目录
🚩概念:
🚩实现:
⚡1.hoare
⚡2.挖坑法
⚡3.双指针法
🚩快速排序递归实现
🚩快速排序非递归实现
🚩概念:
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据比另一部分的所有数据要小,再按这种方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,使整个数据变成有序序列。
🌟排序过程:
1.在数组中确定一个关键值
2.将小于关键值的数排到其左边,将大于关键值的数排到其右边,此时关键数在数组中的位置就排好了
3.在左边的数据和右边的数据分别找一个关键值,通过排序使小于关键值的数排到其左边,大于关键值的数排到其右边...
4.重复上述操作,可以通过递归与非递归实现
快速排序的关键是写好步骤二的单趟排序,实现这个功能有三种版本
- hoare
- 挖坑法
- 双指针法
🚩实现:
⚡1.hoare
将数组第一个元素定位关键值,定义begin和end指针,先让end从后往前找到比关键值小的数,begin从前往后找比关键值大的数,然后交换两数,直到 begin==end,再让关键值和begin所指的元素交换,最后返回关键值所在位置,便于后续进行递归或非递归操作(一定要先从后往前找小,原因下文解释)
动态展示:

void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//hoare
int PartSort1(int* a, int begin, int end)
{
int left = begin, right = end;
int keyi = begin;
while (left < right)
{
//右边找小
while (left < right && a[right] >= a[keyi])
{
right--;
}
//左边找大
while (left < right && a[left] < a[keyi])
{
left++;
}
swap(&a[left], &a[right]);
}
swap(&a[left], &a[keyi]);
return left;
}⚡2.挖坑法
首先将关键值定为数组第一个元素,并将坑位定为begin,先让end从后往前找到比关键值小的数,将这个数放到坑位,并更新坑位,再让begin从前往后找比关键值大的数,将这个数放到坑位,并更新坑位,直到 begin==end,再让关键值和坑位的元素交换,最后返回关键值所在位置
//挖坑法
int PartSort2(int* a, int begin, int end)
{
int mid = GetMid(a, begin, end);
swap(&a[begin], &a[mid]);
int key = a[begin];
int hole = begin;
while (begin < end)
{
//右边找小,填入坑内,更新坑位
while (begin<end && a[end]>=key)
{
--end;
}
a[hole] = a[end];
hole = end;
//左边找大,填入坑内,更新坑位
while (begin<end && a[begin]<=key)
{
++begin;
}
a[hole] = a[begin];
hole = begin;
}
a[hole] = key;
return hole;
}⚡3.双指针法
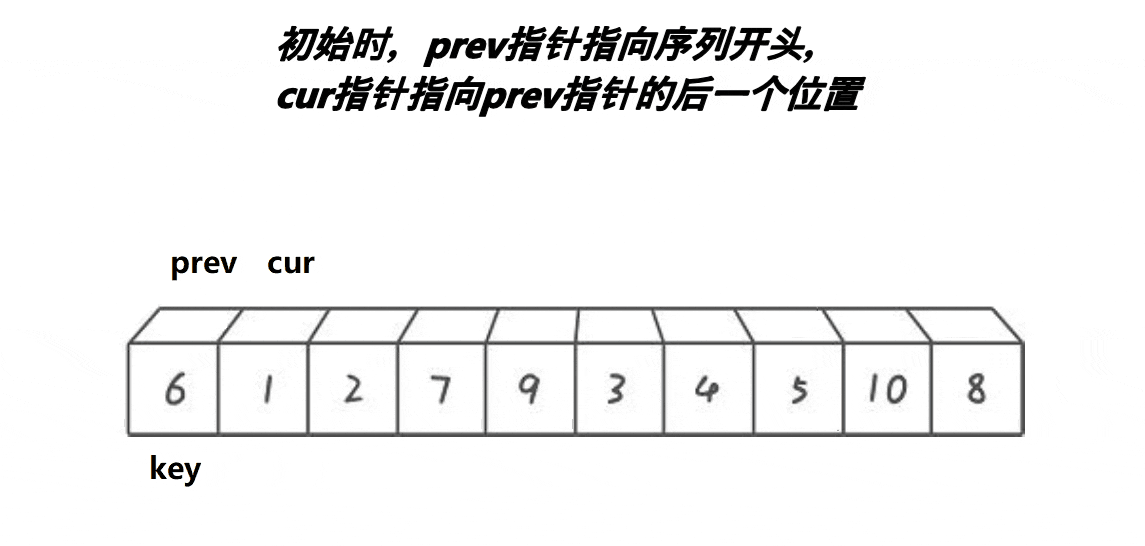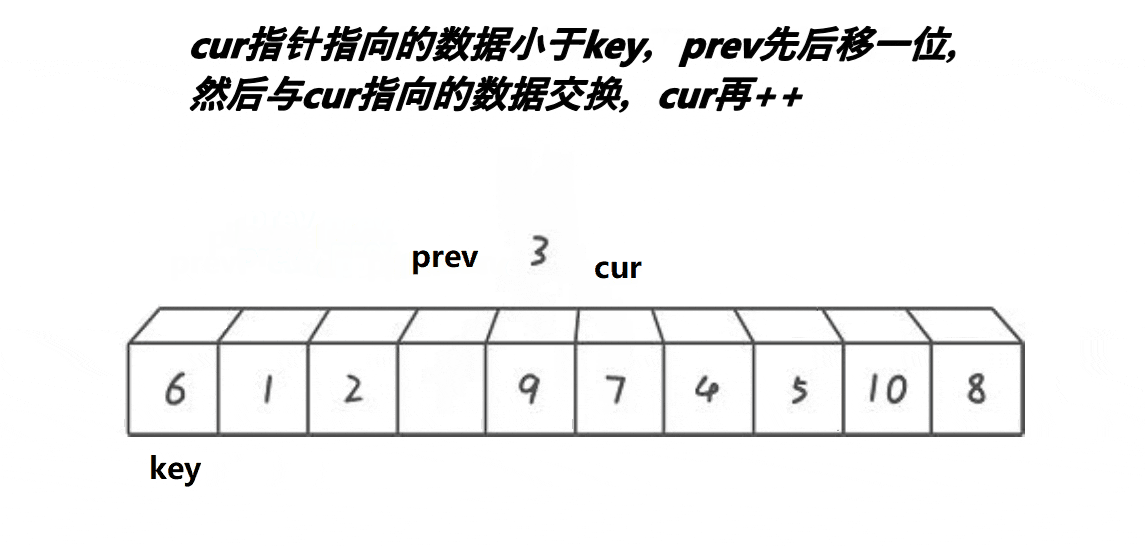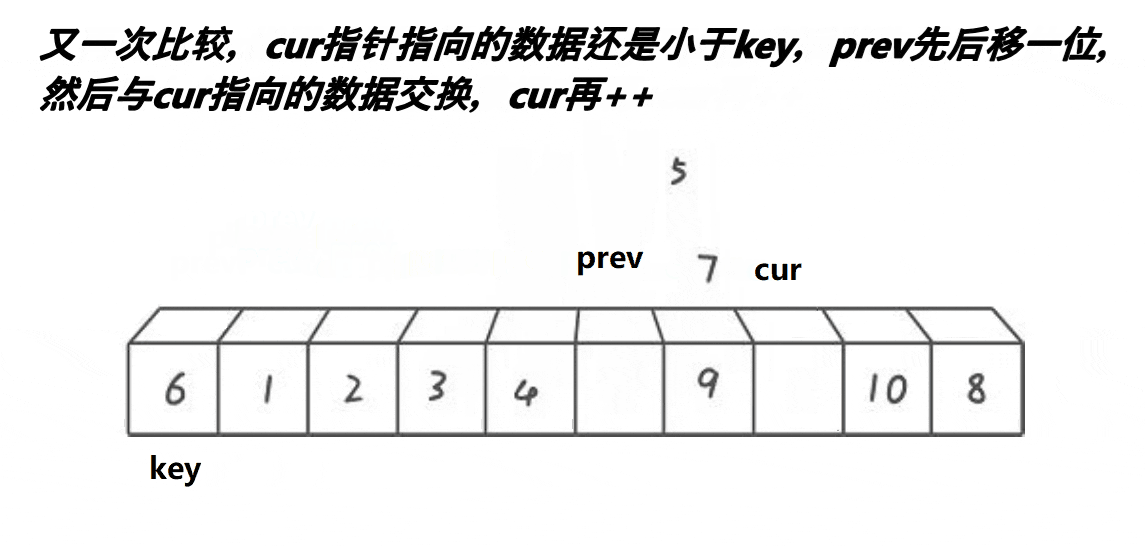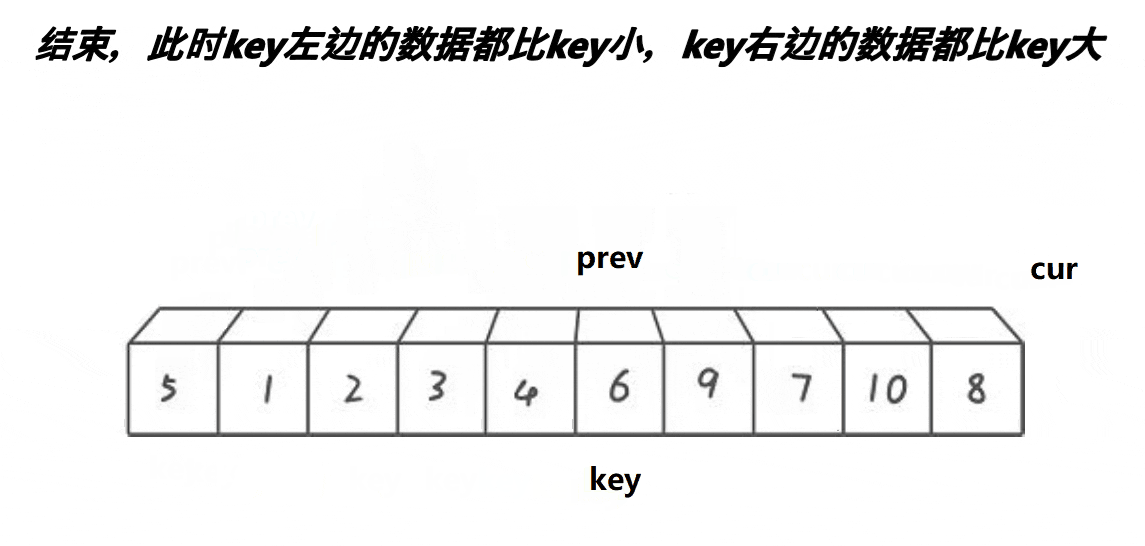
将数组第一个元素定为关键值,定义两个指针prev和cur,先让prev指向数组的第一个元素,cur指向prev的下一个元素,cur的作用是找比关键值小的元素,若cur所指元素不小于关键值则cur++,直到cur所值元素小于关键值,此时,prev和cur之间的元素都是大于关键值的元素,若prev+1不是cur的话就可以让prev++所指元素与cur所指元素交换了,直到cur指向数组的最后一个元素
这里可能会有人出现问题:
1.为什么要判断 prev++!=cur
[解释]:如果prev+1为cur的话,那交换prev++和cur所指元素那就是一个元素之间的交换了,没有意义
2.为什么要交换prev++所指元素
[解释]:因为prev和cur之间的元素都为大于关键值的元素,prev++就可以让prev指向大于关键值的元素,而cur所指的是小于关键值的元素,这样一交换小的数就去前面了,大的数就去后面了
//双指针法
int PartSort3(int* a, int begin, int end)
{
int mid = GetMid(a, begin, end);
swap(&a[begin], &a[mid]);
int key = begin;
int prev = begin;
int cur = prev + 1;
while (cur <= end)
{
if (a[cur] < a[key] && ++prev != cur)
{
swap(&a[prev], &a[cur]);
}
cur++;
}
swap(&a[prev], &a[key]);
return prev;
}🚩快速排序递归实现
⛲小优化:
上述三个方法都是快速排序的单趟排序,但是上述排序还有一个小缺陷,因为三个方法都是固定第一个元素为关键值的,如果数组为有序的,那么从后往前找小就要遍历整个数组,效率会很小,所以通常会再写一个找中间值的函数:在数组开头结尾和中间三个数中找出一个大小在中间的数,并让这个数和数组第一个数交换,这样就会减少上述情况的发生
int GetMid(int* a, int begin, int end)
{
int mid = (begin + end) / 2;
if (a[begin] > a[mid])
{
if (a[mid] > a[end])
return mid;
else if (a[end] > a[begin])
return end;
else
return begin;
}
else
{
if (a[begin] > a[end])
return begin;
else if (a[end] > a[mid])
return mid;
else
return end;
}
}
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//hoare
int PartSort1(int* a, int begin, int end)
{
int mid = GetMid(a, begin, end);
swap(&a[begin], &a[mid]);
int left = begin, right = end;
int keyi = begin;
while (left < right)
{
//右边找小
while (left < right && a[right] >= a[keyi])
{
right--;
}
//左边找大
while (left < right && a[left] < a[keyi])
{
left++;
}
swap(&a[left], &a[right]);
}
swap(&a[left], &a[keyi]);
return left;
}
//挖坑法
int PartSort2(int* a, int begin, int end)
{
int mid = GetMid(a, begin, end);
swap(&a[begin], &a[mid]);
int key = a[begin];
int hole = begin;
while (begin < end)
{
//右边找小,填入坑内,更新坑位
while (begin<end && a[end]>=key)
{
--end;
}
a[hole] = a[end];
hole = end;
//左边找大,填入坑内,更新坑位
while (begin<end && a[begin]<=key)
{
++begin;
}
a[hole] = a[begin];
hole = begin;
}
a[hole] = key;
return hole;
}
//双指针法
int PartSort3(int* a, int begin, int end)
{
int mid = GetMid(a, begin, end);
swap(&a[begin], &a[mid]);
int key = begin;
int prev = begin;
int cur = prev + 1;
while (cur <= end)
{
if (a[cur] < a[key] && ++prev != cur)
{
swap(&a[prev], &a[cur]);
}
cur++;
}
swap(&a[prev], &a[key]);
return prev;
}
void QuickSort(int* a, int begin,int end)
{
if (begin >= end)
return;
//三种方法任选其一即可
int keyi = PartSort3(a, begin, end);
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
补充:
为什么开始一定要右边找小,并且为什么left和right相遇那个点一定小于关键值呢?
[解释]:
L遇到R有两种情况
- R遇到L: R从右往左找小,一直没找到小,直到遇到L,而L的点的值小于关键值(因为此时L的值是和上一轮R找的小的值)
- L遇到R:R先从右找小,找到小停下来,L从左往右找打大没有找到遇到R,相遇点的值小于关键值
🚩快速排序非递归实现
快速排序的递归实现,无非就是通过调用函数对数组的不同区间进行排序,而非递归我们也可以用栈实现,不是递归胜似递归.
实现思路:
1.创建一个栈,将数组的右边界下标和左边界下标依次入栈
2.循环弹出数组的左右边界下标,并对该区间进行单趟排序,确定关键值的下标,分为左右两个区间
3.若左区间元素个数大于一个,将左区间右边界下标和左边界下标依次入栈,右区间同理
4.重复操作步骤2 3直到栈为空
例如待排序数组为:

第一步:将右边界下标和左边界下标7和0入栈

第二步:将边界值弹出,将0给到begin,7给到end,进行单趟排序(单趟排序采用挖坑法)
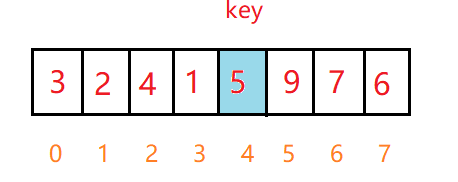
排序完后,key将数组分为了左右两个区间,让右区间边界7和5入栈,左边界3和0入栈

第三步:取出0 3并对此区间单趟排序

此时,关键值又把区间分为了两个区间,右区间只有一个值,没必要入栈排序,只需要将左区间边界1 0入栈
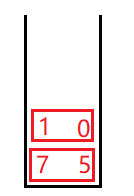
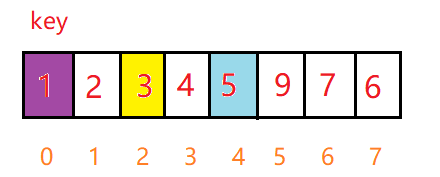
再弹出0 1,对此区间单趟排序,此时左区间无元素,有区间只有一个元素,这样数组左边就全部排序完成了,再次出栈的话就该排序5和7的区间了,和左边类似
void QuickSortNonR(int* a, int begin, int end)
{
ST s;
STInit(&s);
STPush(&s,end);
STPush(&s,begin);
while (!STEmpty(&s))
{
int left = STTop(&s);
STPop(&s);
int right = STTop(&s);
STPop(&s);
int key = PartSort1(a, left, right);
if (left < key - 1)
{
STPush(&s, key - 1);
STPush(&s, left);
}
if (right > key + 1)
{
STPush(&s, right);
STPush(&s, key+1);
}
}
STDestroy(&s);
}