式
- 1)先将一篇篇文本拼凑到一起(只是简单的拼凑一起,用于训练tokenizer)
- 2)将数据集进行合并
- 3、数据集处理之模型(llama2)训练(train.py)格式
- 三、训练一个tokenizer
- 四、使用训练的tokenizer预编码输入数据
- 五、训练llama2模型
- 1、修改参数
- 1)vocab_size
- 2)max_seq_len与batch size
- 3)token
- 2、模型训练
- 3、模型读取与转换
- 1) python 读取bin模型
- 2)python读取pt模型并转为bin
- 4、模型推理
- 1)代码与模型
- 2)编译运行
- 五、拓展
- 1、可自定义参数运行(master分支下的旧tokenizer.bin模型)
- 2、可自定义参数运行(feature/avx2分支下的tokenizer.bin模型)
- 3、上述两种自定义参数运行的差异
- 4、C++读取tokenizer注释
- 5、run.c中的bpe_encode(即tokenizer的具体流程)
- 6、模型推理while (pos < steps) 循环
- 7、tokenizer拓展词汇
好久没更新这个专栏的文章了,今天抽空写了一篇。————2023.12.28
摘要:文体包括新闻,法律文书,公告,广告等,每种文体的书写风格不一样,如果拥有自己的数据集,想针对特定文体来训练一个内容生成的工具,来帮助自己写点文章,如果没接触过AIGC,可能一开始会觉得无所入手,那么希望本文能够帮助到你。本文将基于llama2来教大家如何训练一个内容生成工具,即训练属于自己的AIGC(Artificial Intelligence Generated Content)。
这里需要训练两个模型,一个是tokenizer,一个是llama2模型,我们一个一个来。
看这篇文章之前可以看下以下两篇文章:
- [玩转AIGC]sentencepiece训练一个Tokenizer(标记器)
- [玩转AIGC]如何训练LLaMA2(模型训练、推理、代码讲解,并附可直接运行的kaggle连接)
第一篇是关于如何训练llama2的Tokenizer模型
第二篇是关于如何训练llama2的content generation模型,里面包括了对llama2的代码解析
相关github:
tokenizer: GitHub - google/sentencepiece: Unsupervised text tokenizer for Neural Network-based text generation.
llama2.c: GitHub - karpathy/llama2.c: Inference Llama 2 in one file of pure C
如果没有显卡,可使用kaggle,kaggle的P100 gpu 足矣
可直接运行的kaggle:llama2-c-chinese
一、下载并加载中文数据集
加载中文数据集:
数据来源:
https://github.com/esbatmop/MNBVC
https://huggingface.co/datasets/liwu/MNBVC
简单的加载方式:
from datasets import load_dataset
dataset = load_dataset("liwu/MNBVC", 'law_judgement',cache_dir="./dataset")
# print(next(iter(dataset))) # get the first line)
dataset.save_to_disk('./datasets')
由于law_judgement数据集太大了,要下载很久,所以可以下载小一点的数据集,比如news_peoples_daily
改为news_peoples_daily数据集
from datasets import load_dataset
dataset = load_dataset("liwu/MNBVC", 'news_peoples_daily',cache_dir="./dataset")
# print(next(iter(dataset))) # get the first line)
dataset.save_to_disk('./datasets')
二、中文数据集处理
需要把下载的数据集进行处理,才能用来训练。
1、数据格式
下载后的数据集如下:
获取到的中文数据集需要转换成对应的格式
首先我们借用训练英文时的数据集(TinyStories_all_data),来看下训练llama2时的数据格式,如下(我们取一条数据集出来看看)
{
"story": "\n\nLily and Ben are friends. They like to play in the park. One day, they see a big tree with a swing. Lily wants to try the swing. She runs to the tree and climbs on the swing.\n\"Push me, Ben!\" she says. Ben pushes her gently. Lily feels happy. She swings higher and higher. She laughs and shouts.\nBen watches Lily. He thinks she is cute. He wants to swing too. He waits for Lily to stop. But Lily does not stop. She swings faster and faster. She is having too much fun.\n\"Can I swing too, Lily?\" Ben asks. Lily does not hear him. She is too busy swinging. Ben feels sad. He walks away.\nLily swings so high that she loses her grip. She falls off the swing. She lands on the ground. She hurts her foot. She cries.\n\"Ow, ow, ow!\" she says. She looks for Ben. She wants him to help her. But Ben is not there. He is gone.\nLily feels sorry. She wishes she had shared the swing with Ben. She wishes he was there to hug her. She limps to the tree. She sees something hanging from a branch. It is Ben's hat. He left it for her.\nLily smiles. She thinks Ben is nice. She puts on his hat. She hopes he will come back. She wants to say sorry. She wants to be friends again.",
"instruction": {
"prompt:": "Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would understand. The story should use the verb \"hang\", the noun \"foot\" and the adjective \"cute\". The story has the following features: the story should contain at least one dialogue. Remember to only use simple words!\n\nPossible story:",
"words": [
"hang",
"foot",
"cute"
],
"features": [
"Dialogue"
]
},
"summary": "Lily and Ben play in the park and Lily gets too caught up in swinging, causing Ben to leave. Lily falls off the swing and hurts herself, but Ben leaves his hat for her as a kind gesture.",
"source": "GPT-4"
}
训练时,读取了"story"里面的内容进行训练,因此我们需要将news_peoples_daily的格式进行转换,news_peoples_daily的json格式如下:
有用的部分也就是[”段落”][”内容”],但可以看到文章是被分为多段了,所以要把这些段落整合到一起,作为一篇新闻,然后再把它放到”story”的字段下:
{
"文件名": "/Users/liuhui/Downloads/rmrb/7z/1983年07月/1983-07-07_对外友协举行酒会_庆祝蒙古人民革命六十二周年.txt",
"是否待查文件": false,
"是否重复文件": false,
"文件大小": 556,
"simhash": 8677582667933606471,
"最长段落长度": 42,
"段落数": 9,
"去重段落数": 9,
"低质量段落数": 0,
"段落": [
{
"行号": 0,
"是否重复": false,
"是否跨文件重复": false,
"md5": "17018587826f99a0ac2ccd3d5973b2f3",
"内容": "### 对外友协举行酒会 庆祝蒙古人民革命六十二周年"
},
{
"行号": 2,
"是否重复": false,
"是否跨文件重复": false,
"md5": "a45e5def32d55da952dfbfb1a20c6283",
"内容": "1983-07-07"
},
{
"行号": 3,
"是否重复": false,
"是否跨文件重复": false,
"md5": "39cfb2c05e0d07765c687366fe84c5ff",
"内容": "第4版()"
},
{
"行号": 4,
"是否重复": false,
"是否跨文件重复": false,
"md5": "2405e967330cfcb4305cb674ef749c0d",
"内容": "专栏:"
},
{
"行号": 6,
"是否重复": false,
"是否跨文件重复": false,
"md5": "f080683bf18389cdcb28f05b6d42ac44",
"内容": "对外友协举行酒会"
},
{
"行号": 7,
"是否重复": false,
"是否跨文件重复": false,
"md5": "4fec90badc3733037cf2b36572f8c347",
"内容": "庆祝蒙古人民革命六十二周年"
},
{
"行号": 8,
"是否重复": false,
"是否跨文件重复": false,
"md5": "9032d9de9b25275e7ae700dde105e3f6",
"内容": "新华社北京7月5日电 为庆祝蒙古人民革命六十二周年,对外友协今天下午在这里举行酒会。"
},
{
"行号": 9,
"是否重复": false,
"是否跨文件重复": false,
"md5": "b331b6d7e9d420e6aa99c790ee6e356c",
"内容": "应邀出席酒会的有蒙古人民共和国驻中国大使彭茨克·沙格达尔苏伦,以及大使馆外交官员。"
},
{
"行号": 10,
"是否重复": false,
"是否跨文件重复": false,
"md5": "921500d7924acf82842f4704a5cf5211",
"内容": "对外友协副会长陆璀主持了酒会。酒会结束后放映了中国彩色故事片《快乐的单身汉》。"
}
]
}
文章每一段的内容也就是用下面的结构体表示
{
"文件名": "string",
"是否待查文件": "bool",
"是否重复文件": "bool",
"文件大小": "int32",
"simhash": "uint64",
"最长段落长度": "int32",
"段落数": "int32",
"去重段落数": "int32",
"低质量段落数": "int32",
"段落": [
{
"行号": "int32",
"是否重复": "bool",
"是否跨文件重复": "bool",
"md5": "string",
"内容": "string",
},
......
]
}
2、数据集处理之tokenizer训练格式
1)先将一篇篇文本拼凑到一起(只是简单的拼凑一起,用于训练tokenizer)
### 对外友协举行酒会 庆祝蒙古人民革命六十二周年
1983-07-07
第4版()
专栏:
对外友协举行酒会
庆祝蒙古人民革命六十二周年
新华社北京7月5日电 为庆祝蒙古人民革命六十二周年,对外友协今天下午在这里举行酒会。
应邀出席酒会的有蒙古人民共和国驻中国大使彭茨克·沙格达尔苏伦,以及大使馆外交官员。
对外友协副会长陆璀主持了酒会。酒会结束后放映了中国彩色故事片《快乐的单身汉》。
### 英德水泥厂不择手段乱涨价 广东省府省纪委正严肃处理
唐炜
1983-07-19
第1版()
专栏:
英德水泥厂不择手段乱涨价 广东省府省纪委正严肃处理
据新华社广州7月18日电 (记者唐炜)广东省英德水泥厂用多种手段擅自提高水泥价格,经初步查明今年到7月9日为止共非法牟利80.6万多元。目前,广东省人民政府、中共广东省纪委正在严肃处理这一事件。
这个厂无视国家统一定价,随意自定水泥价格。他们的主要手法是:一、用计划内的熟料,加工成计划外水泥,然后高价出售。今年,他们用这种手段共多收货款64,900多元。二、以超产自销为名,擅自将五二五号水泥出厂价从每吨67元提高到113元3角,共多收货款128,200多元。三、擅自加收纸袋差价、装车费、转仓费、铁路专用线费等。这个厂有一段长6公里的铁路专用线,早由铁路部门统一管理和收费。但工厂从去年3月起,还收铁路专用线费,仅今年上半年就多收了54,300多元。
代码如下:
"""
Download, preprocess and serve the TinyStories dataset as a DataLoader.
"""
import argparse
import glob
import json
import os
import random
from typing import List
from concurrent.futures import ThreadPoolExecutor, as_completed
import numpy as np
import requests
import torch
import torch.distributed as dist
from tqdm import tqdm
# 将数据json转为txt文件,然后通过程序meragedatas.py合并数据集
DATA_CACHE_DIR = "data"
import json
def process_shard(filename):
tokenize_data_filename = filename.replace(".json", ".txt")
# 判断文件是否存在
# 文件存在,以追加模式打开文件
with open(tokenize_data_filename, "w",encoding='utf-8') as f:
# 写入内容
f.close()
fd = open(tokenize_data_filename, "a",encoding='utf-8')
with open(filename,encoding='utf-8') as f:
file_content = f.read()
json_objs = file_content.split("\n")
# all_content =""
for obj in tqdm(json_objs):
if obj.strip():
data = json.loads(obj)
one_txt_content = "\n\n"
for para in data['段落']:
one_txt_content = one_txt_content + para['内容'] + '\n'
# 写入内容
fd.write(one_txt_content)
# # iterate the shards and tokenize all of them one by one
data_dir = os.path.join(DATA_CACHE_DIR, "news_peoples_daily")
shard_filenames = sorted(glob.glob(os.path.join(data_dir, "*.json")))
# # # process all the shards in a threadpool
with ThreadPoolExecutor(max_workers=8) as executor:
executor.map(process_shard, shard_filenames)
print("Done.")
2)将数据集进行合并
由于有多个json文本文件,然后也保存了多个txt文件,所以将这些txt文件合并为一个文件,保存为"data/mergedatas.txt”:
import os
# 将news_peoples_daily.py生成的txt文件合并到一个文件,用于训练tokenizer.model
# 目标文件夹路径和输出文件路径
folder_path = "data"
DATA_CACHE_DIR = "data"
data_dir = os.path.join(DATA_CACHE_DIR, "news_peoples_daily")
output_path = "data/mergedatas.txt"
# 遍历目标文件夹下的所有文件
with open(output_path, "w",encoding = "utf-8") as output_file:
for filename in os.listdir(data_dir):
# 检查文件是否以.txt结尾
if filename.endswith(".txt"):
# 是txt文件,打开文件并将内容写入输出文件中
file_path = os.path.join(data_dir, filename)
with open(file_path, "r",encoding='utf-8') as input_file:
output_file.write(input_file.read())
合并后的数据集"data/mergedatas.txt”,就可以用来训练tokenizer了,训练过程参考下面的文章:
[玩转AIGC]sentencepiece训练一个Tokenizer(标记器)
3、数据集处理之模型(llama2)训练(train.py)格式
我们还需要对数据集进行处理,使得其符合train.py的输入数据格式,也就是转为带key为"story"的json数据,保存为txt文件:
"""
Download, preprocess and serve the TinyStories dataset as a DataLoader.
"""
import argparse
import glob
import json
import os
import random
from typing import List
from concurrent.futures import ThreadPoolExecutor, as_completed
import numpy as np
import requests
import torch
import torch.distributed as dist
from tqdm import tqdm
# 将数据json转为txt文件,然后通过程序meragedatas.py合并数据集
DATA_CACHE_DIR = "data"
import json
def process_shard(filename):
tokenize_data_filename = filename.replace(".json", ".txt")
# 判断文件是否存在
# 文件存在,以追加模式打开文件
with open(tokenize_data_filename, "w",encoding='utf-8') as f:
# 写入内容
f.close()
fd = open(tokenize_data_filename, "a",encoding='utf-8')
fd.write("[")
ifstart = True
with open(filename,encoding='utf-8') as f:
file_content = f.read()
json_objs = file_content.split("\n")
# all_content =""
for obj in tqdm(json_objs):
if obj.strip():
data = json.loads(obj)
one_txt_content = ""
one_article = ""
for para in data['段落']: # 一段内容
one_txt_content = one_txt_content + para['内容'] + '\n'
# 写入内容
#fd.write(one_txt_content)
# all_content = all_content + one_txt_content
if not ifstart:
fd.write(",")
fd.write("\n")
ifstart = False
jsonContent = {
"story":one_txt_content
}
json.dump(jsonContent, fd, ensure_ascii=False)
fd.write("]")
fd.close()
# # iterate the shards and tokenize all of them one by one
data_dir = os.path.join(DATA_CACHE_DIR, "news_peoples_daily")
shard_filenames = sorted(glob.glob(os.path.join(data_dir, "*.json")))
# # # process all the shards in a threadpool
with ThreadPoolExecutor(max_workers=8) as executor:
executor.map(process_shard, shard_filenames)
print("Done.")
转换后如下:
[{“story”: “### 对外友协举行酒会 庆祝蒙古人民革命六十二周年\n1983-07-07\n第4版()\n专栏:\n对外友协举行酒会\n庆祝蒙古人民革命六十二周年\n新华社北京7月5日电\u3000为庆祝蒙古人民革命六十二周年,对外友协今天下午在这里举行酒会。\n应邀出席酒会的有蒙古人民共和国驻中国大使彭茨克·沙格达尔苏伦,以及大使馆外交官员。\n对外友协副会长陆璀主持了酒会。酒会结束后放映了中国彩色故事片《快乐的单身汉》。\n”},
{“story”: “### 今日兄弟报纸要目\n1983-07-08\n第4版()\n专栏:今日兄弟报纸要目\n今日兄弟报纸要目\n《天津日报》△国务院委托水电部在天津召开的引滦工程管理工作会议提出,不但要把引滦工程建设成为第一流的工程,而且要努力创造第一流的管理水平\n《经济日报》△一些地区和单位措施不力,心存观望,关停计划外烟厂进展迟缓\n△社论:执行国务院决定不能打折扣\n《四川日报》△四川省政府决定计划外烟厂一律关停\n《湖北日报》△武汉钢铁公司主动清查乱涨价问题,从7月1日起停止加收计划外协作钢材“管理费”\n《文汇报》△进一步加强关于统一祖国方针政策的宣传教育,《上海市对台宣传展览》昨日开幕\n《解放军报》△北京部队某炮团坚持原则,退回12名不符合规定的汽车驾驶员\n《人民铁道》△特约评论员文章:杜绝野蛮装卸的根本措施在于加强基础工作\n《南方日报》△广东省地质局水文一队在雷州半岛地表以下500米深度内查明有“地下海”,地下水资源总量每日为1,471万吨\n《陕西日报》△平利县农民积极发展香菇生产,全县有1,100多户和外贸公司签订合同\n《解放日报》△上海造船工业今年上半年创历史最好水平,已完成船舶20艘,计17.7万多吨位,其中出口船11艘,共15.6万多吨位,总产值4亿多\n《北京日报》北京市政府通知:严格控制企业职工加班加点,制止滥发加班加点工资\n”}]
总之:这里我们准备了2种数据,一种用于训练tokenizer,一种用于训练llama2模型,并分别简单介绍了数据结构
三、训练一个tokenizer
训练操作可以参考博文:[玩转AIGC]sentencepiece训练一个Tokenizer(标记器)
spm_train --input=data/mergedatas.txt -model_prefix=./tokenizer
训练完成后可以查看相关词汇
查看词汇个数:
打开训练好的文件tokenizer.vocab,就可以看到个数,可看到一共是8000
将tokenizer转为C++可读的bin,运行:
# 以下代码是在llama2.c根目录运行
python3 tokenizer.py
可看到:
tokenizer.bin
四、使用训练的tokenizer预编码输入数据
在进行train之前,先对训练集进行处理,即使用训练好的tokenizer进行编码:
先修改tinystories.py的pretokenize()方法里面的数据集路径:
data_dir = os.path.join(DATA_CACHE_DIR, "news_peoples_daily")
必要时修改主路径:
DATA_CACHE_DIR = "data"
然后运行:
python3 tinystories.py pretokenize
五、训练llama2模型
1、修改参数
1)vocab_size
训练之前需要对一些参数进行修改,这一步很重要:
首先要改词汇量大小,前面我们查到词汇量是8000
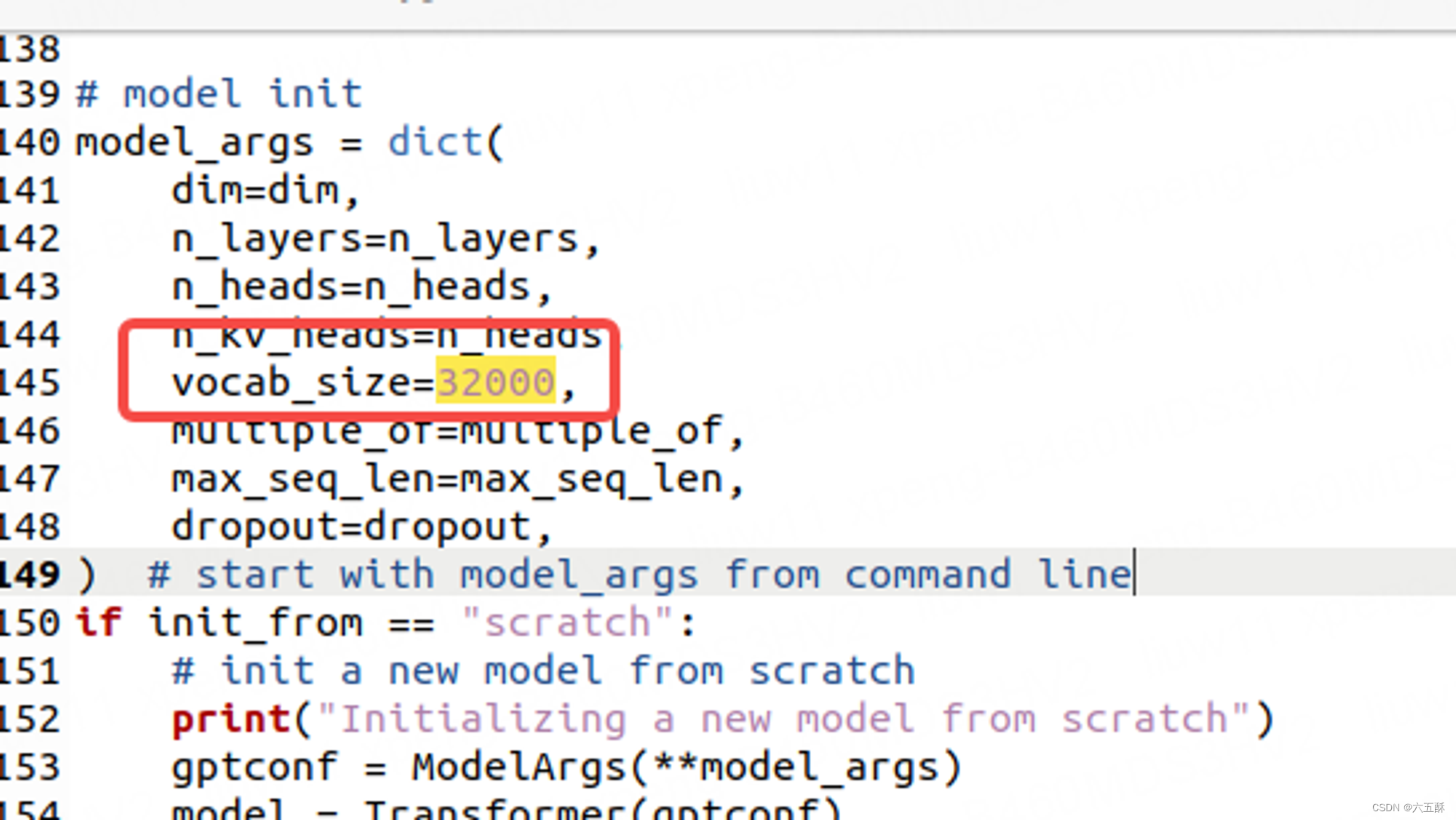
vocab_size设置为总文字数的个数,可以看到原代码为32000,所以这里将32000改为8000,否则在运行./run model.bin的时候,会在下面画框那句return了,因为数组越界。
注意:run.c里面的config是从train出来的model.bin读取的,也就是里面的checkpoint
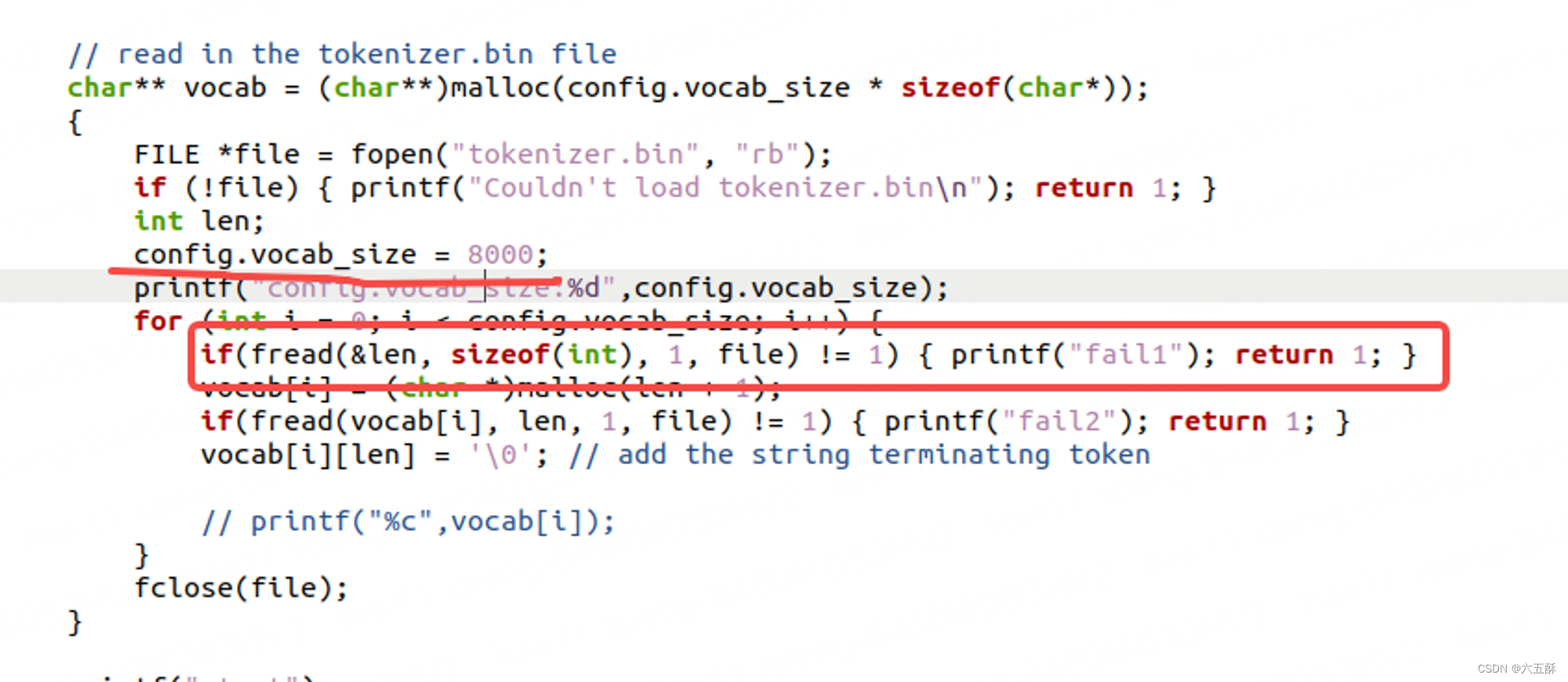
如果训练时忘记改了,那就直接在run.c里面直接把config.vocab_size改过来即可,上面划线部分就是直接把32000改为8000
2)max_seq_len与batch size
max_seq_len:推理生成的句子长度,会直接影响生成的故事长度,默认为256,能人为在run.c里面去修改长度(但是长度最好不超过训练时的max_seq_len,否则运行run.c时运行到越界了会报错),在run.c里面的变量为steps,训练时max_seq_len不能太大,要不然会报显存不足,训练时候会看到提示:
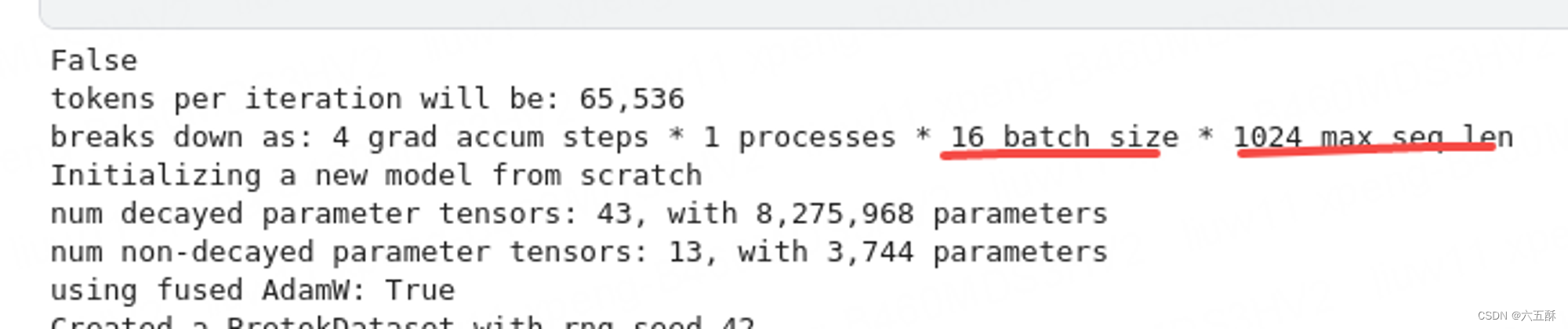
代码里面默认为64256,也就是batch size为64,max_seq_len为256,这边我为了增长推理输出的句子长度(max_seq_len),把训练时的batch_size减少了,要不然内存要不足了,也就是改为161024
3)token
run.c中int token = 1,表示从头开始生成,设置为0会不知道从哪开始,随便生成的,也就是开头不知道从哪开始,所以建议token采用默认值,也就是token=1
2、模型训练
训练之前需修改数据集加载的路径
先来看看训练时数据集是怎么加载的:
先来看看训练时数据集是怎么加载的:
from tinystories import Task
iter_batches = partial(
Task.iter_batches,
batch_size=batch_size,
max_seq_len=max_seq_len,
device=device,
num_workers=0,
)
train_batch_iter = iter_batches("train")
可以看到调用了Task.iter_batches,Task是在tinystories.py里面定义的,来看看tinystories.py里面的Task:
class Task:
@staticmethod
def iter_batches(split, batch_size, max_seq_len, device, num_workers=0):
ds = PretokDataset(split, max_seq_len)
dl = torch.utils.data.DataLoader(
ds, batch_size=batch_size, pin_memory=True, num_workers=num_workers
)
for x, y in dl:
x = x.to(device, non_blocking=True)
y = y.to(device, non_blocking=True)
yield x, y
可看到调用了PretokDataset,仔细看PretokDataset,发现了数据集路径,修改即可,也就是修改PretokDataset下的"news_peoples_daily"
data_dir = os.path.join(DATA_CACHE_DIR, "news_peoples_daily")
修改好之后训练模型:
python3 train.py
1)直接可跑的代码:
下载数据集之后放在data目录,依次运行:
1、python3 news_peoples_daily.py
2、python3 mergedatas.py
3、python3 processTrainDataSets.py
4、python3 tinystories.py pretokenize
5、python3 train.py
2)只保留训练的代码
放在kaggle里面的代码,需要创建data/news_peoples_daily文件,然后把编码好的数据集.bin文件放到里面,直接训练训练即可:
3、模型读取与转换
训练之后,在out里我们可以得到两个模型:

model.bin模型是可以用来进行C代码推理的
1) python 读取bin模型
import torch
import struct
import numpy as np
def checkpoint_init_weights(p, f, shared_weights):
ptr = 0
w = {}
# Read token_embedding_table
w["token_embedding_table"] = f[ptr:ptr + p["vocab_size"] * p["dim"]].reshape((p["vocab_size"], p["dim"]))
ptr += p["vocab_size"] * p["dim"]
# Read rms_att_weight
w["rms_att_weight"] = f[ptr:ptr + p["n_layers"] * p["dim"]].reshape((p["n_layers"], p["dim"]))
ptr += p["n_layers"] * p["dim"]
# Read wq
w["wq"] = f[ptr:ptr + p["n_layers"] * p["dim"] * p["dim"]].reshape((p["n_layers"], p["dim"], p["dim"]))
ptr += p["n_layers"] * p["dim"] * p["dim"]
# Read wk
w["wk"] = f[ptr:ptr + p["n_layers"] * p["dim"] * p["dim"]].reshape((p["n_layers"], p["dim"], p["dim"]))
ptr += p["n_layers"] * p["dim"] * p["dim"]
# Read wv
w["wv"] = f[ptr:ptr + p["n_layers"] * p["dim"] * p["dim"]].reshape((p["n_layers"], p["dim"], p["dim"]))
ptr += p["n_layers"] * p["dim"] * p["dim"]
# Read wo
w["wo"] = f[ptr:ptr + p["n_layers"] * p["dim"] * p["dim"]].reshape((p["n_layers"], p["dim"], p["dim"]))
ptr += p["n_layers"] * p["dim"] * p["dim"]
# Read rms_ffn_weight
w["rms_ffn_weight"] = f[ptr:ptr + p["n_layers"] * p["dim"]].reshape((p["n_layers"], p["dim"]))
ptr += p["n_layers"] * p["dim"]
# Read w1
w["w1"] = f[ptr:ptr + p["n_layers"] * p["dim"] * p["hidden_dim"]].reshape((p["n_layers"], p["dim"], p["hidden_dim"]))
ptr += p["n_layers"] * p["dim"] * p["hidden_dim"]
# Read w2
w["w2"] = f[ptr:ptr + p["n_layers"] * p["hidden_dim"] * p["dim"]].reshape((p["n_layers"], p["hidden_dim"], p["dim"]))
ptr += p["n_layers"] * p["hidden_dim"] * p["dim"]
# Read w3
w["w3"] = f[ptr:ptr + p["n_layers"] * p["dim"] * p["hidden_dim"]].reshape((p["n_layers"], p["dim"], p["hidden_dim"]))
ptr += p["n_layers"] * p["dim"] * p["hidden_dim"]
# Read rms_final_weight
w["rms_final_weight"] = f[ptr:ptr + p["dim"]]
ptr += p["dim"]
# Read freq_cis_real
head_size = p["dim"] // p["n_heads"]
w["freq_cis_real"] = f[ptr:ptr + p["seq_len"] * head_size // 2]
ptr += p["seq_len"] * head_size // 2
# Read freq_cis_imag
w["freq_cis_imag"] = f[ptr:ptr + p["seq_len"] * head_size // 2]
ptr += p["seq_len"] * head_size // 2
# Set wcls
w["wcls"] = w["token_embedding_table"] if shared_weights else f[ptr:]
return w
model_path = "model4.bin"
#model_path = "stories15M.bin"
# 打开二进制模型文件
with open(model_path, 'rb') as f:
# 读取模型文件头部信息
#data = f.read()
#print(data)
header = f.read(struct.calcsize('iiiiiii'))
header = struct.unpack('iiiiiii', header)
print(header)
dim, hidden_dim, n_layers, n_heads, n_kv_heads, vocab_size, max_seq_len = header
#config = f.read(struct.calcsize('config'))
#config = struct.unpack('config', config)
with open(model_path, 'rb') as f:
config = {
"dim": dim,
"hidden_dim": hidden_dim,
"n_layers": n_layers,
"n_heads": n_heads,
"n_kv_heads": n_kv_heads,
"vocab_size": vocab_size,
"seq_len":max_seq_len
}
f_data = np.frombuffer(f.read(), dtype=np.float32)
weights = checkpoint_init_weights(config, f_data, shared_weights=True)
print(weights["token_embedding_table"].shape)
print(weights["rms_att_weight"].shape)
print(weights["wq"].shape)
print(weights["wk"].shape)
print(weights["wv"].shape)
print(weights["wo"].shape)
print(weights["rms_ffn_weight"].shape)
print(weights["w1"].shape)
print(weights["w2"].shape)
print(weights["w3"].shape)
print(weights["rms_final_weight"].shape)
print(weights["freq_cis_real"].shape)
print(weights["freq_cis_imag"].shape)
print(weights["wcls"].shape)
print(weights.keys())
print(weights["freq_cis_real"])
print(weights["freq_cis_imag"])
np.save('freq_cis_real.npy', weights["freq_cis_real"])
np.save('freq_cis_imag.npy', weights["freq_cis_imag"])
print("模型加载完成")
2)python读取pt模型并转为bin
1>逐层手写转换(占用内存少)
loadModelPt.py
import torch
import numpy as np
import struct
from model import precompute_freqs_cis
filepath = "model66.bin"
f = open(filepath, 'wb')
def serialize(t):
# 将张量转换为浮点数数组,并写入文件
d = t.detach().cpu().view(-1).numpy().astype(np.float32) # 多维转为1维
b = struct.pack(f'{len(d)}f', *d) # 转为byte
f.write(b) # 写入文件
# 指定模型文件路径
model_path = 'out/ckpt3.pt'
# 加载模型
model = torch.load(model_path)
print(model.keys())
print("model_args",model["model_args"])
print("----------")
print("config",model["config"])
print("----------")
print("optimizer.keys()",model["optimizer"].keys())
print("optimizer['state'].keys()",model["optimizer"]["state"].keys())
print("----------")
print("model['model'].keys()",model['model'].keys())
print(model['model']["tok_embeddings.weight"])
dim = model["model_args"]["dim"]
hidden_dim = model['model']['layers.0.feed_forward.w1.weight'].shape[0]
n_layers = model["model_args"]["n_layers"]
n_heads = model["model_args"]["n_heads"]
n_kv_heads = model["model_args"]["n_kv_heads"]
vocab_size = model["model_args"]["vocab_size"]
max_seq_len = model["model_args"]["max_seq_len"]
print("hidden_dim",hidden_dim)
header = struct.pack('iiiiiii', dim, hidden_dim, n_layers, n_heads,
n_kv_heads, vocab_size, max_seq_len)
f.write(header)
serialize(model['model']["tok_embeddings.weight"])
print(model['model']["layers.0.attention.wq.weight"])
serialize(model['model']["layers.0.attention_norm.weight"])
serialize(model['model']["layers.1.attention_norm.weight"])
serialize(model['model']["layers.2.attention_norm.weight"])
serialize(model['model']["layers.3.attention_norm.weight"])
serialize(model['model']["layers.4.attention_norm.weight"])
serialize(model['model']["layers.5.attention_norm.weight"])
serialize(model['model']["layers.0.attention.wq.weight"])
serialize(model['model']["layers.1.attention.wq.weight"])
serialize(model['model']["layers.2.attention.wq.weight"])
serialize(model['model']["layers.3.attention.wq.weight"])
serialize(model['model']["layers.4.attention.wq.weight"])
serialize(model['model']["layers.5.attention.wq.weight"])
serialize(model['model']["layers.0.attention.wk.weight"])
serialize(model['model']["layers.1.attention.wk.weight"])
serialize(model['model']["layers.2.attention.wk.weight"])
serialize(model['model']["layers.3.attention.wk.weight"])
serialize(model['model']["layers.4.attention.wk.weight"])
serialize(model['model']["layers.5.attention.wk.weight"])
serialize(model['model']["layers.0.attention.wv.weight"])
serialize(model['model']["layers.1.attention.wv.weight"])
serialize(model['model']["layers.2.attention.wv.weight"])
serialize(model['model']["layers.3.attention.wv.weight"])
serialize(model['model']["layers.4.attention.wv.weight"])
serialize(model['model']["layers.5.attention.wv.weight"])
serialize(model['model']["layers.0.attention.wo.weight"])
serialize(model['model']["layers.1.attention.wo.weight"])
serialize(model['model']["layers.2.attention.wo.weight"])
serialize(model['model']["layers.3.attention.wo.weight"])
serialize(model['model']["layers.4.attention.wo.weight"])
serialize(model['model']["layers.5.attention.wo.weight"])
serialize(model['model']["layers.0.ffn_norm.weight"])
serialize(model['model']["layers.1.ffn_norm.weight"])
serialize(model['model']["layers.2.ffn_norm.weight"])
serialize(model['model']["layers.3.ffn_norm.weight"])
serialize(model['model']["layers.4.ffn_norm.weight"])
serialize(model['model']["layers.5.ffn_norm.weight"])
serialize(model['model']["layers.0.feed_forward.w1.weight"])
serialize(model['model']["layers.1.feed_forward.w1.weight"])
serialize(model['model']["layers.2.feed_forward.w1.weight"])
serialize(model['model']["layers.3.feed_forward.w1.weight"])
serialize(model['model']["layers.4.feed_forward.w1.weight"])
serialize(model['model']["layers.5.feed_forward.w1.weight"])
serialize(model['model']["layers.0.feed_forward.w2.weight"])
serialize(model['model']["layers.1.feed_forward.w2.weight"])
serialize(model['model']["layers.2.feed_forward.w2.weight"])
serialize(model['model']["layers.3.feed_forward.w2.weight"])
serialize(model['model']["layers.4.feed_forward.w2.weight"])
serialize(model['model']["layers.5.feed_forward.w2.weight"])
serialize(model['model']["layers.0.feed_forward.w3.weight"])
serialize(model['model']["layers.1.feed_forward.w3.weight"])
serialize(model['model']["layers.2.feed_forward.w3.weight"])
serialize(model['model']["layers.3.feed_forward.w3.weight"])
serialize(model['model']["layers.4.feed_forward.w3.weight"])
serialize(model['model']["layers.5.feed_forward.w3.weight"])
serialize(model['model']['norm.weight'])
freqs = precompute_freqs_cis(model["model_args"]['dim'] // model["model_args"]['n_heads'], model["model_args"]['max_seq_len'] * 2)
serialize(freqs.real[:model["model_args"]["max_seq_len"]])
serialize(freqs.imag[:model["model_args"]["max_seq_len"]])
print("--------------")
f.close()
2>参考llama2.py的转换(占用内存大一些)
github:https://github.com/tairov/llama2.py/tree/master
需对原来的代码做小修改,改为从.pt读取参数,然后也要修改输入:
修改后的代码为:
export_meta_llama_bin.py
如果你想改输入输出的路径,那么要修改代码export_meta_llama_bin.py里面的:
model_path = "out/ckpt.pt"
output_path = "model.bin"
然后直接运行:
python3 export_meta_llama_bin.py
4、模型推理
1)代码与模型
代码与模型在run.zip里面

可以看到主要为上图框中的4个文件,其中.bin文件均为模型文件,一个是文本编码模型,一个是llama模型
2)编译运行
进行编译
make run
运行推理
./run model.bin
int token = 0时生成的内容,开头随便生成

int token = 1,=从头生成,且max_seq_len=1024

五、拓展
1、可自定义参数运行(master分支下的旧tokenizer.bin模型)
git checkout feature/avx2
修改:
去掉下面两句(读取tokenizer.bin时):
if (fread(&max_token_length, sizeof(int), 1, file) != 1) { fprintf(stderr, "failed read\n"); return 1; }
if (fread(vocab_scores + i, sizeof(float), 1, file) != 1) { fprintf(stderr, "failed read\n"); return 1;}
bpe_encode也需要做修改(添加中文支持):
参考:https://github.com/chenyangMl/llama2.c-zh/blob/main/run.c
void bpe_encode(char *text, char **vocab, float *vocab_scores, int vocab_size, unsigned int max_token_length, int *tokens, int *n_tokens) {
// a temporary buffer to merge two consecutive tokens
char* str_buffer = malloc((max_token_length*2+1) * sizeof(char)); // *2 for concat, +1 for null terminator
// first encode every individual character in the input string
*n_tokens = 0; // the number of tokens
int text_length = strlen(text);
int i = 0;
while (i < text_length) {
unsigned char byte1 = text[i];
unsigned char byte2 = text[i+1];
unsigned char byte3 = text[i+2];
if ((byte1 & 0xE0) == 0xE0) {
// 3-byte character (Chinese character, with utf8 encoding)
sprintf(str_buffer, "%c%c%c", byte1, byte2, byte3);
i += 3;
} else {
// 1-byte character (English character)
sprintf(str_buffer, "%c", byte1);
i += 1;
}
int id = str_lookup(str_buffer, vocab, vocab_size);
if (id == -1) { fprintf(stderr, "not good\n"); exit(EXIT_FAILURE); }
// printf("c=%s, vocab_size=%d, id=%d\n", str_buffer, vocab_size,id);
tokens[*n_tokens] = id;
(*n_tokens)++;
}
// merge the best consecutive pair each iteration, according to the scores in vocab_scores
while (1) {
float best_score = -1e10;
int best_id = -1;
int best_idx = -1;
for (int i = 0; i < (*n_tokens-1); i++) {
// check if we can merge the pair (tokens[i], tokens[i+1])
sprintf(str_buffer, "%s%s", vocab[tokens[i]], vocab[tokens[i+1]]);
int id = str_lookup(str_buffer, vocab, vocab_size);
if (id != -1 && vocab_scores[id] > best_score) {
// this merge pair exists in vocab! record its score and position
best_score = vocab_scores[id];
best_id = id;
best_idx = i;
}
}
if (best_idx == -1) {
break; // we couldn't find any more pairs to merge, so we're done
}
// merge the consecutive pair (best_idx, best_idx+1) into new token best_id
tokens[best_idx] = best_id;
// delete token at position best_idx+1, shift the entire sequence back 1
for (int i = best_idx+1; i < (*n_tokens-1); i++) {
tokens[i] = tokens[i+1];
}
(*n_tokens)--; // token length decreased
}
free(str_buffer);
}
运行:
make run
./run model.bin -i "### 新世界"

./run model.bin -i "### 新世界" -n 8000
2、可自定义参数运行(feature/avx2分支下的tokenizer.bin模型)
AVX2指的是使用 AVX2 指令集的内嵌函数(intrinsics)来执行矩阵乘法(matmul)操作,当然也包含了原始的矩阵乘法方法
将tokenizer.model拷贝到代码根目录下,运行:
python3 tokenizer.py
导出的模型:tokenizer.bin
可见比master分支下的模型还要大一些,内容更丰富
跟1、可自定义参数运行(运行master旧tokenizer.bin模型) 一样,但是只需要修改bpe_encode 使得代码能够兼容中文,不一样的地方是不需要修改tokenizer.bin模型的读取,也就是不需要去掉:
if (fread(&max_token_length, sizeof(int), 1, file) != 1) { fprintf(stderr, "failed read\n"); return 1; }
if (fread(vocab_scores + i, sizeof(float), 1, file) != 1) { fprintf(stderr, "failed read\n"); return 1;}
3、上述两种自定义参数运行的差异
不同的地方在export
master的export
def export(self):
tokens = []
for i in range(self.n_words):
# decode the token and light postprocessing
t = self.sp_model.id_to_piece(i)
if i == self.bos_id:
t = '\n<s>\n'
elif i == self.eos_id:
t = '\n</s>\n'
elif len(t) == 6 and t.startswith('<0x') and t.endswith('>'):
t = chr(int(t[3:5], 16)) # e.g. make '<0x01>' into '\x01'
t = t.replace('▁', ' ') # sentencepiece uses this as the whitespace
print(t)
tokens.append(t)
with open(TOKENIZER_BIN, 'wb') as f:
for token in tokens:
bytes = token.encode('utf-8')
f.write((len(bytes)).to_bytes(4, 'little')) # write length of bytes
f.write(bytes) # write token bytes
feature/avx2的export
def export(self):
# get all the tokens (postprocessed) and their scores as floats
tokens, scores = [], []
for i in range(self.n_words): # 遍历所有字
# decode the token and light postprocessing
t = self.sp_model.id_to_piece(i) # 文本
s = self.sp_model.get_score(i) # 分数
# 上面相当于遍历了tokenizer.vocab
if i == self.bos_id:
# 原来为<s>,只是为了添加换行符,容易看
t = '\n<s>\n'
elif i == self.eos_id:
# 原来为</s>,只是为了添加换行符,容易看
t = '\n</s>\n'
elif len(t) == 6 and t.startswith('<0x') and t.endswith('>'):
t = chr(int(t[3:5], 16)) # e.g. make '<0x01>' into '\x01'
t = t.replace('▁', ' ') # sentencepiece uses this character as whitespace
b = t.encode('utf-8') # bytes of this token, utf-8 encoded
tokens.append(b)
scores.append(s)
if len(b) == 33:
print(t)
#print(t,s)
print(self.n_words)
# record the max token length
max_token_length = max(len(t) for t in tokens)
# write to a binary file
with open(TOKENIZER_BIN, 'wb') as f:
f.write(struct.pack("I", max_token_length)) # 保存tokenizer.vocab里面的中文词汇编为二进制的最大长度
print(max_token_length)
for bytes, score in zip(tokens, scores): # 遍历tokenizer.vocab,tokens是通过b = t.encode('utf-8')编码为二进制的
#f.write(struct.pack("fI", score, len(bytes)))
f.write(struct.pack("I", len(bytes)))
f.write(bytes)
把写入文件那里摘出来:
#master
with open(TOKENIZER_BIN, 'wb') as f:
for token in tokens:
bytes = token.encode('utf-8')
f.write((len(bytes)).to_bytes(4, 'little')) # write length of bytes
f.write(bytes) # write token bytes
#feature/avx2
# write to a binary file
with open(TOKENIZER_BIN, 'wb') as f:
f.write(struct.pack("I", max_token_length)) # 保存tokenizer.vocab里面的中文词汇编为二进制的最大长度
print(max_token_length)
for bytes, score in zip(tokens, scores): # 遍历tokenizer.vocab,tokens是通过b = t.encode('utf-8')编码为二进制的
f.write(struct.pack("fI", score, len(bytes)))
#f.write(struct.pack("I", len(bytes)))
f.write(bytes)
多写了max_token_length,与score:
把f.write(struct.pack(“fI”, score, len(bytes)))改为f.write(struct.pack(“I”, len(bytes)))
把**f.write(struct.pack(“I”, max_token_length))**去掉,两者就一样了
4、C++读取tokenizer注释
{
FILE *file = fopen("tokenizer.bin", "rb");
if (!file) { fprintf(stderr, "couldn't load tokenizer.bin\n"); return 1; }
if (fread(&max_token_length, sizeof(int), 1, file) != 1) { fprintf(stderr, "failed read1\n"); return 1; } // 读取max_token_length,用于内存分配
int len;
for (int i = 0; i < config.vocab_size; i++) {
if (fread(vocab_scores + i, sizeof(float), 1, file) != 1) { fprintf(stderr, "failed read2\n"); return 1;} // 读取scores
if (fread(&len, sizeof(int), 1, file) != 1) { fprintf(stderr, "failed read3\n"); return 1; }//读取二进制token的长度
vocab[i] = (char *)malloc(len + 1);
if (fread(vocab[i], len, 1, file) != 1) { fprintf(stderr, "failed read4\n"); return 1; } //读取二进制token数据
vocab[i][len] = '\0'; // add the string terminating token
}
fclose(file);
}
5、run.c中的bpe_encode(即tokenizer的具体流程)
void bpe_encode(char *text, char **vocab, float *vocab_scores, int vocab_size, unsigned int max_token_length, int *tokens, int *n_tokens) {
printf("%s\n", text); // text为输入的文字(提示词,prompt)
// a temporary buffer to merge two consecutive tokens
char* str_buffer = malloc((max_token_length*2+1) * sizeof(char)); // *2 for concat, +1 for null terminator
// first encode every individual character in the input string
*n_tokens = 0; // the number of tokens
int text_length = strlen(text);
//printf("text_length = %d\n",text_length);
int i = 0;
while (i < text_length) {
unsigned char byte1 = text[i];
unsigned char byte2 = text[i+1];
unsigned char byte3 = text[i+2];
//UTF-8 编码中文通常使用 3 个字节来表示,所以一次性先取3个字节
if ((byte1 & 0xE0) == 0xE0) { // 判断是否为中文
// 3-byte character (Chinese character, with utf8 encoding)
sprintf(str_buffer, "%c%c%c", byte1, byte2, byte3); // 将字节编码转为字符串,也就是单个中文文字
i += 3;
} else {
// 1-byte character (English character)
sprintf(str_buffer, "%c", byte1);// 将字节编码转为字符串,也就是单个英文字母
i += 1;
}
int id = str_lookup(str_buffer, vocab, vocab_size); // 去tokens(tokenizer.vocab)里面去找,存在就获取其index
if (id == -1) { fprintf(stderr, "not good\n"); exit(EXIT_FAILURE); } // 找不到说明输入的字符不支持
// printf("c=%s, vocab_size=%d, id=%d\n", str_buffer, vocab_size,id);
tokens[*n_tokens] = id; //找到了就保存对应的索引id
(*n_tokens)++; // 记录token的总个数
}
// merge the best consecutive pair each iteration, according to the scores in vocab_scores
while (1) {
float best_score = -1e10; // -1 乘以 10 的 10 次方,-10B。这是一个非常大的负数,约等于负一百亿
int best_id = -1;
int best_idx = -1;
for (int i = 0; i < (*n_tokens-1); i++) {// 判断前后两个token能否组成一个词
// check if we can merge the pair (tokens[i], tokens[i+1])
sprintf(str_buffer, "%s%s", vocab[tokens[i]], vocab[tokens[i+1]]); // 两个token组为一个
//printf(" = %s\n",str_buffer);
int id = str_lookup(str_buffer, vocab, vocab_size);
if (id != -1 && vocab_scores[id] > best_score) {
// this merge pair exists in vocab! record its score and position
//组合的词在tokenizer.vocab里面,那么记录其分数与位置index id,最后获取组合后分数最高的那个词汇
best_score = vocab_scores[id]; // 记录分数
best_id = id; // 记录在词汇表中的位置
best_idx = i; // 记录在tokens中的位置
}
}
//char* str_buffer1 = malloc((max_token_length*2+1) * sizeof(char));
///sprintf(str_buffer1, "%s", vocab[best_id]);
//printf("str_buffer1 = %s\n",str_buffer1);
if (best_idx == -1) {
break; // we couldn't find any more pairs to merge, so we're done // 直到找不到匹配的,退出死循环
}
// merge the consecutive pair (best_idx, best_idx+1) into new token best_id 保存分数最高的那个组成词
tokens[best_idx] = best_id;
//char* str_buffer2 = malloc((max_token_length*2+1) * sizeof(char));
//printf("best_idx:%d\n",best_id);
//sprintf(str_buffer2, "%s%s", vocab[best_id]);
//printf("best[i] = %s\n", str_buffer2);
// delete token at position best_idx+1, shift the entire sequence back 1
//删除两个被组合的token,保留组合后的token,tokens[best_idx]与tokens[best_idx+1]组合的新词保存到tokens[best_idx],因此剩下没组合的词汇要往前挪
for (int i = best_idx+1; i < (*n_tokens-1); i++) {
tokens[i] = tokens[i+1];
}
(*n_tokens)--; // token length decreased,组合后tokens长度减小1个
//for (int i = 0; i < (*n_tokens) ; i++) {
// sprintf(str_buffer2, "%s%s", vocab[tokens[i]]);
// printf("tokens[i] = %s\n", str_buffer2);
//}
}
free(str_buffer);
}
对于大部分常见的中文字符,UTF-8 编码使用 3 个字节来表示。每个字节都有 8 位,因此一个中文字符在 UTF-8 编码中所占用的总位数是 3 × 8 = 24 位。
比如用下面的输入,带了prompt
./run model66.bin -n 10 -i "中国特色社会主义"
输入的prompt为“中国特色社会主义”,会通过bpe_encode这个函数进行处理,结合分数来处理,
训练的tokenizer的词汇表,我们可以看到:
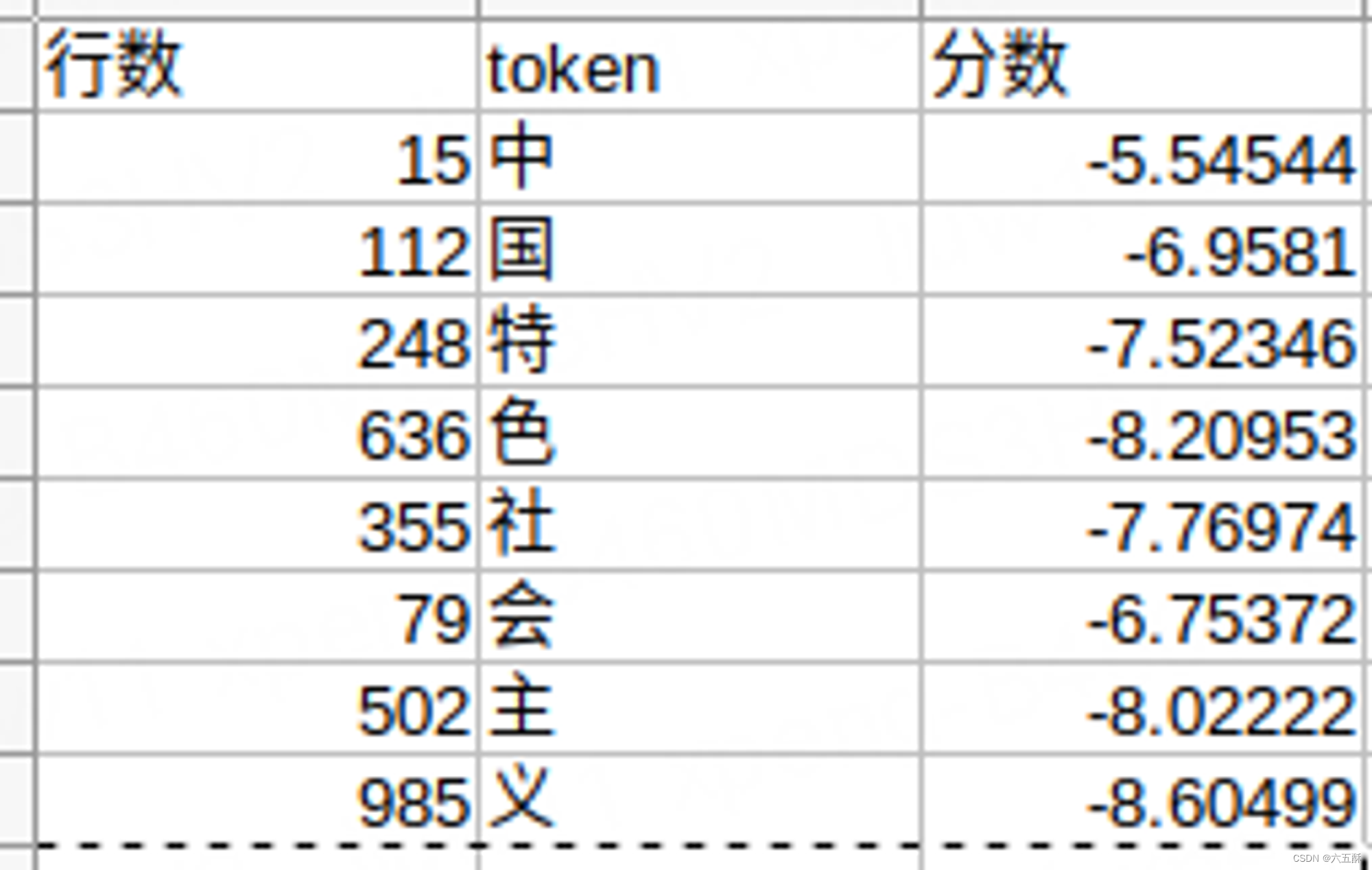
两个组合就是:
在tokenizer词汇表里面能找到的就是以下的词汇:
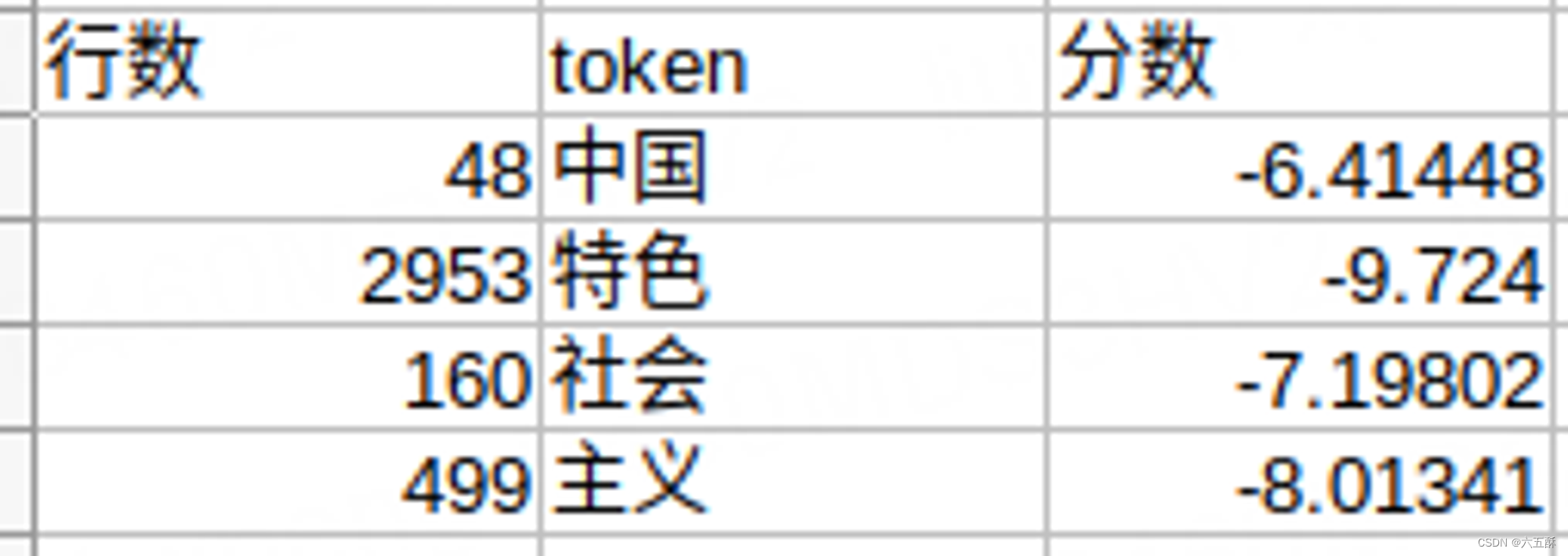
可见中国是分数得分最高的,因此第一轮的:
best_score = -6.41448;
best_id = 48;
best_idx = 0;
把“中”,“国”,组合为“中国”,因此tokens变为以下的
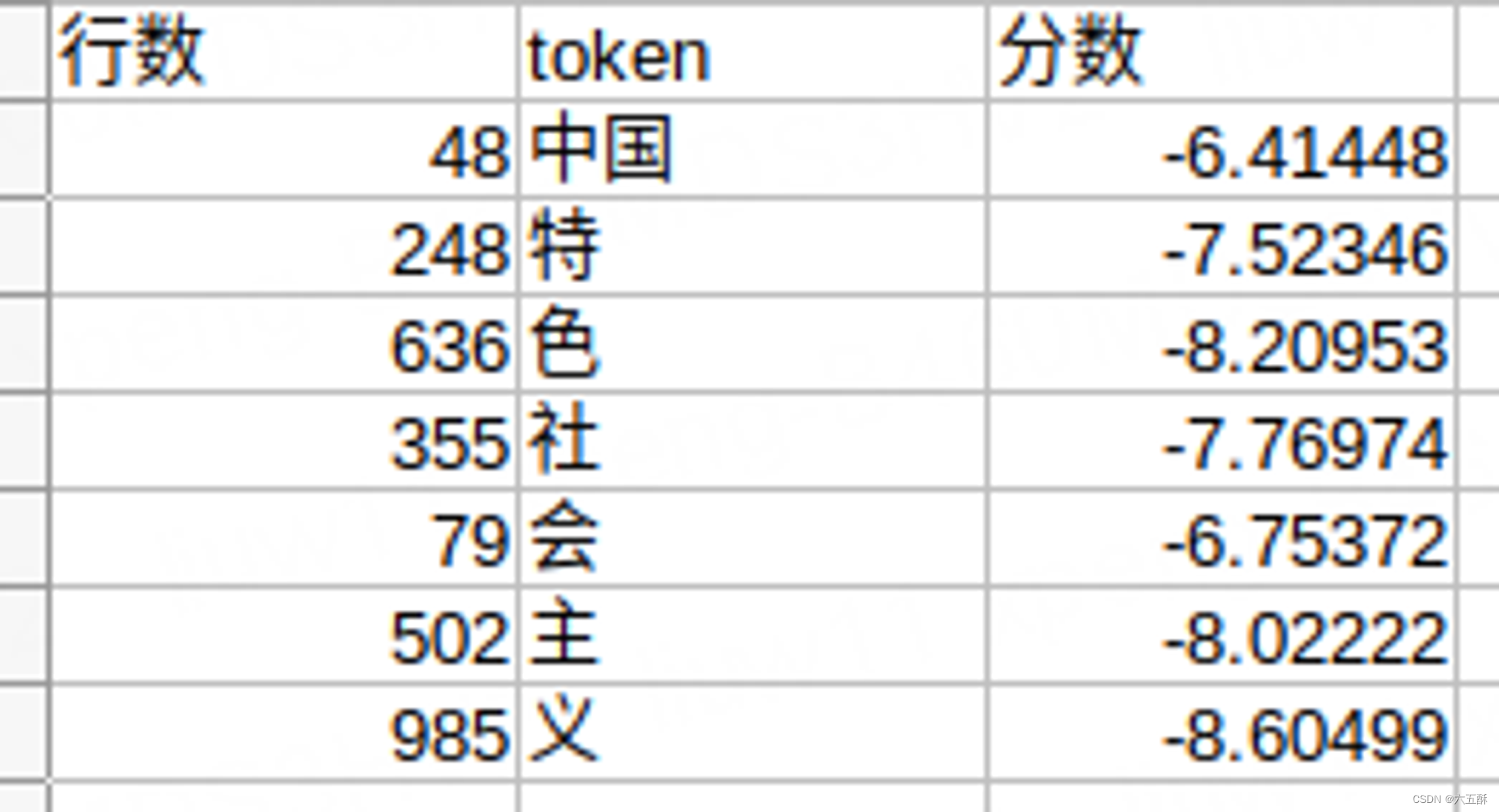
接着再进行组合,那么就是
中国特
特色
色社
社会
会主
主义
再来查看tokenizer词汇表
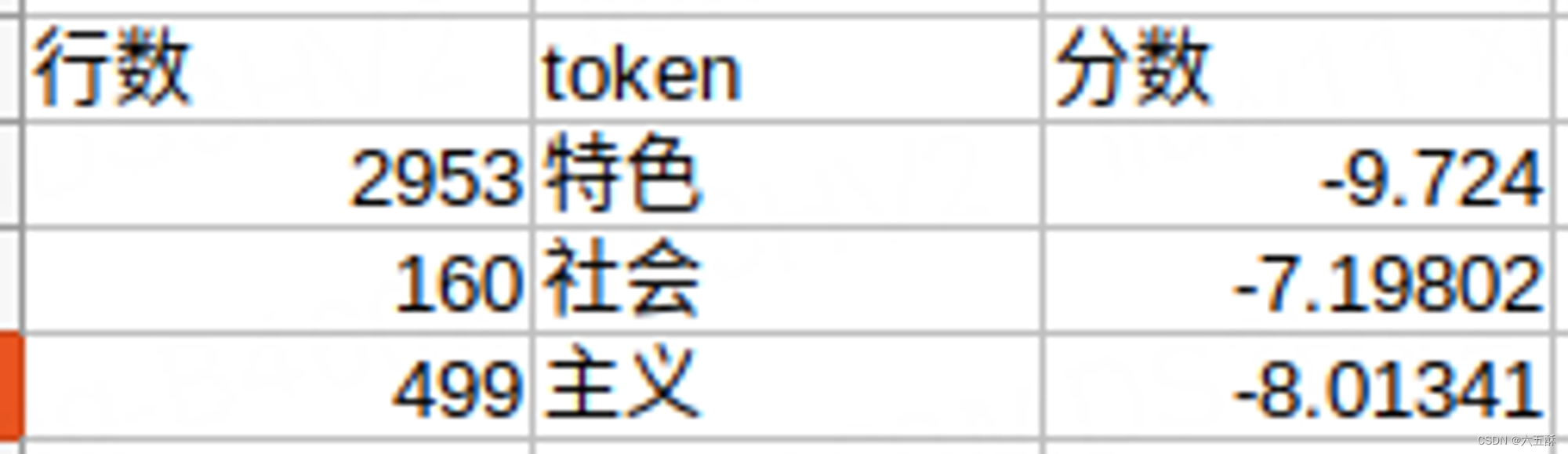
得分最高的是社会,将“社”,“会”,两个词组合到一起,因此输入的tokens变为:
将tokens两两前后合并,得到:
中国特
特色
色社会
社会主
主义
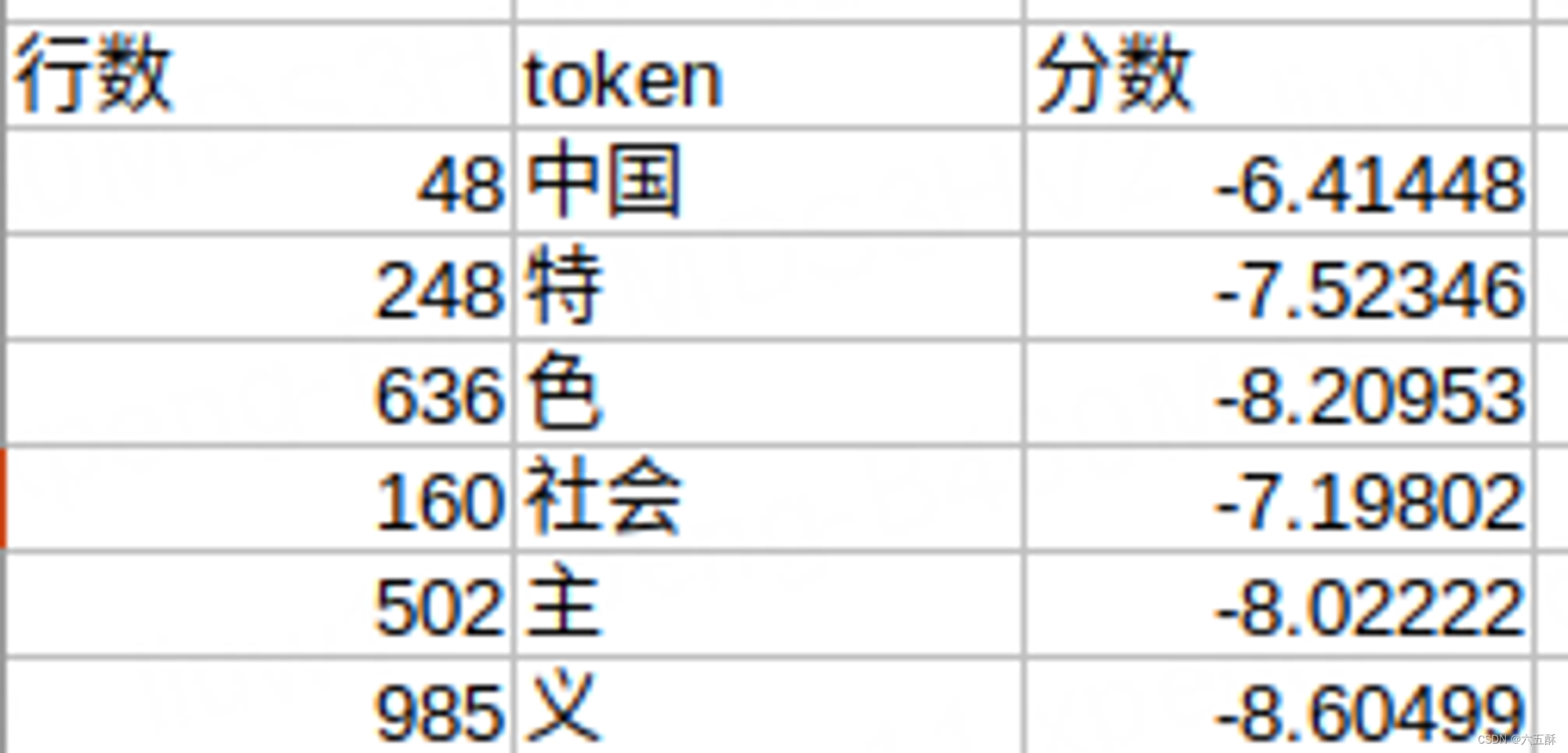
查看tokenizer词汇表

得到主义得分最低,因此tokens就变为:

然后再进行两两前后组合:
中国特
特色
色社会
社会主义
查看tokenizer词汇表

因此,tokens变为:

最后再进行组合:
中国特色
特色社会主义
在tokenizer词汇表里面已经找不到相应词汇了,此时就结束while(1)的死循环
上面可以看到最后的tokens就变成了:
tokens[0] = 中国
tokens[1] = 特色
tokens[2] = 社会主义
也就是说原本为:“中”,“国”,“特”,“色”,“社”,“会”,“主”,“义”,经过bpe_encode的处理,就变成了“中国”,“特色”,“社会主义”,原本看起来没关系的独个词汇,变成有关联
最终得到的tokens就赋值给了prompt_tokens,即变为:[48, 2953, 274],然后再补一些padding,使得输入shape一致。
6、模型推理while (pos < steps) 循环
**steps:**不是表示词汇个数,而是生成的token个数,有个token包含了多个词汇,有的token是标点符号,比如:“社会主义”,“,”
注:很多没细看,以后有空再补充
while (pos < steps) {
// forward the transformer to get logits for the next token
// 将输入数据通过 Transformer 模型进行前向传递,以获取下一个token的逻辑回归(logits)
transformer(token, pos, &config, &state, &weights);
// pos从零开始循环
// advance the state state machine
if(pos < num_prompt_tokens) {
// if we are still processing the input prompt, force the next prompt token
next = prompt_tokens[pos];
} else {
// sample the next token
if (temperature == 0.0f) {
// greedy argmax sampling: take the token with the highest probability //采用贪婪,获取最高的分数,结果只有一个
next = argmax(state.logits, config.vocab_size);
} else {
// apply the temperature to the logits //引入随机性到逻辑回归,增加结果多样性
for (int q=0; q<config.vocab_size; q++) { state.logits[q] /= temperature; }
// apply softmax to the logits to get the probabilities for next token
// 在逻辑回归中使用softmax,用于获取下个可能得token
softmax(state.logits, config.vocab_size);
// we sample from this distribution to get the next token
//从这个分布中随机取样,随机取一个token,作为下一个生成的结果
if (topp <= 0) {
// simply sample from the predicted probability distribution
// 直接从预测的概率分布中进行抽样
next = sample(state.logits, config.vocab_size);
} else {
// top-p (nucleus) sampling, clamping the least likely tokens to zero
// 使用 top-p(或称为 nucleus)抽样方法,并将最不可能的标记概率设为零
// 可以控制生成结果的多样性,并避免生成概率非常低的token
next = sample_topp(state.logits, config.vocab_size, topp, state.probindex);
}
}
}
pos++;
// data-dependent terminating condition: the BOS (1) token delimits sequences
if (next == 1) { break; }
// following BOS (1) token, sentencepiece decoder strips any leading whitespace (see PR #89)
char *token_str = (token == 1 && vocab[next][0] == ' ') ? vocab[next]+1 : vocab[next];
printf("%s", token_str);
fflush(stdout);
token = next;
//printf("next:%d\n",next);
// init the timer here because the first iteration can be slower
if (start == 0) { start = time_in_ms(); }
}
7、tokenizer拓展词汇
https://github.com/google/sentencepiece/blob/9cf136582d9cce492ba5a0cfb775f9e777fe07ea/python/add_new_vocab.ipynb
import sentencepiece.sentencepiece_model_pb2 as model
m = model.ModelProto()
m.ParseFromString(open("tokenizer1.model", "rb").read())
special_tokens = open("special_tokens.txt", "r").read().split("\n")
special_tokens = [token for token in special_tokens if token != '']
print(special_tokens)
for token in special_tokens:
new_token = model.ModelProto().SentencePiece()
new_token.piece = token
new_token.score = 0
m.pieces.append(new_token)
with open('new.model', 'wb') as f:
f.write(m.SerializeToString())
new_token = model.ModelProto().SentencePiece()
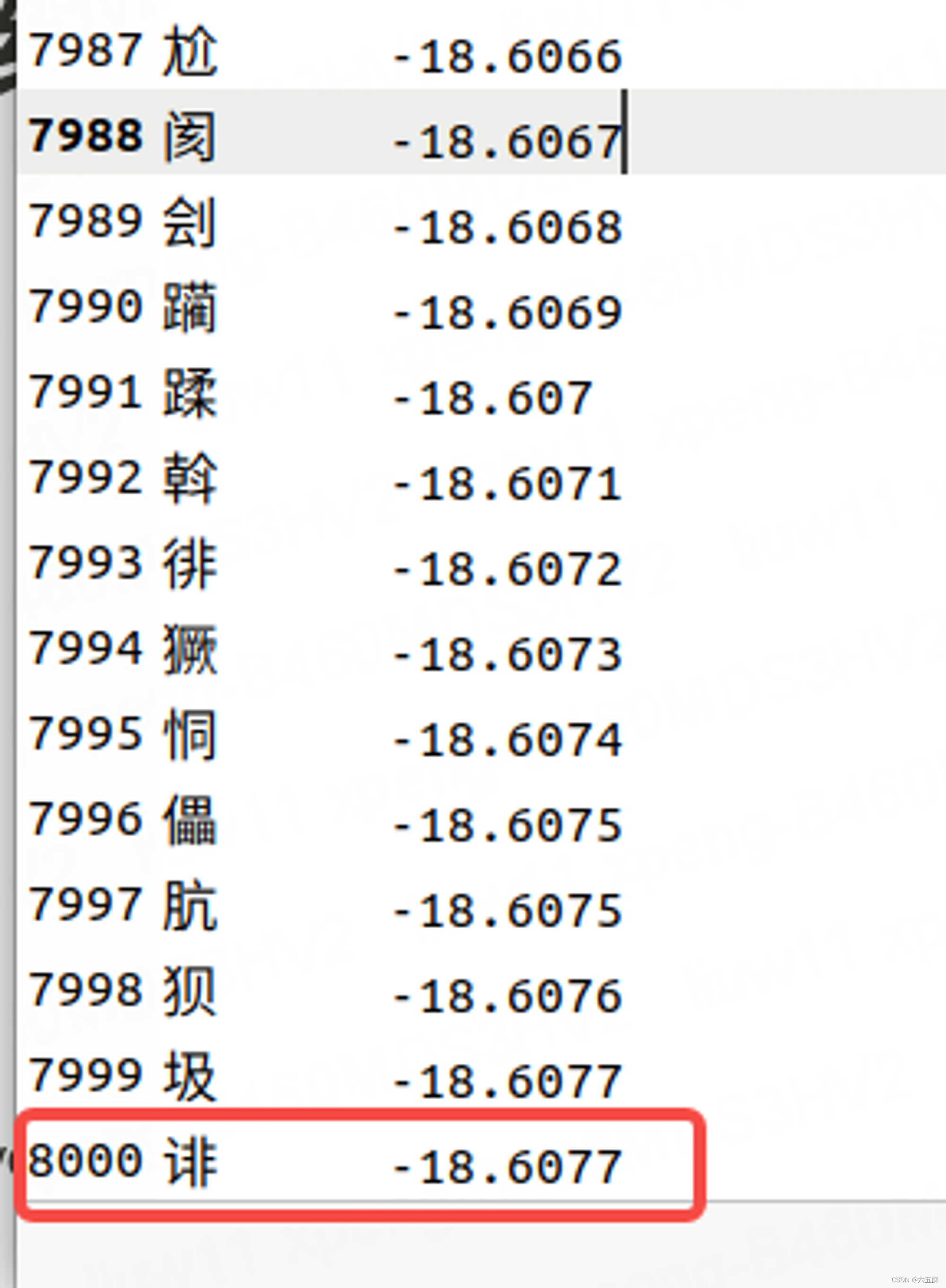
new_token.piece = token
new_token.score = -18.60770034790039
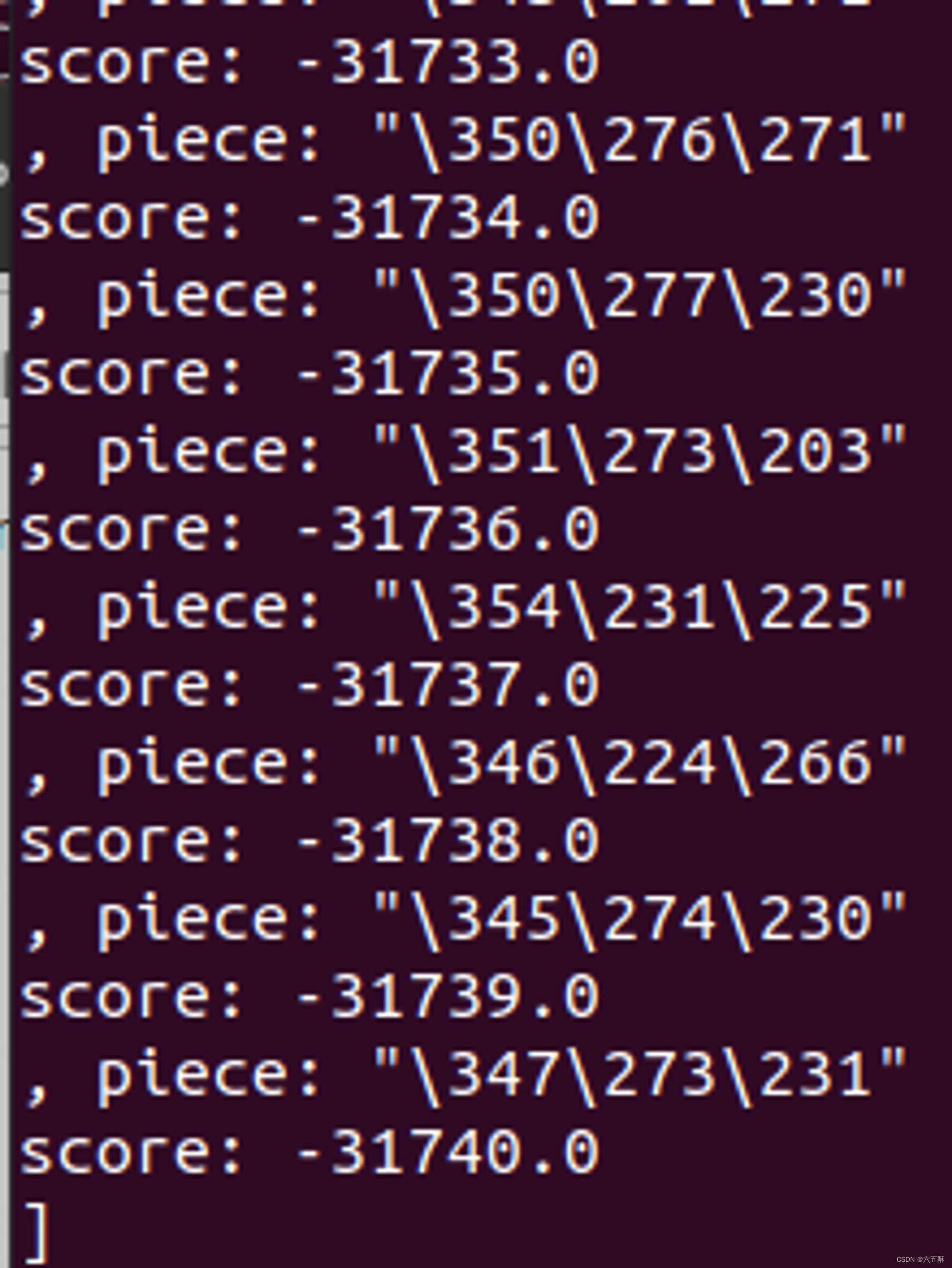
打印new_token会得到下面的内容
piece: "\350\257\275"
score: -18.60770034790039
采用UTF-8编码的,可恢复为:
utf8_bytes = b'\350\257\275'
text = utf8_bytes.decode('utf-8')
print(text)
打出来是“诽”
输出所加载模型的所有token:
print(m.pieces)