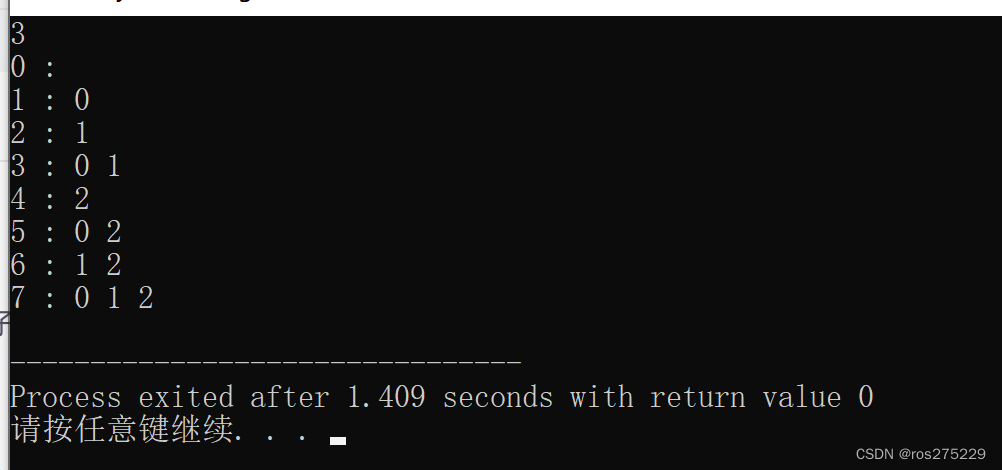
第一题:
def func(a, b=[]): pass
一、上题讲解:
这个函数定义有一个默认参数b,它的默认值是一个空列表[]。这道面试题涉及到Python中函数参数默认值的一些重要概念和陷阱。
首先,当你调用这个函数时,如果不传递参数b的值,它将使用默认的空列表[]。例如:
func(1) # 这会将a设置为1,b设置为默认的空列表[]
但是,这里有一个陷阱。默认参数b(即空列表[])在函数定义时只会被创建一次,而不是每次函数调用时都会创建一个新的空列表。这就意味着,如果你在一个函数调用中修改了b的值,那么下一次调用该函数时,b将保留上一次的修改。
例如:
func(1) # a=1, b=[]
b.append(2)
func(3) # a=3, b=[2]
在上面的例子中,我们首先调用了func(1),然后在b上执行了append(2)操作,导致b变成了[2]。接下来,我们调用了func(3),此时a被设置为3,但b仍然是[2],而不是一个新的空列表[]。
这种行为可能会导致一些不直观的问题和bug,因为使用者可能期望每次调用函数时都会得到一个独立的空列表。
为了避免这种问题,我们可以使用None作为默认值,并在函数内部检查b是否为None,然后在需要时创建一个新的空列表。例如:
def func(a, b=None):
if b is None:
b = []
# 现在每次函数调用都会得到一个新的空列表
# 其他函数逻辑
这样做可以确保每次调用函数时都会得到一个新的空列表,避免了默认参数共享的问题。
二、是什么导致的上述问题:
这是因为在Python中,默认参数在函数定义时只会被创建一次,并且在函数的整个生命周期内都会保留它们的状态。这是为了提高函数的性能和效率。
当你定义一个函数时,Python会在函数的定义阶段创建默认参数的值,然后将这些值存储在函数的代码对象中。这意味着每次调用函数时,不会重新创建默认参数的新实例,而是会重用已经存在的默认参数。
这种行为有一些优点和一些潜在的陷阱:
优点:
- 提高了函数的性能,因为不需要每次函数调用都创建新的默认参数对象。
- 可以实现一些有用的功能,例如在多次函数调用之间共享状态。这可以在某些情况下很有用。
潜在的陷阱:
- 如果默认参数是可变对象(如列表或字典),并且在函数内部进行了修改,那么这些修改会在后续函数调用中保留下来,可能导致不直观的行为。
- 开发者需要谨慎处理默认参数,以避免意外共享状态的问题。
要避免默认参数共享状态的问题,可以使用None作为默认参数的值,并在函数内部检查并创建新的实例,如上解决的方法所示。
总之,Python的默认参数在函数定义时只会被创建一次,这是出于性能和实现的考虑,但在使用可变对象作为默认参数时需要特别小心,以避免不希望的副作用。
第二题:
val = [lambda: i + 1 for i in range(10)]
data = val[0]()
print(data)
这道面试题涉及到Python中的lambda函数和列表推导式,并且可能会引发一个常见的陷阱,即闭包与变量作用域的问题。
将上述代码拆开来看:
def a():
return i + 1
s = []
for i in range(10):
s.append(a)
print(s[0]())
相信很多小伙伴看到上述拆开的代码都已经能理解本道面试题的精髓所在了。
但也请继续看下原理,是否和你想的一样~
讲解原理:
首先,列表推导式 [lambda: i + 1 for i in range(10)] 创建了一个包含 10 个 lambda 表达式的列表,每个 lambda 表达式在调用时都会返回 i + 1 的值。**需要注意的是这里每个 lambda 表达式都是一个闭包,它们“记住”了变量 i 的值。 然而,关键之处在于 lambda 表达式记住的是变量 i 而非 i 当时的值。**由于列表推导式内的 i 是在单个作用域内循环的,因此当列表推导式结束时,i 的值将停留在最后一次循环的值,即 9。 之后的代码 data = val[0]选择列表中的第一个 lambda 函数并调用它。因为所有的 lambda 闭包都是对同一个 i 的引用,这时 i 的值是循环结束时的值 9。因此,无论调用列表中的哪一个 lambda 表达式,它都能返回 9 + 1,即 10。
这是因为,**在 Python 的 for 循环中,循环变量 i 会被绑定到列表推导式的外部作用域,而不是每次迭代都创建一个新的作用域。**所以,所有的 lambda 表达式都引用着同一个 i 变量,而在循环结束时,i 的值为 9。 要让每个 lambda 表达式保留它被定义时的 i 值,可以使用默认参数来捕获i的值,以确保每个lambda函数都捕获到不同的值:
val = [lambda i=i: i + 1 for i in range(10)]
data = val[0]()
print(data)
上面修改后的代码中,lambda i=i: i + 1 为每个 lambda 函数创建了一个默认参数 i,它的值在定义 lambda 函数时就被确定下来了。这时,val[0]会输出 1,因为它将使用列表推导式中第一次迭代时 i 的值,即 0,然后加 1。
第三题:
老生常谈,请讲一讲迭代器,生成器,可迭代对象,装饰器,并讲一下它们各自的应用场景。
首先,迭代器(Iterator)、生成器(Generator)、可迭代对象(Iterable)都与遍历数据集合相关,但各有特点,所以放一起讲:
1.1 迭代器(Iterators):
迭代器是遵循迭代器协议的对象,这意味着迭代器对象需要实现两个方法:__iter__() 和 __next__()。__iter__() 返回迭代器对象本身,而 __next__() 方法返回容器中的下一个元素。当迭代器中没有更多元素时,__next__()应该抛出一个 StopIteration 异常。迭代器允许一个对象对一组数据进行遍历,但不需要此数据在内存中完全展开。
-
Python的内置容器类型:
如列表、元组、字典等,都提供了迭代器。例如,当你在列表上调用
__iter__()函数时,会返回一个迭代器,该迭代器可以遍历列表的所有元素。 -
使用场景:
当需要访问集合中的元素而不暴露底层表示时;
当需要一个能够记住遍历位置的对象时,以便在需要时能够从同一位置继续。
1.2 生成器(Generators):
生成器是一种特殊的迭代器,更容易编写。**当需要一次一个地按顺序生成一个序列的值时,使用生成器是非常有用的。**生成器函数使用 yield 语句,每次产生(yield)一个值,函数的状态会被挂起,直到下一个值被请求时再恢复。 生成器表达式是另一种构建生成器的方式,它看起来像列表推导式,但使用圆括号而不是方括号。
-
使用场景:
当需要一个懒序列(lazy sequence),该序列按需计算元素而不是预先计算,并且不希望一次性加载所有元素到内存中;
当处理的是流式数据或大数据集合,只需要一次处理一部分数据;
当需要一个函数来生成无穷序列下的元素。
1.3 可迭代对象(Iterables):
可迭代对象是实现了 __iter__() 方法的任何 Python 对象,__iter__() 需要返回一个迭代器。另外,可迭代对象也可以实现 __getitem__() 方法,以便按照索引访问元素。字符串、列表等 Python 标准类型都是可迭代的。
class Demo(object):
def __iter__(self):
return iter([1, 2, 3])
obj = Demo()
-
使用场景:
在使用 for 循环时,你通常会迭代一个可迭代对象;
当需要一种方式可以一次访问一组元素,而无需将它们全部保存在内存中;
在使用 map()、filter()、sum()、min()、max() 等内置函数时,这些函数接受一个可迭代对象作为参数
1.4 总结一下:
在 Python 中,迭代器、生成器和可迭代对象是集合数据访问的三个基本概念。迭代器提供了一种通用的遍历集合数据的方法,而生成器提供了一种生成迭代数据的简洁方式,可迭代对象则定义了可以生成迭代器的对象。它们的共同目的是为了在保持代码简洁的同时,有效地处理数据集合,尤其是在数据量非常大或者是无限的情况下。 理解并掌握这些概念对于编写高效和可读性高的 Python 代码非常重要。每个概念都在数据处理和控制流的抽象中扮演着关键角色,并广泛应用于数据分析领域、系统操作领域和网络编程等领域。
2.0 装饰器(Decorator):
装饰器是Python中的一种高级编程特性,**它允许你在不修改原始函数代码的情况下,动态地增强或修改函数的行为。**装饰器通常用于代码重用、添加功能、修改函数的输入/输出等方面,它是Python函数式编程的一部分,非常强大和灵活。
-
函数装饰器:
- 装饰器本质上是一个Python函数,它接受一个函数作为参数,并返回一个新的函数。
- 装饰器函数通常在函数定义之前使用
@符号来装饰目标函数。 - 装饰器的主要作用是在不修改原函数代码的情况下,为函数添加额外的功能或修改其行为。
-
装饰器示例:
下面是一个简单的装饰器示例,它用于测量函数的执行时间:import time def timing_decorator(func): def wrapper(*args, **kwargs): start_time = time.time() result = func(*args, **kwargs) end_time = time.time() print(f"{func.__name__} took {end_time - start_time} seconds to execute.") return result return wrapper @timing_decorator def my_function(): # Some time-consuming task time.sleep(2) my_function()在这个示例中,
timing_decorator装饰器测量了my_function函数的执行时间,而不需要修改my_function的源代码。 -
多个装饰器:
你可以为一个函数应用多个装饰器,它们按照从上到下的顺序执行。这允许你将不同的功能组合在一起,以增强函数的行为。@decorator1 @decorator2 def my_function(): # ... # 等效于 my_function = decorator1(decorator2(my_function)) -
内置装饰器:
Python提供了一些内置装饰器,如@staticmethod和@classmethod,用于定义静态方法和类方法。这些装饰器可以用于类中的方法,以提供不同类型的方法调用。class MyClass: def __init__(self, value): self.value = value @staticmethod def static_method(): print("This is a static method") @classmethod def class_method(cls): print("This is a class method") obj = MyClass(42) obj.static_method() obj.class_method() -
自定义装饰器:
你可以自己编写装饰器函数,以满足特定需求。通常,自定义装饰器需要接受函数作为参数,并返回一个包装函数。装饰器函数可以在包装函数的前后执行自定义逻辑。
装饰器是Python中强大而灵活的工具,它们用于增强函数的功能、提供代码重用和简化代码结构。常见的装饰器包括日志记录、性能分析、权限验证、缓存等。理解和熟练使用装饰器是成为高级Python开发人员的关键一步。