有这么一个情况,我在docker中,安装了镜像,也启动了容器,容器有:nginx、mysql、redis、php
是一个基本的开发环境
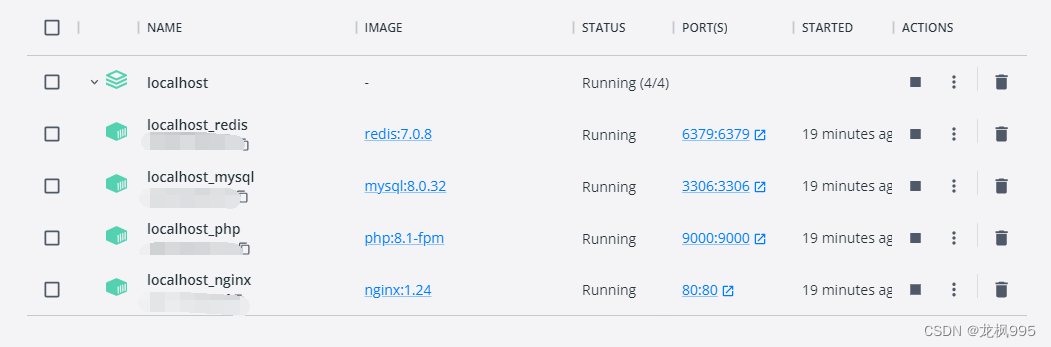
容器启动成功,我们先连接一下,看看是否正常。
先保证这些都ok,我们再继续
mysql 使用Navicat Premium 连接成功!

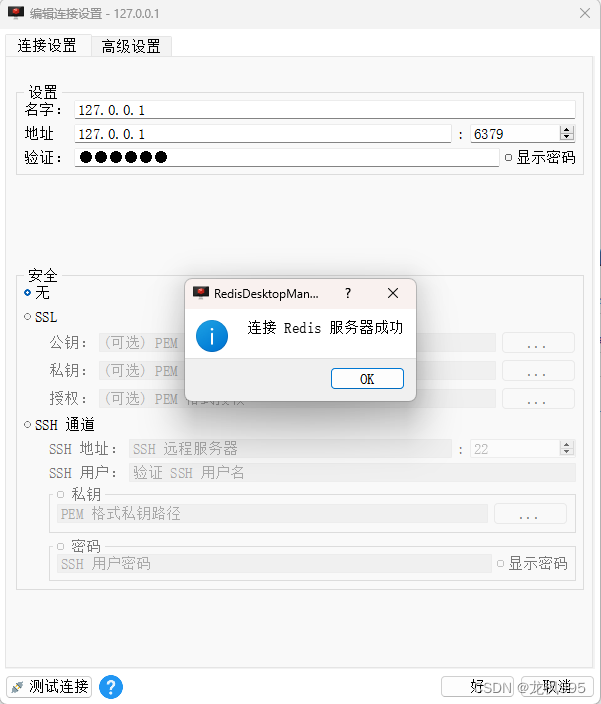
redis 使用Redis Desktop Manager 连接成功!
网页访问localhost,index.php 设置为入口文件,代码就这样:
<?php
echo phpinfo();页面上显示出了php相关的信息
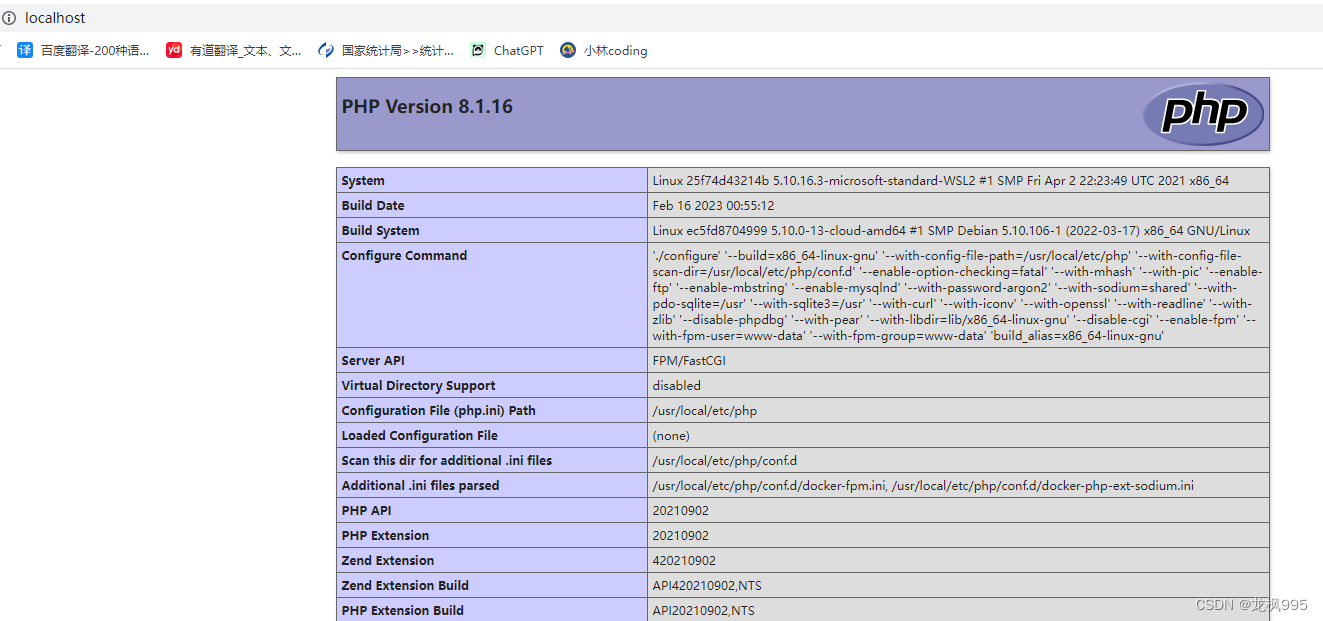
那么到这里,我们就能确定,容器中的各项服务,都是正常运行的。
正题!
有这么一个问题啊,就是这个phpinfo 信息里,我们搜索redis,会发现并没有这个扩展,就会导致,php无法使用redis
所以,本期我们主要是做,如何在docker中安装php redis扩展
1. 先进入php容器
docker exec -it 容器ID bash如果是windows环境,会提示:
the input device is not a TTY. If you are using mintty, try prefixing the command with 'winpty'我们只需要在前面加一个"winpty"即可:
winpty docker exec -it 容器ID bash先看一下php扩展:
php -m
里面确实是没有redis的
2. 下载php redis扩展
wget https://pecl.php.net/get/redis-5.3.7.tgz请注意,我这里下载的是 redis5.3.7,具体版本看实际情况
另外,我是将此文件,安装在 /tmp 目录里的,作为一个临时文件
3. 解压redis-5.3.7
先创建一个目录
mkdir redis然后进行解压:
tar -zxvf redis-5.3.7.tgz -C redis就将压缩包里的东西,都解压到了同目录下的redis目录里
我们可以输入 ls 看一下
ls
进入 redis 看一下
#先进入redis目录
cd redis
#查看
ls 
能看到,redis-5.3.7就是我们解压好的
4. 执行phpize
先进入 redis-5.3.7目录
#查看当前位置
pwd![]()
确定我们在这个目录位置,然后执行下面的命令:
/usr/local/bin/phpize
5. 指定php配置路径
先找到php-config 文件位置:
whereis php-config![]()
然后执行:
./configure --with-php-config=/usr/local/bin/php-config最后出现这些就代表成功
creating libtool
appending configuration tag "CXX" to libtool
configure: patching config.h.in
configure: creating ./config.status
config.status: creating config.h6. 编译安装
运行命令:
make出现下面这样代表成功
If you ever happen to want to link against installed libraries
in a given directory, LIBDIR, you must either use libtool, and
specify the full pathname of the library, or use the `-LLIBDIR'
flag during linking and do at least one of the following:
- add LIBDIR to the `LD_LIBRARY_PATH' environment variable
during execution
- add LIBDIR to the `LD_RUN_PATH' environment variable
during linking
- use the `-Wl,--rpath -Wl,LIBDIR' linker flag
- have your system administrator add LIBDIR to `/etc/ld.so.conf'
See any operating system documentation about shared libraries for
more information, such as the ld(1) and ld.so(8) manual pages.
----------------------------------------------------------------------
Build complete.
Don't forget to run 'make test'.
再运行命令:
make install出现下面这样代表成功:
Installing shared extensions: /usr/local/lib/php/extensions/no-debug-non-zts-20210902/7. php添加redis扩展
找到php配置文件
cd /usr/local/etc/php/conf.d这里会看到 docker-php-ext-sodium.ini 直接进行编辑
vim docker-php-ext-sodium.ini在下方加入 redis扩展:
extension=/usr/local/lib/php/extensions/no-debug-non-zts-20210902/redis.so8. 再查看扩展
php -m 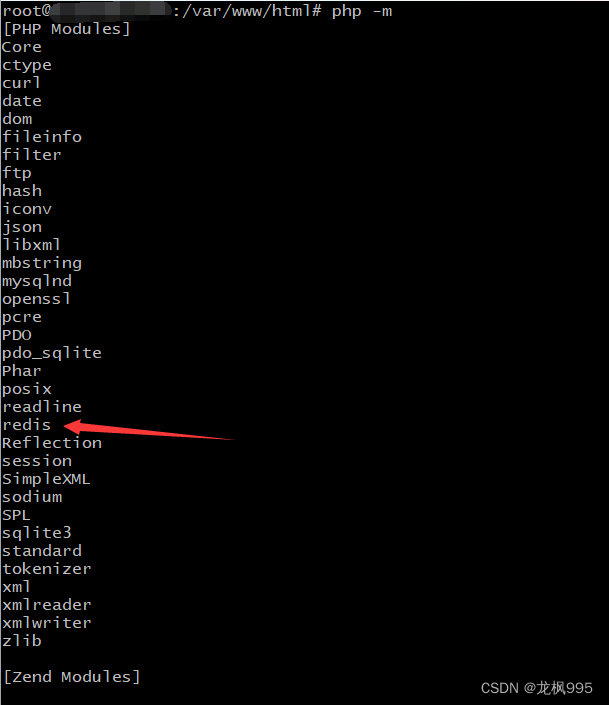
9. 重启容器
重启php容器后,我们再访问localhost看一下phpinfo里的信息
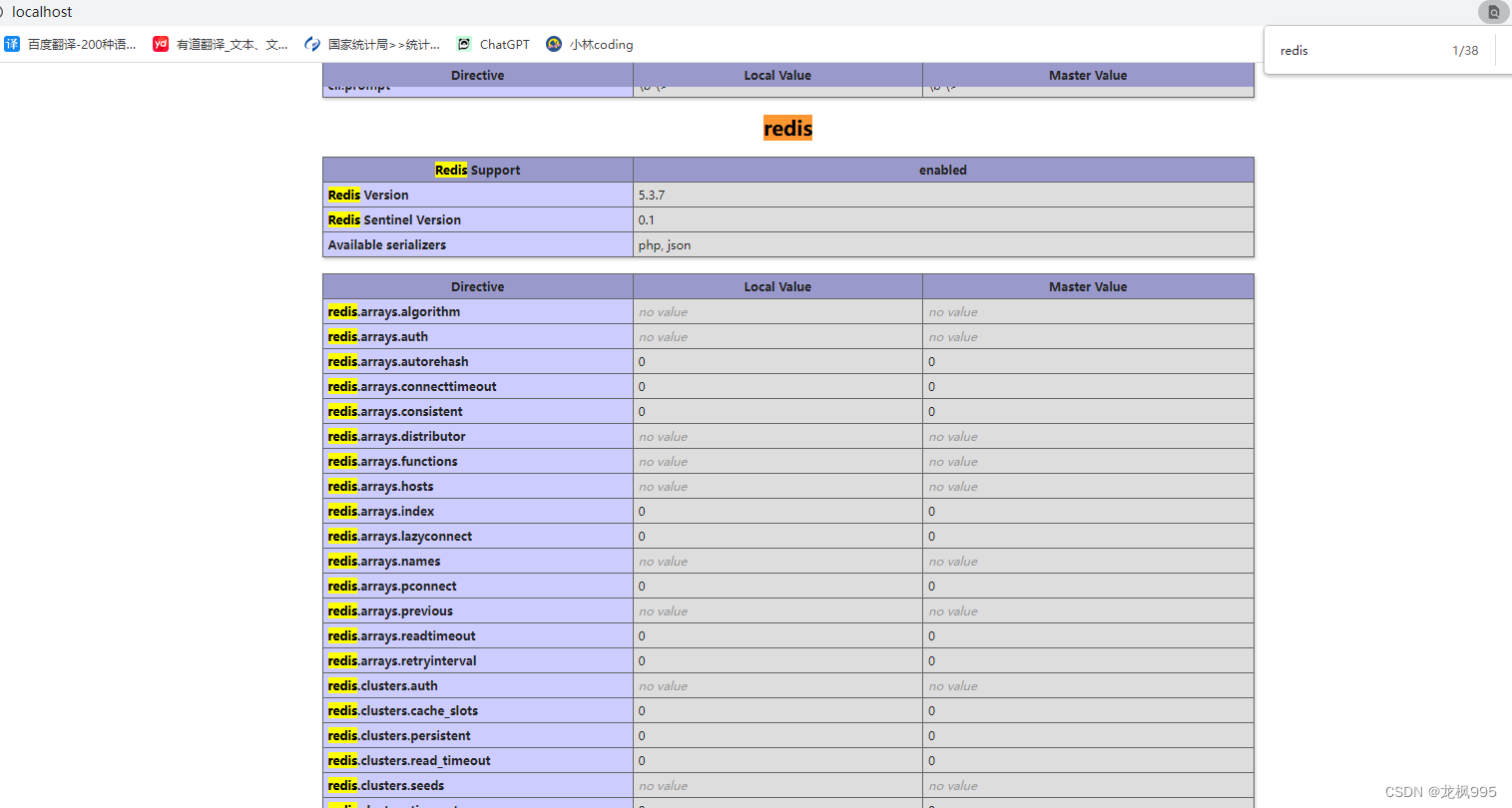
搜索redis 能看到已经有这个扩展了
本期分享结束,喜欢的点个赞吧~