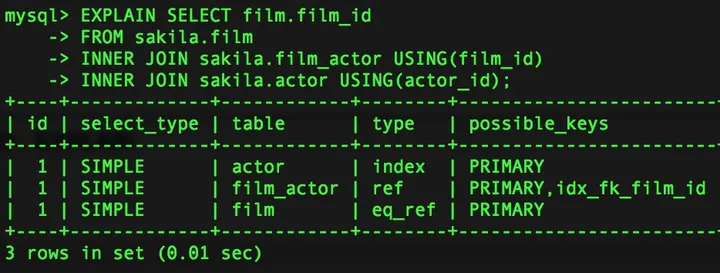
Did the Models Understand Documents? Benchmarking Models for Language Understanding in Document-Level Relation Extraction
School of Computer Science, Fudan University | ACL 2023.06 | 原文链接
Background
过去的工作大多数都是从单个句子中收获更多的关系,然而如今要采用多个句子作为一个整体来获得更多的关系,即文档级关系抽取(DocRE),因为需要综合文档中的所有信息,所以文档级关系抽取是更有挑战性的。
过去存在的问题

一种常见的评估方法是测量整个测试集的平均误差,这忽略了模型可以根据错误的特征做出正确预测的情况。如上图,Vera Cáslavská和Czech之间的关系,机器所考虑的决策方式与人类的完全不同,
文章工作内容简述
- 在DocRED上进一步注释成了$ DocRED _ { HWE } $
- 采用特征归因法观察模型在推理过程中考虑的最关键的词,发现模型总是将不相关的词语
虚假的关联起来,形成了无法解释的决策 - 证明了模型中的决策方式是不可靠的,设计了6种RE攻击方式证明
- 引入平均精度(MAP)指标评价模型的理解能力和推理能力,由此区分
因伪相关性引起的能提升和因理解能力引起的性能提升,最终发现MAP越高,模型的鲁棒性和泛化能力越强
- DocRED: 大型文档级关系抽取数据集
- $ DocRED _ { HWE } $: HWE表示人类注释的词级证据,human-annotated word-level evidence
过去的文档级关系识别
主要分为图的方法和基于变换器的方法
-
基于图的:基于图的方法利用上下文的结构信息构造各种图,并通过图中的路径对推理过程的多次反射进行建。
DocuNet(SOTA)中构建了一个实体级的关系图,然后利用图上的U形网络来捕获全局相互依赖性 -
基于Transformerbased方法的:执行推理隐式识别的长距离令牌依赖通过transformers。
ATLOP通过相关上下文增强了实体对的嵌入,并为多标签分类引入了一个可学习的阈值。
工作内容1 : DocRED_HWE
难点:第一个挑战来自原始数据集中的注释工件,第二个挑战在于单个关系的多个推理路径
解决方式:采用细粒度的单词级的证据,并且提出了一个新的检查规则,用于二次推理,只有被验证两次才会被采用
- 来自原始数据集中的注释工件:注释器可以使用先验知识通过实体名称来标记关系,而不需要观察上下文。例如,给定一个跨句实体对“Obama”和“the US”的文档,尽管缺乏理论依据注释者还是倾向于标注“president of”。
可以通过注释细粒度的单词级证据来自然地解决- 需要注释器对所有推理路径中的单词进行注释。当注释者通过相应的证据词成功推理出某种关系时,其他推理路径中的证据词往往会被忽略。
为了解决这一问题,对每个文档采用了多个(滚动)标注,并提出了检查规则:给定一个文档,之前标注的关系被屏蔽,标注者将无法对关系进行推理。如果违反规则,新的证据词将被标注。更新将由下一个注释器检查,直到没有更新发生。所有注释的证据词至少被验证两次。
并且作者最后对于结果进行了一定的人工筛选
工作内容2 : 发现模型总是将不相关的词语虚假的关联起来,形成了无法解释的决策
建立模型参数
- 文档$ d $
- 实体集 $ \varepsilon = { e_i } ^n _ { i = 1 } $
- 提取的目标为预测实体对中$ (e_i , e_j)_ { i, j=1…n;i!=j } $
- 范围是在 R ∪ { N A } R \cup \{ NA \} R∪{NA}中,
-
- 其中 R R R表示为预测的关系集
-
- N A NA NA为没有关系的实体对。
- 使用 { m j i } j = 1 N i \{ m _ j ^ i \} _ { j = 1 } ^ { N _ i } {mji}j=1Ni区分每个实体,
- 最终抽取的三元组的格式为 $ { (e_i, r _ ij, e _ j ) | e_i, e_j \in \varepsilon, r_ij \in R } $
验证方式
选择基于图的DocuNet,基于Transformer的ATLOP,通过综合梯度(IG)作为归因方法(因为具有简单且可信的特性)。
使用积分梯度法,计算模型在输入上的输出和参考点上的输出,它俩之间的差值作为token的score进行分配。即如下图所示,给定一个输入 x x x,和参考点$ x’ , I G 计算从 ,IG计算从 ,IG计算从 x’ $ 到 $ x 的第 i 维的梯度 的第i维的梯度 的第i维的梯度 g _ i 线性积分。其中 线性积分。其中 线性积分。其中 \frac { \partial F(x) } { \partial x_i } 表示输出 表示输出 表示输出 F(x) $到 $ x 的梯度。将 的梯度。将 的梯度。将 x’ $设置所有值为0的Embbeding vectors

数据集有:
- D o c R E D DocRED DocRED、 D o c R E D S c r a t c h DocRED _ { Scratch } DocREDScratch,其中 D o c R E D DocRED DocRED有56354个关系,96种关系类型,大多只能通过推理识别。$DocRED_ { Scratch } 很大程度偏离了 很大程度偏离了 很大程度偏离了DocRED$的训练集,可以用于测试模型的泛化能力
- D o c R E D H W E DocRED_{HWE} DocREDHWE人工注释了1521不同实体的代词,用于忽略。
实验与分析
位置误导
使用IG来描述模型的决策规则。
A
T
L
O
P
R
o
B
E
R
T
a
ATLOP _ RoBERTa
ATLOPRoBERTa在DocRED验证集中不同位置的上平均分布,归因DocuNet也会出现类似的曲线。
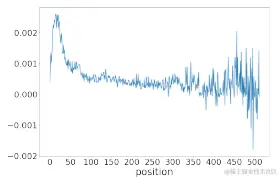
如上图所示,特定位置的token信息比其他位置的words信息的affect更明显。
也就是说,模型根据单词在文档中的位置来区分单词,原因应该为:
- 在学习过程中扭曲了位置特征,将其与预测结果虚假地关联了起来
- 位置Embbeding被错误的训练(没监督),偏离了表示位置信息的原始功能
由此说明,泛化能力弱
狭隘的推理
用推理正确关系所需要的单词,代表模型的推理范围。

设模型为"A X B",A、B为实体,X为推理关系所需要的单词/单词序列,设X为$r_AB$的前k个赋值token,token的顺序与原文相同,DocRED性能如上图所示。
- 添加最高属性(我理解为强属性)的单词会导致性能下降
- position的权重比较大
- 当只给出实体名称不给上下文,性能可以达到原模型的85%(53%的f1分数)
由此推出,模型在一个比较狭隘的范围内推理
虚假相关

选择前5个具有属性的单词来显示模型的证据单词。可以发现,很大程度上依赖了一些非因果标记(如实体名称和标点符号),这不利于深度学习。比如逗号就起到了很大作用(SEP和CLS可以证明为无操作的操作符)。因此,该模型不能被部署到现实场景中,因为非因果令牌很容易被替换掉。
原因分析

- U是因果关系确定的证据词
- Y是预测词
- X是文档
- 给定X和A,模型学习H和Y之间的伪相关。
基于transformer的预训练语言模型,都希望在给定上下文X的情况下,提高当前单词的概率Y,上下文应该由P(Y|X)表示,但学习的是P(Y|X, A),其中A表示为对采样过程的访问,从而导致有偏差。如上图的有向无环图所示。
其中H为有语法意义的(如the,逗号),U为相对不太可能访问采样过程或上下文。目前,Y的语义很大程度依赖着有明确语义的词,即U->Y,他们的组合形成了自然的语言表达,其过程可以使用A->X表述,其中A决定了单词在上下文的分布。
目前来说,PLM训练后的模型,倾向于将虚假的信息与关系关联起来。
工作内容3 : 针对SOTA模型的攻击
证明:
- 模型的决策规则与人类的不同
- 这种差异会严重损害鲁棒性和泛化能力
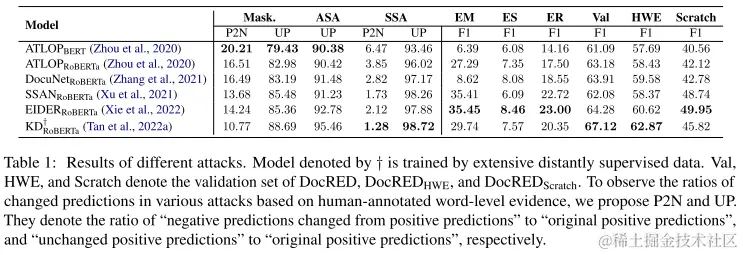
由十字架标注的为有监督的训练。
- P2N:
消极预测从积极预测变为原始积极预测 - UP:
不变的积极预测变为原始积极预测的比例
Word-level Evidence Attacks
- 蒙面词级攻击,所有被人标注的Word-level Evidence(HWE)都被直接Masked(Mask)
- 反义词替换,HWE中一个词被一个反义词替换(ASA)
- 同义词替换,HWE中一个词被一个同义词替换(SSA)
结果如上图所示,在Mask攻击下,模型仍预测相同的关系【但是性能下降了79%】,在ASA攻击下性能下降了90%,和SSA性能与ASA大致相同。可证明鲁棒性很差。
Entite Name Attacks
- 屏蔽实体攻击(EM),直接屏蔽实体名称
- 随机打乱实体攻击(ER),随机置换每个文档中的实体名称
- 非分发(OOD)实体替换攻击(ES),使用训练数据中没有的实体名称来替换
结果如上图,ES下降最严重,从67.12->7.57
工作内容4 : 新的评价指标MAP
在上述中,证明了模型应该学习人类的决策规则。由此提出一个新的评价指标MAP:
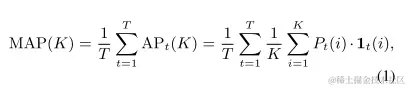
- 1t(i)表示预测第t个相关事实的第i个重要字的指示函数
- K的选择,类似于推荐系统中的评价指标,取决于RE从业者的需求,通常设置为1、10、50和100。
如果单词在人类标注的单词级证据中,则1t(i)的输出值等于1。否则等于0
个人思考
对于以往的深度学习中,大多都是黑盒训练,每次看别人的论文也是,往往都不知道为什么就起作用了,故都是认为就把上下文的关系或者别的之类的token联系在一起用了而已,就像世界十大难题中的中文房间问题一样,就算给出正确的结果,不知道里面的人到底会不会中文。对于这篇文章,完全揭示了当前文档级关系抽取(甚至句子级关系抽取)的现状,知识把杂七杂八的东西放到了池子中去学习,让模型只能在学习到的数据集中有比较好的效果。对于以后的实验中,针对于这一部分,可以优化。