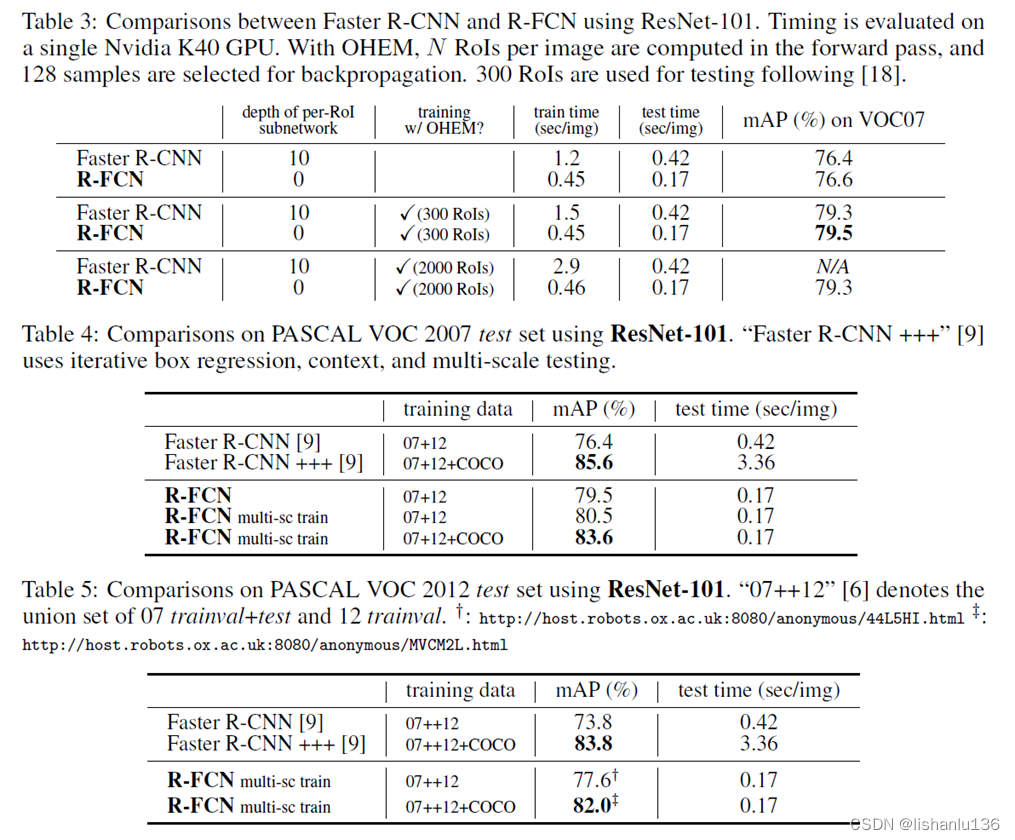
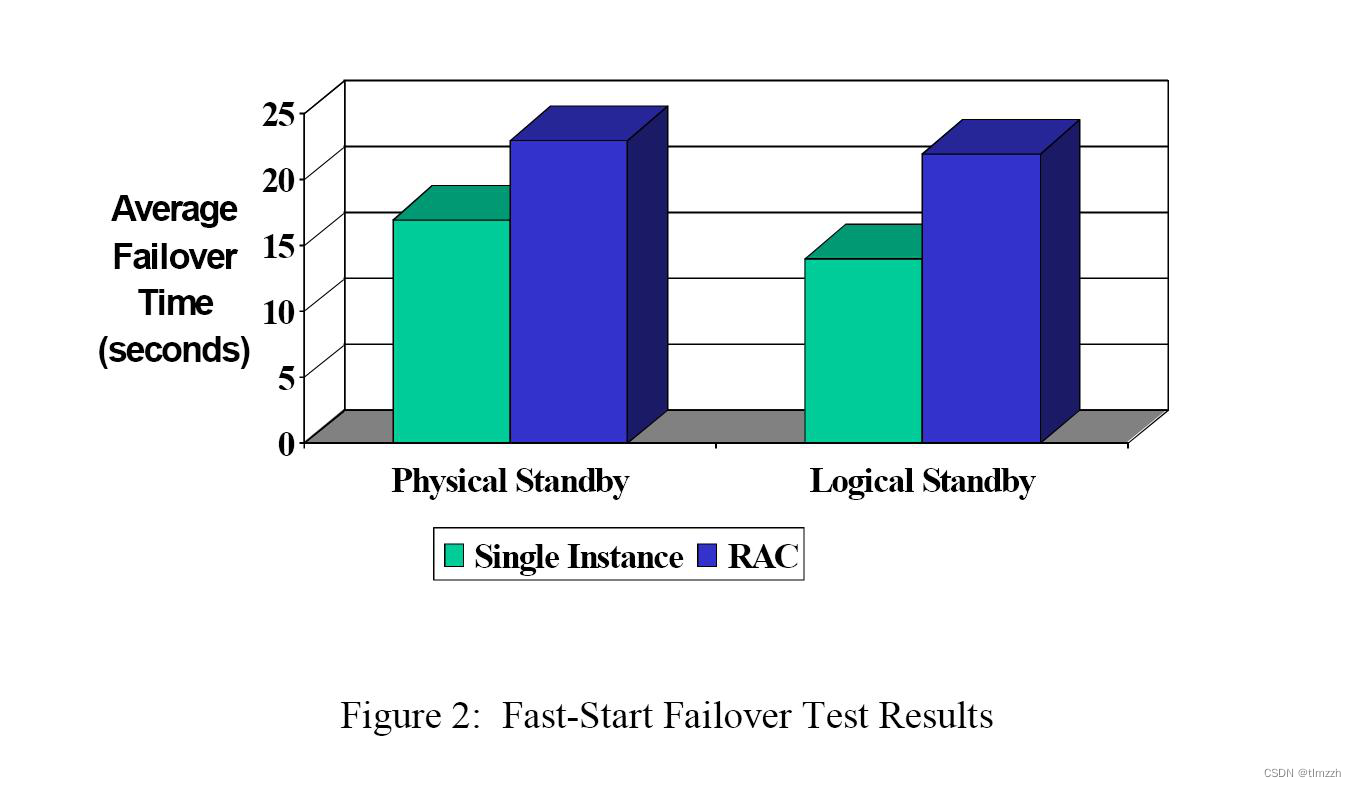
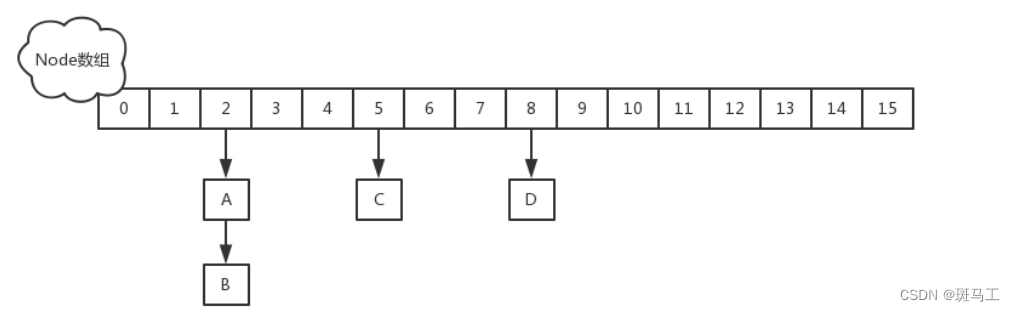
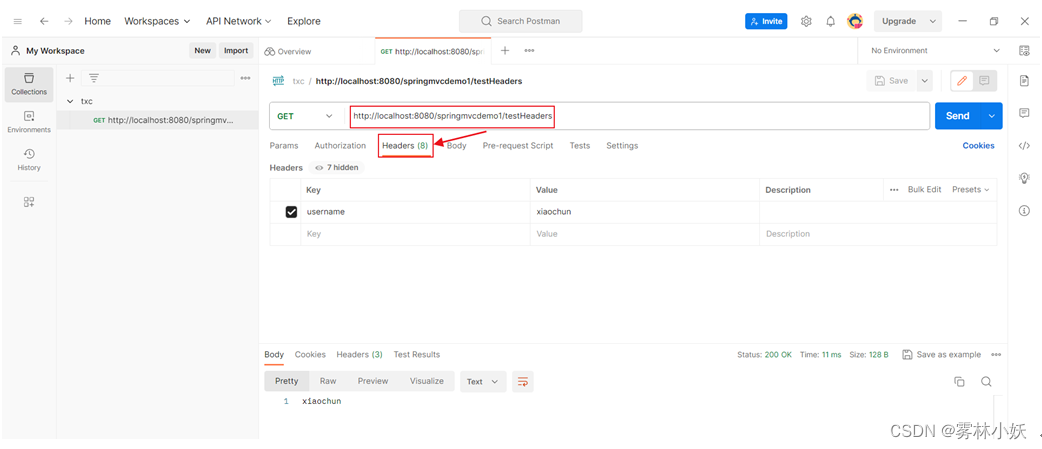
1 import库(略)
import os
import random
import time
from dataclasses import dataclass
import gymnasium as gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import tyro
from torch.distributions.normal import Normal
from torch.utils.tensorboard import SummaryWriter
2 Args类(略)
定义了所有有关模型的参数,参数含义见英文注释。
@dataclass
class Args:
exp_name: str = os.path.basename(__file__)[: -len(".py")]
"""the name of this experiment"""
seed: int = 1
"""seed of the experiment"""
torch_deterministic: bool = True
"""if toggled, `torch.backends.cudnn.deterministic=False`"""
cuda: bool = True
"""if toggled, cuda will be enabled by default"""
track: bool = False
"""if toggled, this experiment will be tracked with Weights and Biases"""
wandb_project_name: str = "cleanRL"
"""the wandb's project name"""
wandb_entity: str = None
"""the entity (team) of wandb's project"""
capture_video: bool = False
"""whether to capture videos of the agent performances (check out `videos` folder)"""
save_model: bool = False
"""whether to save model into the `runs/{run_name}` folder"""
upload_model: bool = False
"""whether to upload the saved model to huggingface"""
hf_entity: str = ""
"""the user or org name of the model repository from the Hugging Face Hub"""
# Algorithm specific arguments
env_id: str = "HalfCheetah-v4"
"""the id of the environment"""
total_timesteps: int = 1000000
"""total timesteps of the experiments"""
learning_rate: float = 3e-4
"""the learning rate of the optimizer"""
num_envs: int = 1
"""the number of parallel game environments"""
num_steps: int = 2048
"""the number of steps to run in each environment per policy rollout"""
anneal_lr: bool = True
"""Toggle learning rate annealing for policy and value networks"""
gamma: float = 0.99
"""the discount factor gamma"""
gae_lambda: float = 0.95
"""the lambda for the general advantage estimation"""
num_minibatches: int = 32
"""the number of mini-batches"""
update_epochs: int = 10
"""the K epochs to update the policy"""
norm_adv: bool = True
"""Toggles advantages normalization"""
clip_coef: float = 0.2
"""the surrogate clipping coefficient"""
clip_vloss: bool = True
"""Toggles whether or not to use a clipped loss for the value function, as per the paper."""
ent_coef: float = 0.0
"""coefficient of the entropy"""
vf_coef: float = 0.5
"""coefficient of the value function"""
max_grad_norm: float = 0.5
"""the maximum norm for the gradient clipping"""
target_kl: float = None
"""the target KL divergence threshold"""
# to be filled in runtime
batch_size: int = 0
"""the batch size (computed in runtime)"""
minibatch_size: int = 0
"""the mini-batch size (computed in runtime)"""
num_iterations: int = 0
"""the number of iterations (computed in runtime)"""
3 定义Agent
使用gym.wrappers对原始gym环境进行修改:
FlattenObservation:将obs矩阵展平为1维向量RecordEpisodeStatistics:记录episode的统计数据ClipAction:剪裁action以满足action_space的要求NormalizeObservation:对obs矩阵进行归一化TransformObservation:对obs矩阵进行变换NormalizeReward:对reward进行归一化TransformReward:对reward进行变换
def make_env(env_id, idx, capture_video, run_name, gamma):
def thunk():
if capture_video and idx == 0:
env = gym.make(env_id, render_mode="rgb_array")
env = gym.wrappers.RecordVideo(env, f"videos/{run_name}")
else:
env = gym.make(env_id)
env = gym.wrappers.FlattenObservation(env) # deal with dm_control's Dict observation space
env = gym.wrappers.RecordEpisodeStatistics(env)
env = gym.wrappers.ClipAction(env)
env = gym.wrappers.NormalizeObservation(env)
env = gym.wrappers.TransformObservation(env, lambda obs: np.clip(obs, -10, 10))
env = gym.wrappers.NormalizeReward(env, gamma=gamma)
env = gym.wrappers.TransformReward(env, lambda reward: np.clip(reward, -10, 10))
return env
return thunk
初始化神经网络中的每层的参数。
def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
torch.nn.init.orthogonal_(layer.weight, std)
torch.nn.init.constant_(layer.bias, bias_const)
return layer
PPO(连续动作)的Agent类,Actor-Critic结构,其中Actor网络和Critic网络均基于MLP构建,激活函数使用Tanh。
Critic网络的输入尺寸为(batch_size, obs_dim, 64),输出尺寸为(batch_size, 1),作用是形成obs到value的映射。向外暴露get_value函数以计算状态价值。
Actor网络包含两部分:
self.action_mean将obs映射到动作均值,输入尺寸为(batch_size, obs_dim, 64),输出尺寸为(batch_size, action_dim)self.actor_logstd是一个(1, action_dim)大小的Parameter,用于形成动作方差的对数(后面需要对其使用torch.exp保证其为正数)
在cleanrl的实现里,Actor网络使用对角高斯分布来生成连续动作的分布,即根据Normal(action_mean, actor_std)对动作进行抽样。
get_action_and_value函数中计算了:
- 动作分布
probs - 动作采样
probs.sample() - 对数似然
probs.log_prob(action).sum(1) - 熵
probs.entropy().sum(1) - 状态价值
self.critic(x)
在对数似然和熵的计算中,sum(1)用于计算多个相互独立动作的联合概率。
class Agent(nn.Module):
def __init__(self, envs):
super().__init__()
self.critic = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 1), std=1.0),
)
self.actor_mean = nn.Sequential(
layer_init(nn.Linear(np.array(envs.single_observation_space.shape).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, np.prod(envs.single_action_space.shape)), std=0.01),
)
self.actor_logstd = nn.Parameter(torch.zeros(1, np.prod(envs.single_action_space.shape)))
def get_value(self, x):
return self.critic(x)
def get_action_and_value(self, x, action=None):
action_mean = self.actor_mean(x)
action_logstd = self.actor_logstd.expand_as(action_mean)
action_std = torch.exp(action_logstd)
probs = Normal(action_mean, action_std)
if action is None:
action = probs.sample()
return action, probs.log_prob(action).sum(1), probs.entropy().sum(1), self.critic(x)
4 训练Agent
设置一些参数,稍微解释一下几个参数的含义:
batch_size:num_envs与num_steps的乘积,表示跑一次迭代能收集到多少样本minibatch_size:每次训练都从大的batch中抽取小的minibatch进行训练num_iterations:整个训练过程跑几轮迭代
args = tyro.cli(Args)
args.batch_size = int(args.num_envs * args.num_steps)
args.minibatch_size = int(args.batch_size // args.num_minibatches)
args.num_iterations = args.total_timesteps // args.batch_size
run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
if args.track:
import wandb
wandb.init(
project=args.wandb_project_name,
entity=args.wandb_entity,
sync_tensorboard=True,
config=vars(args),
name=run_name,
monitor_gym=True,
save_code=True,
)
writer = SummaryWriter(f"runs/{run_name}")
writer.add_text(
"hyperparameters",
"|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
)
# TRY NOT TO MODIFY: seeding
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.backends.cudnn.deterministic = args.torch_deterministic
device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
实例化envs、agent以及optim。
# env setup
envs = gym.vector.SyncVectorEnv(
[make_env(args.env_id, i, args.capture_video, run_name, args.gamma) for i in range(args.num_envs)]
)
assert isinstance(envs.single_action_space, gym.spaces.Box), "only continuous action space is supported"
agent = Agent(envs).to(device)
optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
定义需要收集的信息:
obs:观测到的环境状态actions:动作采样值logprobs:动作采样的对数似然rewards:即时奖励dones:episode是否结束values:状态价值
# ALGO Logic: Storage setup
obs = torch.zeros((args.num_steps, args.num_envs) + envs.single_observation_space.shape).to(device)
actions = torch.zeros((args.num_steps, args.num_envs) + envs.single_action_space.shape).to(device)
logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device)
rewards = torch.zeros((args.num_steps, args.num_envs)).to(device)
dones = torch.zeros((args.num_steps, args.num_envs)).to(device)
values = torch.zeros((args.num_steps, args.num_envs)).to(device)
next_obs存储每步的观测结果,next_done存储每步是否导致episode结束。这两个变量用于计算由最后一个动作导致的下一个状态的价值。
# TRY NOT TO MODIFY: start the game
global_step = 0
start_time = time.time()
next_obs, _ = envs.reset(seed=args.seed)
next_obs = torch.Tensor(next_obs).to(device)
next_done = torch.zeros(args.num_envs).to(device)
在step的for循环里,Actor网络和Critic网络基于当前策略(旧策略)收集样本。因为旧策略不作为参数参与到梯度下降过程,因此需要torch.no_grad()包围相关数值的计算过程。
for iteration in range(1, args.num_iterations + 1):
# Annealing the rate if instructed to do so.
if args.anneal_lr:
frac = 1.0 - (iteration - 1.0) / args.num_iterations
lrnow = frac * args.learning_rate
optimizer.param_groups[0]["lr"] = lrnow
for step in range(0, args.num_steps):
global_step += args.num_envs
obs[step] = next_obs
dones[step] = next_done
# ALGO LOGIC: action logic
with torch.no_grad():
action, logprob, _, value = agent.get_action_and_value(next_obs)
values[step] = value.flatten()
actions[step] = action
logprobs[step] = logprob
# TRY NOT TO MODIFY: execute the game and log data.
next_obs, reward, terminations, truncations, infos = envs.step(action.cpu().numpy())
next_done = np.logical_or(terminations, truncations)
rewards[step] = torch.tensor(reward).to(device).view(-1)
next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(next_done).to(device)
if "final_info" in infos:
for info in infos["final_info"]:
if info and "episode" in info:
print(f"global_step={global_step}, episodic_return={info['episode']['r']}")
writer.add_scalar("charts/episodic_return", info["episode"]["r"], global_step)
writer.add_scalar("charts/episodic_length", info["episode"]["l"], global_step)
这部分基于value、reward计算GAE(广义优势估计)。从最后一个reward开始,通过迭代计算:
- δ t = r t + γ ∗ V ( s t + 1 ) − V ( s t ) \delta_t = r_t+\gamma * V(s_{t+1})-V(s_t) δt=rt+γ∗V(st+1)−V(st)
- a t = δ t + γ ∗ λ ∗ a t + 1 a_t = \delta_t + \gamma * \lambda * a_{t+1} at=δt+γ∗λ∗at+1
###############################################
for iteration in range(1, args.num_iterations + 1):
【在iteration的for循环中拼接上一段代码】
###############################################
# bootstrap value if not done
with torch.no_grad():
next_value = agent.get_value(next_obs).reshape(1, -1)
advantages = torch.zeros_like(rewards).to(device)
lastgaelam = 0
for t in reversed(range(args.num_steps)):
if t == args.num_steps - 1:
nextnonterminal = 1.0 - next_done
nextvalues = next_value
else:
nextnonterminal = 1.0 - dones[t + 1]
nextvalues = values[t + 1]
delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
returns = advantages + values
原先的矩阵都是(num_envs, num_steps, XX_dim)的形状,现在转换成(batch_size, XX_dim)的形状,后面要基于batch划分minibatch进行训练。
###############################################
for iteration in range(1, args.num_iterations + 1):
【在iteration的for循环中拼接上一段代码】
###############################################
# flatten the batch
b_obs = obs.reshape((-1,) + envs.single_observation_space.shape)
b_logprobs = logprobs.reshape(-1)
b_actions = actions.reshape((-1,) + envs.single_action_space.shape)
b_advantages = advantages.reshape(-1)
b_returns = returns.reshape(-1)
b_values = values.reshape(-1)
# Optimizing the policy and value network
b_inds = np.arange(args.batch_size)
clipfracs = []
minibatch的划分是基于b_inds进行的,所以先使用shuffle进行打乱,然后在start的for循环里每次抽取minibatch,计算新的newlogprob、entropy、newvalue。根据新的和旧的logprob计算ratio,用于后面的PPO截断。
###############################################
for iteration in range(1, args.num_iterations + 1):
......
###############################################
for epoch in range(args.update_epochs):
np.random.shuffle(b_inds)
for start in range(0, args.batch_size, args.minibatch_size):
end = start + args.minibatch_size
mb_inds = b_inds[start:end]
_, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions[mb_inds])
logratio = newlogprob - b_logprobs[mb_inds]
ratio = logratio.exp()
首先采用kl-approx使用蒙特卡洛近似KL散度approx_kl,然后获取minibatch的advantage,按需归一化。最后进行PPO截断,计算policy loss。
###############################################
for iteration in range(1, args.num_iterations + 1):
......
for epoch in range(args.update_epochs):
......
for start in range(0, args.batch_size, args.minibatch_size):
【在start的for循环中拼接上一段代码】
###############################################
with torch.no_grad():
# calculate approx_kl http://joschu.net/blog/kl-approx.html
old_approx_kl = (-logratio).mean()
approx_kl = ((ratio - 1) - logratio).mean()
clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
mb_advantages = b_advantages[mb_inds]
if args.norm_adv:
mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
# Policy loss
pg_loss1 = -mb_advantages * ratio
pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
pg_loss = torch.max(pg_loss1, pg_loss2).mean()
根据旧的b_returns和新的newvalue计算value loss。当然这里也提供了value loss clip。
###############################################
for iteration in range(1, args.num_iterations + 1):
......
for epoch in range(args.update_epochs):
......
for start in range(0, args.batch_size, args.minibatch_size):
【在start的for循环中拼接上一段代码】
###############################################
# Value loss
newvalue = newvalue.view(-1)
if args.clip_vloss:
v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
v_clipped = b_values[mb_inds] + torch.clamp(
newvalue - b_values[mb_inds],
-args.clip_coef,
args.clip_coef,
)
v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
v_loss = 0.5 * v_loss_max.mean()
else:
v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
根据policy loss、value loss和entropy加权求和得到总的loss,然后反向传播优化参数。在之前计算了新旧策略之间的KL散度,这里可以利用KL散度实现early stopping,即KL散度大于阈值则停止当前batch的训练。(当然也可以停止掉当前minibatch的训练)
###############################################
for iteration in range(1, args.num_iterations + 1):
......
for epoch in range(args.update_epochs):
......
for start in range(0, args.batch_size, args.minibatch_size):
【在start的for循环中拼接上一段代码】
###############################################
entropy_loss = entropy.mean()
loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
optimizer.step()
if args.target_kl is not None and approx_kl > args.target_kl:
break
tensorboard记录数据,没什么好说的。
###############################################
for iteration in range(1, args.num_iterations + 1):
【在iteration的for循环中拼接上一段代码】
###############################################
y_pred, y_true = b_values.cpu().numpy(), b_returns.cpu().numpy()
var_y = np.var(y_true)
explained_var = np.nan if var_y == 0 else 1 - np.var(y_true - y_pred) / var_y
# TRY NOT TO MODIFY: record rewards for plotting purposes
writer.add_scalar("charts/learning_rate", optimizer.param_groups[0]["lr"], global_step)
writer.add_scalar("losses/value_loss", v_loss.item(), global_step)
writer.add_scalar("losses/policy_loss", pg_loss.item(), global_step)
writer.add_scalar("losses/entropy", entropy_loss.item(), global_step)
writer.add_scalar("losses/old_approx_kl", old_approx_kl.item(), global_step)
writer.add_scalar("losses/approx_kl", approx_kl.item(), global_step)
writer.add_scalar("losses/clipfrac", np.mean(clipfracs), global_step)
writer.add_scalar("losses/explained_variance", explained_var, global_step)
print("SPS:", int(global_step / (time.time() - start_time)))
writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
模型保存的一些操作,也没什么好说的。
if args.save_model:
model_path = f"runs/{run_name}/{args.exp_name}.cleanrl_model"
torch.save(agent.state_dict(), model_path)
print(f"model saved to {model_path}")
from cleanrl_utils.evals.ppo_eval import evaluate
episodic_returns = evaluate(
model_path,
make_env,
args.env_id,
eval_episodes=10,
run_name=f"{run_name}-eval",
Model=Agent,
device=device,
gamma=args.gamma,
)
for idx, episodic_return in enumerate(episodic_returns):
writer.add_scalar("eval/episodic_return", episodic_return, idx)
if args.upload_model:
from cleanrl_utils.huggingface import push_to_hub
repo_name = f"{args.env_id}-{args.exp_name}-seed{args.seed}"
repo_id = f"{args.hf_entity}/{repo_name}" if args.hf_entity else repo_name
push_to_hub(args, episodic_returns, repo_id, "PPO", f"runs/{run_name}", f"videos/{run_name}-eval")
envs.close()
writer.close()


![[原创]如何正确的部署R语言开发环境(含动图演示).](https://img-blog.csdnimg.cn/direct/ffd956da32084583998653aa57f0f110.png)