2020End-to-end Neural Coreference Resolution论文笔记
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Task
- 4 Model
- 4.1 Scoring Architecture
- 4.2 Span Representations
- 5 Inference
- 6 Learning
- 7 Experiments
- 7.1 Hyperparameters
- Word representations
- Hidden dimensions
- Feature encoding
- Pruning
- Learning
- 7.2 Ensembling
- 8 Results
- 8.1 Coreference Results
- 8.2 Ablations
- Features
- Word representations
- Metadata
- Head-finding attention
- 8.3 Comparing Span Pruning Strategies
- 9 Analysis
- 9.1 Mention Recall
- 9.2 Mention Precision
- 9.3 Head Agreement
- 9.4 Qualitative Analysis
- Strengths
- Weaknesses
- 10 Conclusion
Abstract
我们介绍了第一个端到端共指消解模型,并表明它在不使用句法解析器或手工设计的提及检测器的情况下显著优于以前的所有工作。
关键思想是直接将文档中的所有跨域视为潜在的提及,并了解每个跨域可能的前件的分布。
该模型计算将上下文相关的边界表示与首部寻找注意力机制相结合的跨度嵌入。
它被训练为最大限度地从共指簇中获得Gold先行词跨度的边际可能性,并被分解为能够积极地剪枝潜在提及。
实验证明了最先进的性能,在Ontonotes基准上的增益为1.5F1,在使用5模型集成时的增益为3.1F1,尽管这是第一个在没有外部资源的情况下成功训练的方法。
1 Introduction
我们提出了第一个最先进的神经共指消解模型,它是端到端学习的,只给出金提及簇。
所有最近的共指模型,包括取得了令人印象深刻的性能提升的神经方法(Wiseman et al.,2016;Clark and Manning,2016b,a),都依赖于句法解析器,既用于标题词特征,也用于精心手工设计的提及建议算法的输入。
我们首次证明了这些资源是不需要的,事实上,通过训练一个端到端的神经模型来联合学习聚类它们,在没有这些资源的情况下性能可以显著提高。
我们的模型推理所有跨度的空间达到最大长度,并直接优化金共参照群的先验跨度的边际似然。
它包括一个跨度排名模型,该模型决定对于每个跨度,前面的哪个跨度(如果有的话)是一个好的前一个跨度。
我们的模型的核心是表示文档中文本范围的矢量嵌入,它将上下文相关的边界表示与跨范围的头部发现注意机制结合在一起。
注意力组件的灵感来自于以前系统中解析器派生的首字匹配特性(Durrett和Klein, 2013),但不太容易受到级联错误的影响。
在我们的分析中,我们显示经验,这些学习的注意力权重与传统的头性定义强烈相关
在我们的端到端模型中为所有跨度对打分是不切实际的,因为文档长度的复杂性将是四次方。
因此,我们将该模型纳入一元提及分数和两两前因式分数,这两者都是学习广度嵌入的简单函数。
一元提及分数被用来修剪跨度和前因式的空间,以积极地减少成对计算的数量。
在OntoNotes基准测试中,我们的最终方法比现有模型的性能好1.5个F1,使用5个模型集合时的性能好3.1个F1。
它不仅准确,而且相对容易解释。
例如,模型因素直接表明一个缺失的共同引用链接是由于低提及分数(无论是跨度)还是来自提及排名组件的低分数。
头发现注意机制也揭示了哪些提及的内部词汇对共同参照决策的贡献最大。
我们利用这种全面的可解释性来做详细的定量和定性分析,提供对该方法的优势和弱点的洞察。
2 Related Work
机器学习方法在共指消解方面有很长的历史(详细的调查见Ng(2010))。
然而,学习问题是具有挑战性的,直到最近,手工设计的系统建立在自动生成的解析树之上(Raghunathan等人,2010)优于所有的学习方法。
Durrett和Klein(2013)表明,高度词汇学习方法扭转了这一趋势,以及最近的神经模型(Wiseman等人,2016;Clark和Manning, 2016b,a)取得了显著的成绩。
然而,所有这些模型都使用了头部特征的解析器,并包括高度设计的提及建议算法这样的流水线系统有两个主要缺点:
(1)解析错误会引入级联错误
(2)许多手工设计的规则不能推广到新的语言中。
Daum´e III和Marcu(2005)首先提出了一个联合模型提及检测和共指消解的非管道系统。
他们引入了一个基于搜索的系统,该系统可以预测一个从左到右的转换系统中的共同引用结构,该系统可以包含全局特征。
相比之下,我们的方法在做出更强的独立性假设、实现直接推理时表现得很好。
更一般地说,已经提出了各种各样的学习共同参考模型的方法。
它们通常可以被归类为
(1)提及配对分类器(Ng和Cardie, 2002;
(2)实体层次模型(Haghighi和Klein, 2010;Clark and Manning, 2015, 2016b;Wiseman等人,2016),
(3)潜在树模型(Fernandes等人,2012;Bj¨orkelund and Kuhn, 2014;
或者(4)提及排名模型(Durrett and Klein, 2013;Wiseman等人,2015年;Clark and Manning, 2016a)。
我们的跨级排序方法与提及排序最相似,但我们通过联合检测提及和预测共引用来推理更大的空间。
3 Task

端到端共指消解模型的第一步,它计算跨度的嵌入表示,以对潜在的实体提及进行评分。
对得分较低的跨度进行修剪,以便只有可管理数量的跨度被考虑用于共指决策。
一般说来,该模型考虑了所有可能的跨度,直到最大宽度,但我们在这里只描述了一个很小的子集。
我们将端到端共指消解的任务制定为文档中每一个可能跨度的决策集。
输入是包含T个单词以及元数据(例如说话人和体裁信息)的文档D。
设N = T(T+1)/2是D中可能存在的文本spans的个数。
对于1≤i≤N,分别用start (i)和end (i)表示D中一个张域i的起始索引和结束索引。具有相同起始索引的span按END(i)排序。
任务是给每个跨度i分配一个先行
y
i
y_i
yi。每个
y
i
y_i
yi的可能赋值集合是
Y
i
=
{
ϵ
,
1
,
…
,
i
−
1
}
\mathcal{Y}_i = \{\epsilon, 1,…, i−1\}
Yi={ϵ,1,…,i−1},一个伪先行项
ϵ
\epsilon
ϵ和所有前面的跨度。
跨度i的真前因,即1≤j≤i−1的跨度j,表示i和j之间的相互参照联系。dummy antecedent
ϵ
\epsilon
ϵ表示两种可能的情形:
(1)跨度不是一个提及的实体,或
(2)跨度是一个提及的实体,但它与之前的任何跨度都不相关。
这些决策隐式地定义了最终的集群,可以通过对由一组先行预测连接的所有跨度进行分组来恢复集群。
4 Model
我们的目标是学习一个条件概率分布P(y1,…, yN | D),其最有可能的配置产生正确的集群。
我们对每个跨度使用多项式的乘积:
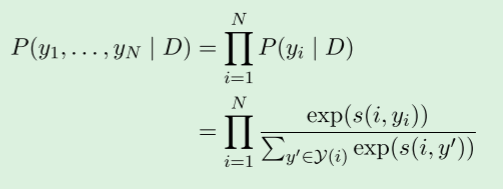
其中s(i, j)是文档D中span i和span j之间的相互引用链接的两两得分。
当上下文是明确的时,我们将文档D从符号中省略。
这个两两共参照得分有三个因素:(1)是否提及span i,(2)是否提及span j, (3) j是否为i的前因antecedent:
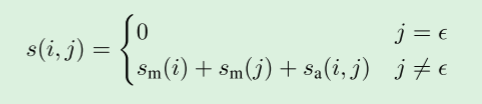
这里
s
m
(
i
)
s_m(i)
sm(i)是提及span i时的一元分数,
s
a
(
i
,
j
)
s_a(i, j)
sa(i,j)是提及span j时的两两分数。
通过将虚拟先行项 ϵ \epsilon ϵ的得分固定为0,如果任何非虚拟先行项的得分是正的,该模型预测最佳得分前项,如果所有非虚拟先行项的得分都是负的,则该模型弃权abstains。
这个模型的一个挑战性方面是,它的大小在文档长度中是O(T4)。
正如我们将在第5节中看到的那样,上面的分解能够根据提及分数
s
m
(
i
)
s_m(i)
sm(i)对不太可能属于一个共同引用集群的跨度进行积极修剪。
4.1 Scoring Architecture
我们提出了一个端到端的神经结构,它计算给定文档及其元数据的上述分数。
模型的核心是每个可能的跨度i的向量表示
g
i
g_i
gi,我们将在下一节中详细描述。
给定这些跨度表示,上面的评分函数是通过标准前馈神经网络计算的:
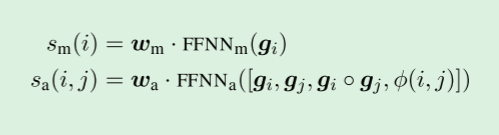
其中·表示点积,◦表示元素相乘,FFNN表示前馈神经网络feed-forward neural network,用于计算从输入向量到输出向量的非线性映射。
先行评分函数 s a ( i , j ) s_a(i,j) sa(i,j)包括每个跨域 g i ◦ g j g_i ◦ g_j gi◦gj的显式元素相似度,以及编码来自元数据的说话人和类型信息的特征向量φ(i,j)和两个跨域之间的距离。
4.2 Span Representations
两种类型的信息对准确预测共指联系至关重要:
提及范围内的语境和提及范围内的内部结构。 我们使用双向LSTM(Hochreiter and Schmidhuber,1997)来编码每个跨度的内部和外部的词汇信息。
我们还包括一个对每个跨度的词的注意机制来建模中心词。
我们假设每个单词 { x 1 , . . . , x T } \{x_1,...,x_T\} {x1,...,xT}的向量表示,它由固定的预训练单词嵌入和字符上的一维卷积神经网络(CNN)组成(详见7.1节)
为了计算每个跨度的向量表示,我们首先使用双向LSTM对上下文中的每个单词进行编码:

其中
δ
∈
{
−
1
,
1
}
δ∈\{-1,1\}
δ∈{−1,1}表示每个LSTM的方向性,而
x
t
∗
x^*_t
xt∗是双向LSTM的级联输出。
我们对每个句子都使用独立的LSTMs,因为跨句上下文在我们的实验中没有帮助。
句法中心通常作为功能包含在以前的系统中(Durrett and Klein,2013;Clark and Manning,2016b,a)。
我们的模型不依赖于句法分析,而是在每个跨度中使用注意力机制(Bahdanau et al.,2014)学习特定于任务的标题概念:
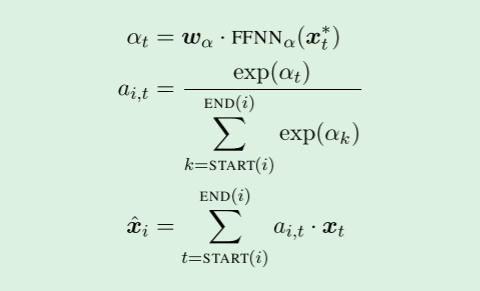
其中
x
^
i
\hat{x}_i
x^i是跨度i中单词向量的加权和。
权重
a
i
,
t
a_{i,t}
ai,t是自动学习的,与中心词的传统定义密切相关,我们将在9.2节中看到。
将上述span信息串联起来,以产生span I的最终表示形式
g
i
g_i
gi:
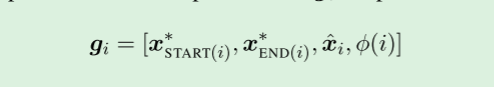
这推广了最近为question-answering提出的递归跨度表示(Lee et al.,2016),其中仅包括边界表示
x
S
t
a
r
t
(
i
)
∗
x^*_{Start(i)}
xStart(i)∗和
x
E
n
d
(
i
)
∗
x^*_{End(i)}
xEnd(i)∗。
我们引入了软头词向量
x
i
x_i
xi和编码跨度i大小的特征向量
φ
(
i
)
φ(i)
φ(i)。
5 Inference
在文档长度T中,整个模型的大小为O(T4)。
为了保持计算效率,我们在训练和评估过程中都贪婪地剪枝候选spans。
我们只考虑多达L个单词的跨度,并计算它们的一元提及分数
s
m
(
i
)
s_m(i)
sm(i)(如第4节所定义)。
为了进一步减少要考虑的跨度的数量,我们只保留最多
λ
T
λT
λT个mention分数最高的跨度,并且对每个跨度只考虑最多k个前因。
我们还用一个简单的抑制方案强制非交叉括号结构。We also enforce non-crossing bracketing structures with a simple suppression scheme.
我们接受按提及分数递减的跨度,除非在考虑跨度i时,存在一个先前接受的跨度j,这样START(i) < START(j) ≤ END(i) < END(j) ∨ START(j) < START(i) ≤ END(j) < END(i).。
尽管有这些积极的修剪策略,我们在实验中仍然保持了很高的Gold提及的召回率(当λ=0.4时超过92%)。
对于其余的提及,每个文档的前件的联合分布是在单个计算图上向前传递计算的。
最后的预测是由最可能的配置产生的聚类
6 Learning
在训练数据中,只观察到聚类信息。
由于前因变量是潜在的,我们优化gold聚类所隐含的所有正确前因变量的边际对数似然:
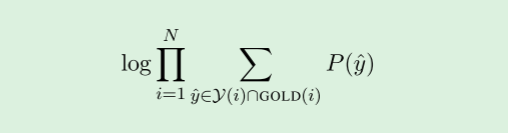
其中,GOLD(i)是包含span i的金簇中span的集合。
如果span i不属于一个金簇,或者所有的金前项都被修剪了,那么GOLD(i) = {
ϵ
\epsilon
ϵ}。
通过优化这一目标,模型自然地学会了准确地修剪跨度。
虽然最初的剪枝是完全随机的,但只有黄金提及才会收到积极的更新。
该模型可以快速利用这个学习信号对不同的因素进行适当的信用分配,例如用于修剪的提及分数
s
m
s_m
sm。
将虚拟先行项的得分固定为零,就提及检测而言,在整个模型中消除了一个虚假的自由度。
它还防止了跨度剪枝引入噪声。
例如,考虑这样一个情况,span i有一个经过修剪的gold先行词,因此GOLD (i) = {
ϵ
\epsilon
ϵ}。
学习目标只会正确地推低非黄金先行词的分数,而不会错误地推高假先行词的分数。
这个学习目标可以被认为是Durrett和Klein(2013)提出的学习目标的跨级、成本不敏感的类比。
我们试验了这些对成本敏感的替代品,包括基于利润率的变体(Wiseman et al., 2015;Clark和Manning, 2016a),但一个简单的最大可能性目标被证明是最有效的。
7 Experiments
我们在实验中使用了来自CoNLL-2012共享任务(Pradhan et al., 2012)的英语共指消解数据。
这个数据集包含2802个训练文档、343个development文档和348个测试文档。
训练文件平均454字,不超过4009字。
7.1 Hyperparameters
Word representations
单词嵌入是300维GloVe嵌入(Pennington et al., 2014)和Turian et al.(2010)的50维嵌入的固定拼接,两者都归一化为单位向量。
词汇表外的单词由一个0向量表示。
在字符CNN中,字符被表示为学习过的8维嵌入。
卷积的窗口大小为3、4和5个字符,每个字符由50个过滤器组成
Hidden dimensions
LSTMs中的隐藏状态有200维。
每个前馈神经网络由两个150维的隐藏层和修正的线性单元组成(Nair and Hinton, 2010)。
Feature encoding
我们将说话人的信息编码为二进制特征,以表明一对spans是否来自同一说话人。
在Clark和Manning (2016b)之后,距离特征被归类为以下几类[1、2、3、4、5-7、8-15、16-31、32-63、64+]。
所有特征(说话人、类型、跨度距离、提及宽度)都表示为习得的20维嵌入。
Pruning
我们对跨度进行修剪,使最大跨度宽度L = 10,每个单词的跨度数λ = 0.4,前因式的最大数量K = 250。
在训练期间,文档被随机截短到50个句子。
Learning
我们使用ADAM (Kingma and Ba, 2014)进行1个小批量的学习。
如Saxe等人(2013)所述,LSTM权值由随机标准正交矩阵初始化。
我们将0.5 dropout应用于单词嵌入和字符CNN输出。
我们对所有隐藏层和特征嵌入应用0.2 dropout。
如Gal和Ghahramani(2016)所述,Dropout masks跨时间步共享,以保存远程信息。
学习速率每100步下降0.1%。
该模型可训练150个epoch,并根据development 集提前停止。
所有代码都是在TensorFlow中实现的(Abadi et al., 2015),并且是公开的。
7.2 Ensembling
我们还报告了集成实验使用五个模型训练与不同的随机初始化。
对跨度剪枝和先行决策都进行了集成。
在测试时,我们首先对每个模型的提及分数
s
m
(
i
)
s_m(i)
sm(i)进行平均,然后对跨度进行修剪。
给定相同的剪枝跨度,每个模型然后分别计算前因得分
s
a
(
i
,
j
)
s_a(i, j)
sa(i,j),并对它们进行平均以产生最终得分。
8 Results
我们使用官方的CoNLL-2012评估脚本报告了标准MUC、B3和CEAFφ4指标的精度、召回率和F1值。
主要的评价是三个指标的平均F1。
8.1 Coreference Results
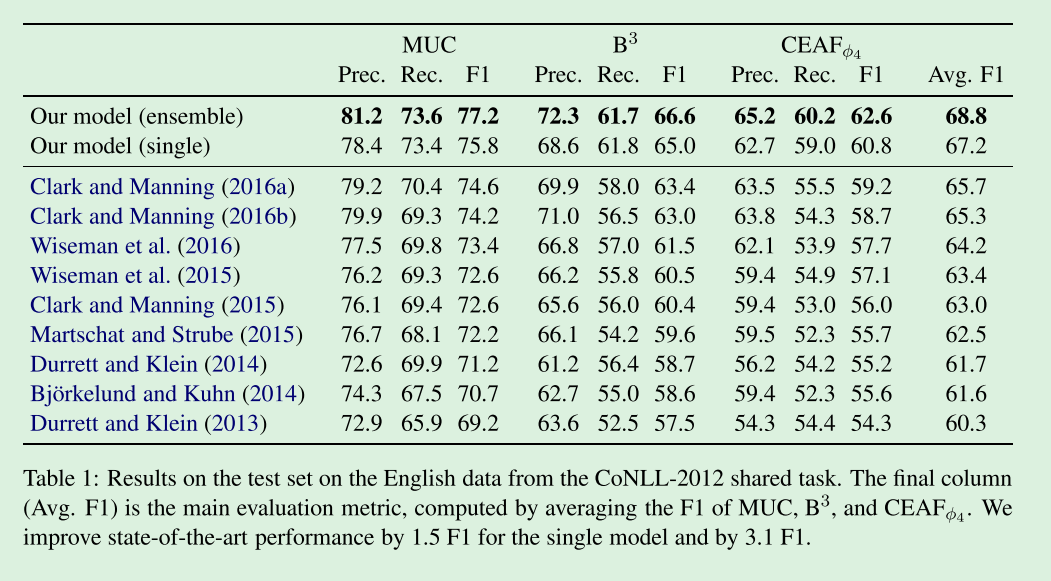
表1将我们的模型与过去几年在OntoNotes基准测试中推动了重大改进的几个以前的系统进行了比较。
我们在所有指标上都优于之前的系统。
特别是,我们的单模型将最先进的平均F1提高了1.5倍,而我们的5模型集合将其提高了3.1倍。
最显著的收益来自于召回的改进,这可能是由于我们的端到端设置。
在训练过程中,pipelined系统通常会丢弃任何提及检测器遗漏的提及,Clark和Manning (2016a)的提及量占训练数据中标注提及量的9%以上。
相反,我们只丢弃超过最大提及宽度10的提及,这在训练提及中所占比例不到2%。
联合提及评分的作用将在第8.3节中进一步讨论。
8.2 Ablations
为了显示我们提出的模型中每个组件的重要性,我们消融了体系结构的各个部分,并报告数据开发集上的平均F1(参见图2)。【应该是表2】
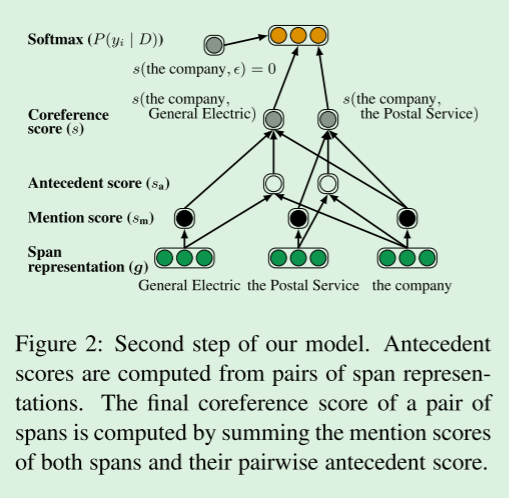
我们模型的第二步。 先行分数是从成对的跨度表示中计算出来的。 一对跨的最终共指得分是通过将两个跨的提及得分和它们的两两先行得分相加来计算的。
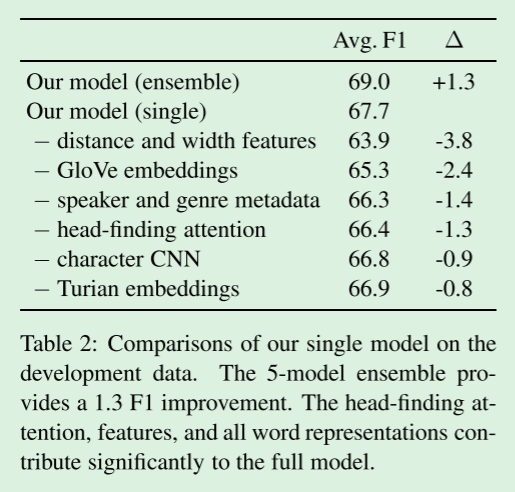
比较了我们的单个模型对开发数据的影响。
5个模型的集成提供了1.3F1的改进。
寻找头部的注意力、特征和所有词的表征对整个模型有很大的贡献。
Features
跨度之间的距离和跨度的宽度是共指消解的关键信号,这与其他共指模型的研究结果一致。
他们为最终结果贡献了3.8F1。
Word representations
因为我们的单词嵌入是固定的,所以使用各种单词嵌入可以在不过度拟合的情况下实现更有表现力的模型。
我们假设GloVe和Turian embedding的不同学习目标提供了正交信息(前者是词序不敏感的,而后者是词序敏感的)。
这两种嵌入都有助于F1开发中的一些改进。
字符CNN提供了形态学信息和一种退避词汇表外单词的方法。
由于共指决策通常涉及罕见的命名实体,我们看到字符级建模的贡献为0.9F1。
Metadata
发言者和体裁指标很多不能在下游应用程序中应用。
我们发现,如果没有它们,性能将下降1.4 F1,但仍然与假设访问该元数据的先前最先进的系统相当。
Head-finding attention
消融还显示,在没有寻找特定任务头的注意机制的情况下,性能下降1.3 F1。
正如我们将在9.4节中看到的,注意机制不应该被看作是简单的语法头的近似。
在许多情况下,注意多个词是有益的,这些词对共同引用特别有用,但传统上不被认为是句法头。
8.3 Comparing Span Pruning Strategies
为了区分改进的提及评分和改进的共指决策的贡献,我们将我们的模型的结果与交替的跨度剪枝策略进行了比较。
在这些实验中,我们使用交替跨度来进行训练和评估。
如表3所示,将基于规则的系统检测到的提及候选项保留在预测的解析树之上(Raghunathan et al.,2010),会使性能降低1 F1。
我们还提供了oracle实验结果,其中我们准确地保留了gold共指簇中存在的提及。
对于oracle的提及,我们看到17.5 F1的改进,这表明如果我们的模型能够产生更好的提及分数和照应决策,那么还有巨大的改进空间。
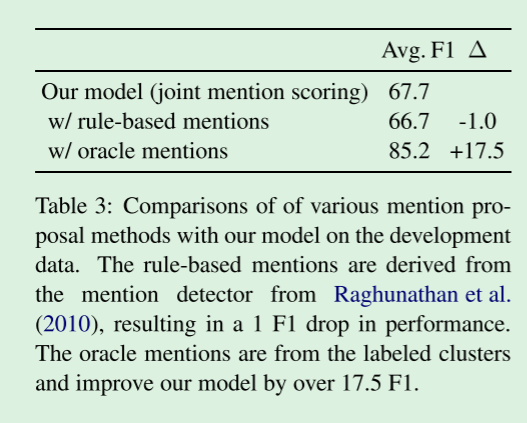
在开发数据上比较了各种提及建议方法与我们的模型。 基于规则的提及来源于Raghunathan等人的提及检测器。 (2010年),导致1 F1的表现下降。 Oracle提到的内容来自标记的集群,并将我们的模型改进了17.5F1以上。
9 Analysis
为了突出我们模型的优点和缺点,我们提供了定量和定性分析。
在下面的讨论中,我们使用单个模型的预测,而不是集合模型。
9.1 Mention Recall
训练数据只为对应于实体提及的跨度提供微弱信号,因为单例集群没有显式标记。
作为优化边际似然的副产品,我们的模型通过第4节中的一元提及分数自动学习有用的跨度排序。
根据提及得分,顶部跨度覆盖了Gold集群中的大部分提及,如图3所示。
如果保留了类似数量的跨度,我们的召回率可以与基于规则的提及检测器(Raghunathan et al.,2010)相媲美,该检测器每个单词产生0.26个跨度,召回率为89.2%。
当我们增加每个单词的跨度数(λ,在第5节)时,我们观察到更高的召回率,但回报递减。
在我们的实验中,每个单词保持0.4个跨度,在开发数据中的召回率为92.7%。
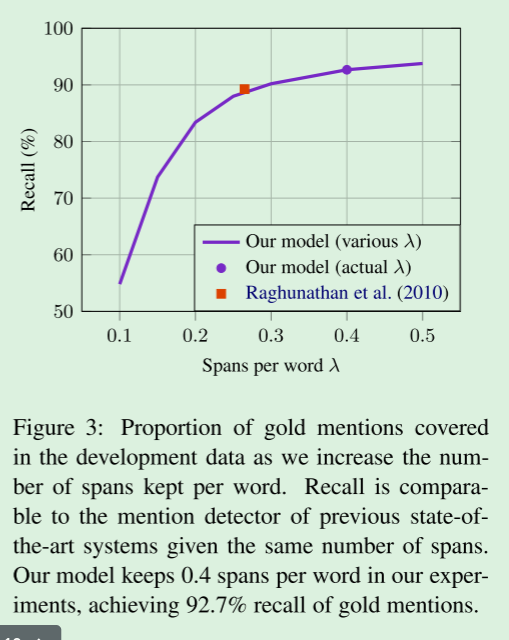
随着我们增加每个字保留的跨度数,开发数据中所涵盖的黄金提及的比例。
在给定相同的跨度数的情况下,召回可以与以前最先进系统的提及检测器相媲美。
在我们的实验中,我们的模型保持了每个单词0.4个跨度,实现了92.7%的黄金提及召回。
9.2 Mention Precision
虽然训练数据没有提供提及精确度的直接度量,但我们可以使用数据中提供的黄金语法结构作为代理。提及分数高的跨度应对应于句法成分。
在图4中,我们显示了在每个单词保持0.4跨度的情况下,得分跨度的精度。
对于2-5个词的跨度,75% - 90%的预测是constituents,这表明绝大多数的提及在语法上是可信的。
更长的跨度相对来说比较少见,但事实证明,对于该模型来说,难度更大,当跨度为10个单词时,精度下降到46%。
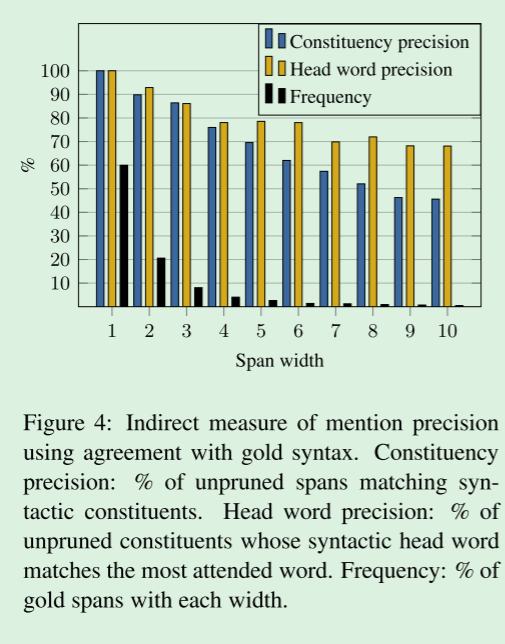
使用与Gold语法一致的提及精度的间接度量。
选区精度:匹配语法成分的未修剪跨的%。
中心词精确度:其句法中心词与最受关注的词匹配的未修剪成分的%。
频率:每个宽度的黄金跨度的%。
9.3 Head Agreement
我们还研究了习得的中心语偏好与句法中心语的相关性。
对于与黄金成分相对应的development数据中的每一个得分最高的跨度,我们计算具有最高关注权重的单词。
我们在图4中列出了与句法头匹配的这些单词的比例。
一致性在68-93%之间,这是惊人的高,因为没有明确的监督句法heads提供。
该模型简单地从聚类数据中学习这些中心词对做出共指决策是有用的。
9.4 Qualitative Analysis
我们在表4中的定性分析突出了我们模型的优点和缺点。
每一行都是模型预测的单个共参考集群的可视化。
括号中粗体的跨度属于预测的聚类,单词的红度根据第4节的寻头注意机制(
a
i
,
t
a_{i,t}
ai,t)表示其权重。

从开发数据预测实例。
每一行描述了由我们的模型预测的单个共指聚类。
粗体、带括号的跨度表示预测集群中的提及。
每个词的红色表示找头注意机制的权重(第4节中的ai,t)。
Strengths
在例子1中可以看到作出共指决策的注意机制的有效性。
该模型以孟加拉服装厂的火灾为例,成功地预测了火灾与火灾的共指联系。
对于上述提到的一个子跨度,孟加拉的一家服装厂,该模型最关注的是工厂,从而成功地预测了与the four-story building的共指联系。
注意机制的任务特殊性也在例4中得到说明。
该模型通常更多地关注协调器而不是协调的内容,因为协调器,如AND,为多样性plurality提供了强烈的提示。
该模型能够检测相对较长和复杂的名词短语,例如例2中意大利中部亚得里亚海沿岸的一个地区。
它还适当地注意到了区域,表明注意机制提供的不仅仅是内容词分类。
双向LSTM提供的上下文编码对于作出有信息的中心词决策至关重要。
Weaknesses
使用神经模型进行共指消解的一个好处是它们能够使用单词嵌入来捕捉单词之间的相似性,这是许多传统的基于特征的模型所缺乏的。
正如例1所示,虽然这可以显著提高recall,但当模型将释义与相关性或相似性合并时,它也容易预测假false positive links。
在示例3中,模型错误地预测了空乘人员和飞行员之间的联系。
预测的头部词乘务员和飞行员可能有附近的词嵌入,这是一个信号使用–而且经常被过度使用–模型。
例4也犯了同样类型的错误,模型预测查尔斯王子和他的新婚妻子卡米拉以及查尔斯和戴安娜之间存在共指联系,这两个非共指的提及在许多方面都很相似。
这些错误表明,在能够清晰区分等价、蕴涵和交替的词或跨度表示方面有很大的改进空间。
不出所料,我们的模型在做出需要世界知识的共指决策的艰苦战斗中几乎没有什么作用。
在示例5中,模型错误地决定它们(在让救援者定位它们的上下文中)与某些船只是一致的,可能是由于多个线索。
然而,一个使用常识推理的理想模型反而会正确地推断,救援者更有可能寻找落水者,而不是他从船上坠落的人。
这种类型的推理要么需要
(1)将外部知识来源与更复杂的推理相结合的模型,
要么需要(2)一个大得多的训练数据语料库来克服这些模式的稀疏性。
10 Conclusion
我们首次提出了端到端训练的最先进的共指消解模型。
我们最终的模型集成将OntoNotes基准测试的性能提高了3个F1以上,而没有使用以前系统使用的外部预处理工具。
我们表明,我们的模型隐式学习从所有可能跨度的空间生成有用的提及候选人。
一种新的头词发现注意机制也学习了对头词的任务特异性偏好,这与传统的头词定义密切相关。
虽然我们的模型在很大程度上推动了最先进的性能,但这些改进可能是对提高共参照分辨率的各种策略的大量工作的补充,包括实体级推理和整合世界知识,这是未来工作的重要途径。


![心法利器[84] | 最近面试小结](https://img-blog.csdnimg.cn/img_convert/90a5f9e6bbc1e3a556ef065f1394a837.png)