这次做一篇2D多目标跟踪中使用对比学习的一些方法.
对比学习通过以最大化正负样本特征距离, 最小化正样本特征距离的方式来实现半监督或无监督训练. 这可以给训练MOT的外观特征网络提供一些启示. 使用对比学习做MOT的鼻祖应该是QDTrack, 本篇博客对QDTrack及其后续工作做一个总结.
持续更新…
1. QDTrack
论文: QDTrack: Quasi-Dense Similarity Learning for Appearance-Only Multiple Object Tracking (TPAMI2023)
1.1 主要思想
外观特征在跟踪中是非常重要的线索. 训练外观特征网络的方式有很多, 例如最开始JDE, Fairmot将外观特征网络的训练问题转换为分类问题, 也即每个目标(identity)都自成一类. 然而, 这样一个数据集中可能有成千上万个类, 但是外观特征的维度往往不会很大, 这样就给这个分类网络的训练带来了一定的困难.
如果采用对比学习的方式, 我们每次只关注若干正样本和若干负样本, 我们要做的就是拉大正负样本之间的距离就可以了, 实际上这时候就减少了一些训练的难度. 然而, 我们知道, 对于对比学习来说, 通常来讲样本量越多越好, batch size越大越好. 基于这个认识, QDTrack提出了一种密集采样的方法增大正负样本数量, 进而提高对比学习性能. 同时, 将MOT的关联问题就转换为了求特征距离, 不需要依赖于运动特征.
1.2 具体方法
训练过程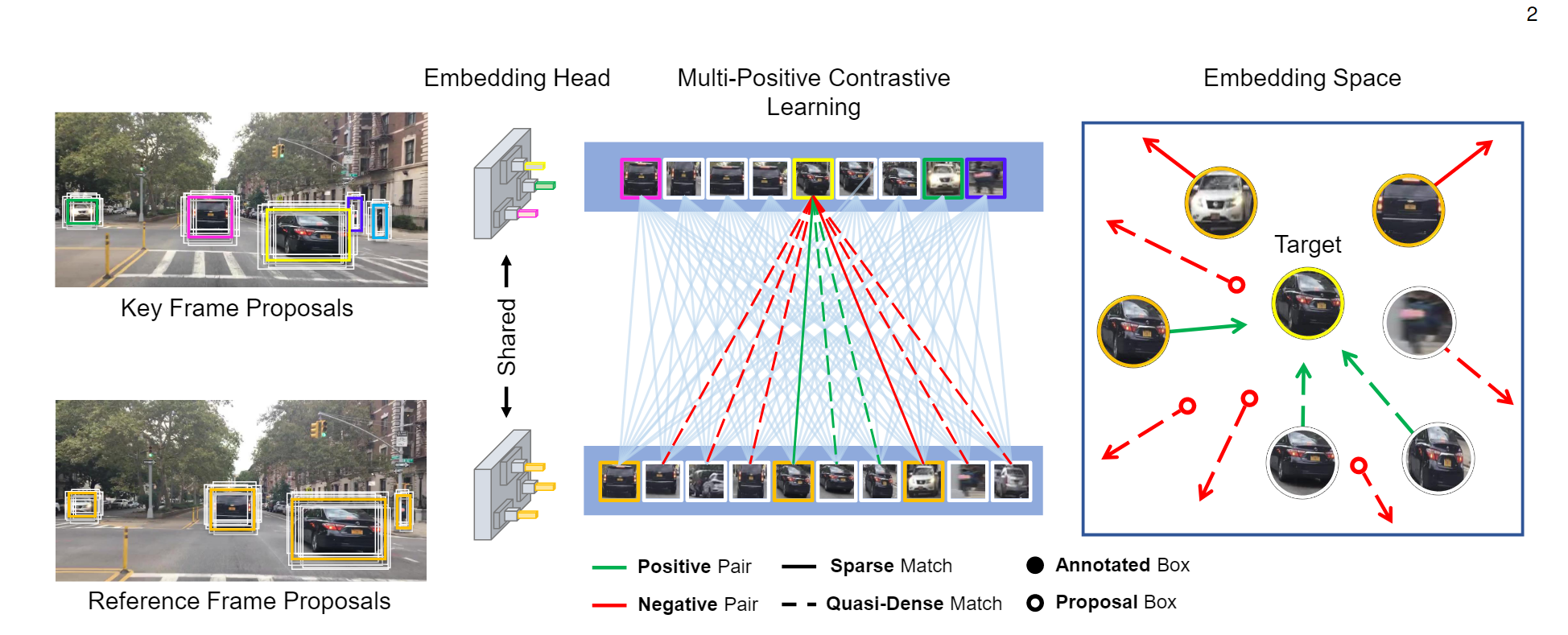
算法流程是这样的. 首先, 选定一帧
I
1
I_1
I1表示key frame, 然后在其附近的时序上再随机采样一帧
I
2
I_2
I2作为reference frame. QDTrack是可以和检测器一起端到端训练的, 因此我们可以根据检测器的结果定位每个目标, 并采用ROI Align方法将每个目标对应区域的特征都提出来.
正负样本的定义: 对于预测的一个边界框, 如果它和某个真值的IoU大于 α 1 \alpha_1 α1, 则认为该边界框是真值的正样本; 如果IoU大于 α 2 \alpha_2 α2, 则认为该边界框是真值的负样本. 对于时序上, key frame和reference frame的两个边界框对应同一个目标, 则该样本对为正, 否则为负.
如果key frame上有 V V V个样本, reference frame上有 K K K个样本, 则对于一个正样本对 ( v , k + ) (\mathbf{v}, \mathbf{k^+}) (v,k+), 损失函数为:
L e m b e d = − log exp ( v k + ) exp ( v k + ) + ∑ k − exp ( v k − ) \mathcal{L}_{embed} = - \log \frac{ \exp ({\mathbf{v} \mathbf{k^+}})} {\exp ({\mathbf{v} \mathbf{k^+}})+\sum_{\mathbf{k^-}}\exp ({\mathbf{v} \mathbf{k^-}})} Lembed=−logexp(vk+)+∑k−exp(vk−)exp(vk+)
其中 v , k + , v , k − \mathbf{v}, \mathbf{k^+}, \mathbf{v}, \mathbf{k^-} v,k+,v,k−分别表示key frame的某个样本, 以及它对应的正负样本的特征,
在QDTrack的设计中, 最重要的就是通过密集匹配去增加样本对. 也就是说, 一个key frame的样本要和所有reference frame的样本进行对应. 损失要对所有的正样本求和, 有:
L e m b e d = − ∑ k + log exp ( v k + ) exp ( v k + ) + ∑ k − exp ( v k − ) \mathcal{L}_{embed} = - \sum_{\mathbf{k^+}}\log \frac{ \exp ({\mathbf{v} \mathbf{k^+}})} {\exp ({\mathbf{v} \mathbf{k^+}})+\sum_{\mathbf{k^-}}\exp ({\mathbf{v} \mathbf{k^-}})} Lembed=−k+∑logexp(vk+)+∑k−exp(vk−)exp(vk+)
整理一下:
L e m b e d = − ∑ k + log exp ( v k + ) exp ( v k + ) + ∑ k − exp ( v k − ) = ∑ k + log exp ( v k + ) + ∑ k − exp ( v k − ) exp ( v k + ) = ∑ k + log [ 1 + ∑ k − exp ( v k − − v k + ) ] \mathcal{L}_{embed} = - \sum_{\mathbf{k^+}}\log \frac{ \exp ({\mathbf{v} \mathbf{k^+}})} {\exp ({\mathbf{v} \mathbf{k^+}})+\sum_{\mathbf{k^-}}\exp ({\mathbf{v} \mathbf{k^-}})} \\ = \sum_{\mathbf{k^+}}\log \frac{\exp ({\mathbf{v} \mathbf{k^+}})+\sum_{\mathbf{k^-}}\exp ({\mathbf{v} \mathbf{k^-}})} {\exp ({\mathbf{v} \mathbf{k^+}})} \\ =\sum_{\mathbf{k^+}}\log [1 + \sum_{\mathbf{k^-}}\exp(\mathbf{v} \mathbf{k^-}-\mathbf{v} \mathbf{k^+}) ] Lembed=−k+∑logexp(vk+)+∑k−exp(vk−)exp(vk+)=k+∑logexp(vk+)exp(vk+)+∑k−exp(vk−)=k+∑log[1+k−∑exp(vk−−vk+)]
上面这个式子将外层的求和放到log里就是连乘号, 计算量比较大, 因此作者采用了一种等价的方式:
L e m b e d = log [ 1 + ∑ k + ∑ k − exp ( v k − − v k + ) ] \mathcal{L}_{embed} = \log [1 + \sum_{\mathbf{k^+}} \sum_{\mathbf{k^-}}\exp(\mathbf{v} \mathbf{k^-}-\mathbf{v} \mathbf{k^+}) ] Lembed=log[1+k+∑k−∑exp(vk−−vk+)]
同时, 还加入了一个辅助的损失函数, 使得正样本对之间相似度接近1, 否则接近0:
L a u x = ( v k ∣ ∣ v ∣ ∣ ∣ ∣ k ∣ ∣ − c ) 2 \mathcal{L}_{aux} = (\frac{\mathbf{v} \mathbf{k}}{||\mathbf{v} |||| \mathbf{k}||} - c)^2 Laux=(∣∣v∣∣∣∣k∣∣vk−c)2
其中正样本对对应的是 c = 1 c=1 c=1, 否则 c = 0 c=0 c=0.
为了和检测器端到端训练, 最终的损失函数就是检测损失, L e m b e d , L a u x \mathcal{L}_{embed}, \mathcal{L}_{aux} Lembed,Laux的加权和.
推理过程
推理过程主要是两个创新点. 一个是类间NMS, 这是因为有时候检测器的分类会不准确, 导致同一个目标, 但是出现两个重叠边界框, 这两个边界框被分到不同的类. 所以作者采用了一个类间NMS.
一个是对于外观相似度计算, 没有简单地采用余弦相似度的形式, 而是采用了双向softmax. 本质是差不多的, 就是softmax考虑了所有样本的信息计算相似度. 从消融实验的结果看, 采用密集正样本和双向softmax对效果的提升都是比较明显的.
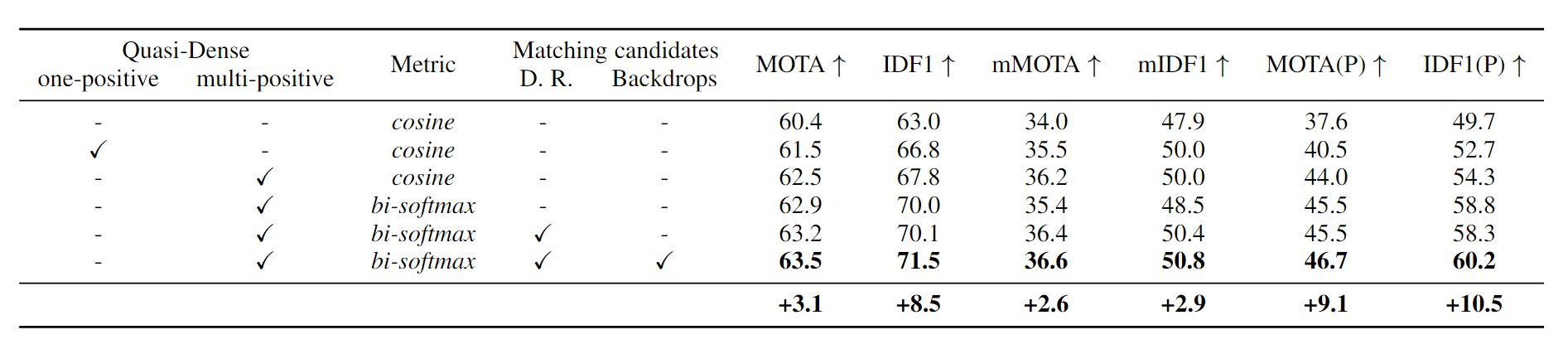
2. Towards Discriminative Representation: Multi-view Trajectory Contrastive Learning for Online Multi-object Tracking
论文: Towards Discriminative Representation: Multi-view Trajectory Contrastive Learning for Online Multi-object Tracking (CVPR2022)
2.1 主要思想
类似于QDTrack这种方法, 往往只在相邻的时域当中取样本对, 而没有很好地利用整个轨迹时域上的信息. 针对这个问题, 这篇工作利用历史轨迹的信息更全面地描述一个目标, 进行对比学习.
他们将历史轨迹表示成一个向量, 并存储到一个动态的memory bank中. 并以此构建了以轨迹为中心的对比学习, 就可以利用好丰富的帧间信息. 这就是题目Multi-view的由来.
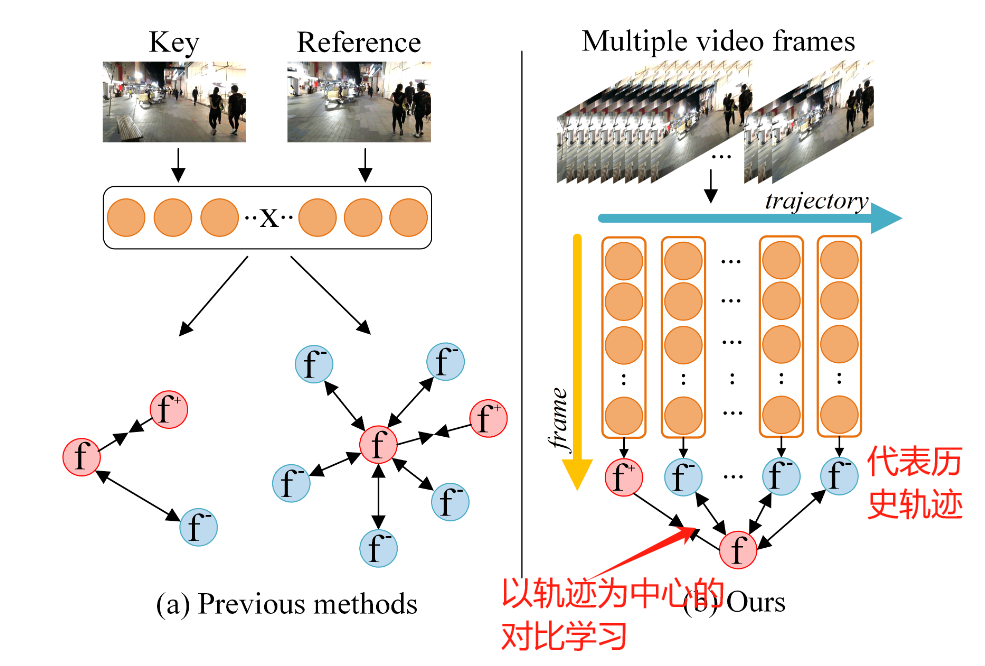
2.2 具体方法
论文的创新点一共有三个, 下面逐一介绍:
1.Learnable view sampling
作者的方法称为MTrack. MTrack是基于Fairmot改的. 当然, Fairmot是基于CenterNet, 把backbone换成了DLA-34. CenterNet是以点作为目标中心, 无锚检测器, 但作者认为只用一个点代表目标是不行的, 是因为目标的中心点可能被遮挡, 并且为对比学习产生的样本对也不足.
为了解决这个问题, 作者就加了一个线性层, 去根据目标的中心点坐标预测更多的采样点坐标, 当然, 采样点要在边界框的范围内. 这些采样点都代表了同一个目标, 也就产生了很多正样本. (注意一个点的特征直接就是从预测的heatmap上提取的).
2. Trajectory-center memory bank
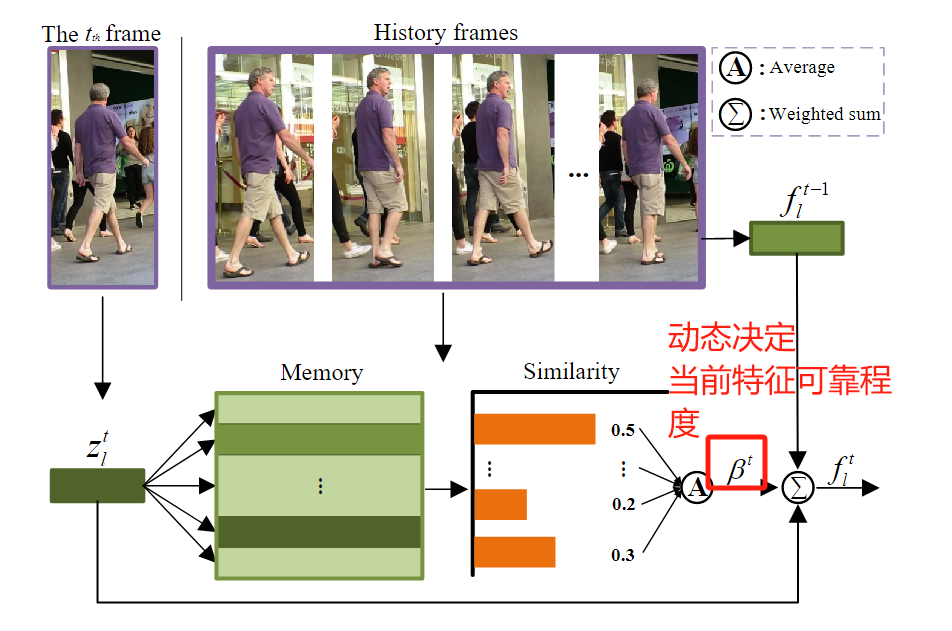
作者是如何用一个向量代表一个历史轨迹的呢?
在训练阶段, 网络以许多帧作为输入, 并检测出每个帧中所有的检测样本. 根据Learnable view sampling, 每个检测样本可以衍生出 N k N_k Nk个特征向量.
在训练阶段, 每个检测都有对应的轨迹ID (为什么? 作者没有解释). 那么, 我们就可以以当前帧检测的特征去更新memory bank中的特征. 当然, 作者在这里选择的策略是"hardest sample", 也就是选择特征最不相似的一个(用余弦距离衡量)线性更新memory bank中的对应特征.
对于损失函数, 对每一个外观特征向量 v ~ l k \tilde{v}_l^k v~lk (下标 l l l表示属于的ID, 上标 k k k表示序数), 去拉进它和它对应ID轨迹中心的距离, 放大它和其他ID轨迹中心的距离, 采用对比学习常用的InfoNCE Loss: (Softmax + 一个temperature parameter):
L N C E k = − log exp ( v ~ l k c l ) / τ ∑ i exp ( v ~ l k c i ) / τ L_{NCE}^k = - \log \frac{\exp (\tilde{v}_l^k c_l) / \tau} {\sum_i \exp (\tilde{v}_l^k c_i) / \tau} LNCEk=−log∑iexp(v~lkci)/τexp(v~lkcl)/τ
因此, 对于所有的外观embedding, 总损失为
L T C L = 1 N a ∑ k = 1 N a L N C E k L_{TCL} = \frac{1}{N_a} \sum_{k=1}^{N_a} L_{NCE}^k LTCL=Na1k=1∑NaLNCEk
最终的损失仿照Fairmot, 采用uncertainty loss.
总的训练框图如下:
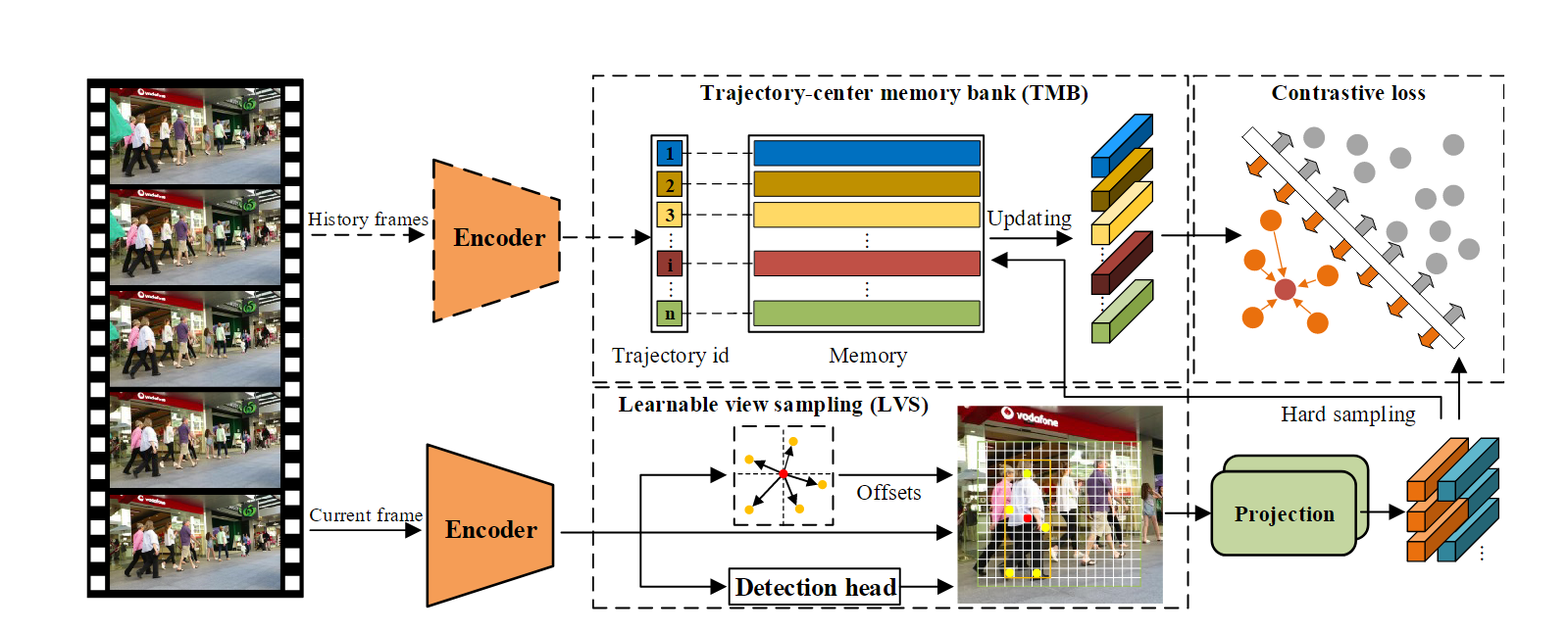
推理阶段比较正常, 主要是提出了一个根据历史和现在特征余弦相似度度进行轨迹特征融合的方法. 如果和过去相似, 就取信于当前的特征, 否则不取信. 这个也是很多方法都有的.




![[机器人-3]:开源MIT Min cheetah机械狗设计(三):嵌入式硬件设计](https://img-blog.csdnimg.cn/img_convert/1d14f7d5981ce07a7f3fcd1811fc45e8.webp?x-oss-process=image/format,png)