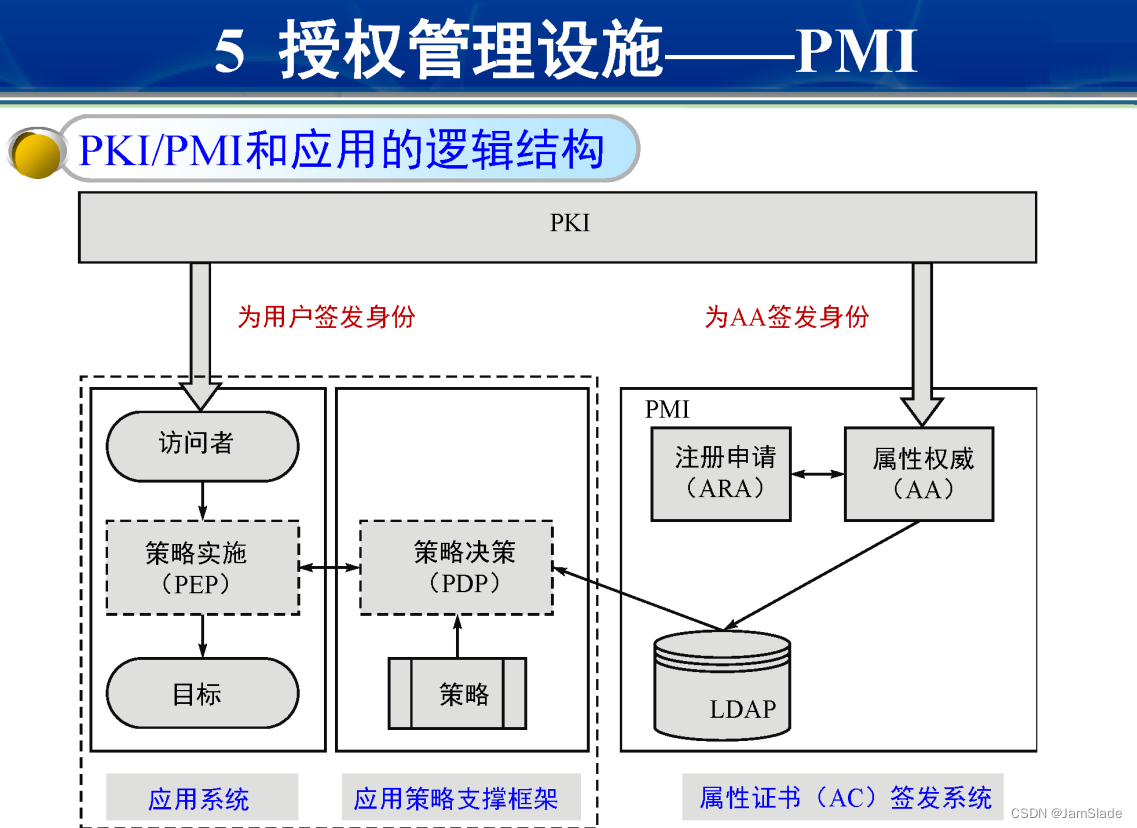
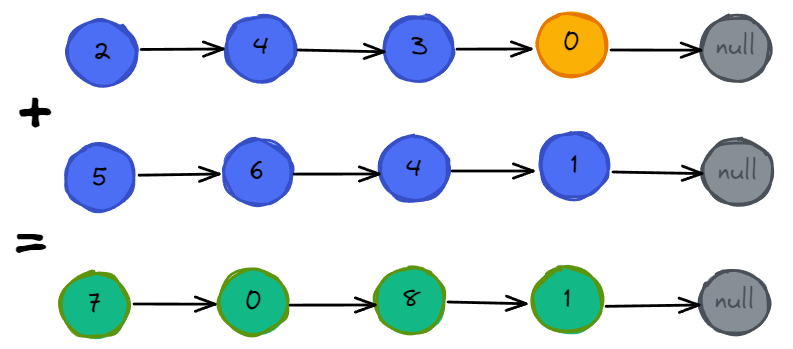
晶振在电路板中随处可见,只要用到处理器的地方就必定有晶振的存在,即使没有外部晶振,芯片内部也有晶振。
晶振概述
晶振一般指晶体振荡器。晶体振荡器是指从一块石英晶体上按一定方位角切下薄片(简称为晶片),石英晶体谐振器,简称为石英晶体或晶体、晶振。

而在封装内部添加IC组成振荡电路的晶体元件称为晶体振荡器。其产品一般用金属外壳封装,也有用玻璃壳、陶瓷或塑料封装的。
晶振的工作原理
石英晶体振荡器是利用石英晶体的压电效应制成的一种谐振器件,它的基本构成大致是:从一块石英晶体上按一定方位角切下薄片,在它的两个对应面上涂敷银层作为电极,在每个电极上各焊一根引线接到管脚上,再加上封装外壳就构成了石英晶体谐振器,简称为石英晶体或晶体、晶振。其产品一般用金属外壳封装,也有用玻璃壳、陶瓷或塑料封装的。若在石英晶体的两个电极上加一电场,晶片就会产生机械变形。反之,若在晶片的两侧施加机械压力,则在晶片相应的方向上将产生电场,这种物理现象称为压电效应。
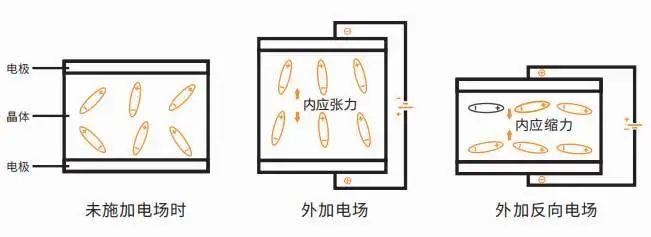
如果在晶片的两极上加交变电压,晶片就会产生机械振动,同时晶片的机械振动又会产生交变电场。
在一般情况下,晶片机械振动的振幅和交变电场的振幅非常微小,但当外加交变电压的频率为某一特定值时,振幅明显加大,比其他频率下的振幅大得多,这种现象称为压电谐振,它与LC回路的谐振现象十分相似。它的谐振频率与晶片的切割方式、几何形状、尺寸等有关。

当晶体不振动时,可把它看成一个平板电容器称为静电电容C,它的大小与晶片的几何尺寸、电极面积有关,一般约几个皮法到几十皮法。当晶体振荡时,机械振动的惯性可用电感L来等效。一般L的值为几十豪亨到几百豪亨。晶片的弹性可用电容C来等效,C的值很小,一般只有0.0002~0.1皮法。晶片振动时因摩擦而造成的损耗用R来等效,它的数值约为100欧。

由于晶片的等效电感很大,而C很小,R也小,因此回路的品质因数Q很大,可达1000~10000。加上晶片本身的谐振频率基本上只与晶片的切割方式、几何形状、尺寸有关,而且可以做得精确,因此利用石英谐振器组成的振荡电路可获得很高的频率稳定度。
计算机都有个计时电路,尽管一般使用“时钟”这个词来表示这些设备,但它们实际上并不是通常意义的时钟,把它们称为计时器可能更恰当一点。

计算机的计时器通常是一个精密加工过的石英晶体,石英晶体在其张力限度内以一定的频率振荡,这种频率取决于晶体本身如何切割及其受到张力的大小。有两个寄存器与每个石英晶体相关联,一个计数器和一个保持寄存器。
石英晶体的每次振荡使计数器减1。当计数器减为0时,产生一个中断,计数器从保持寄存器中重新装入初始值。这种方法使得对一个计时器进行编程,令其每秒产生60次中断(或者以任何其它希望的频率产生中断)成为可能。每次中断称为一个时钟嘀嗒。

晶振在电气上可以等效成一个电容和一个电阻并联再串联一个电容的二端网络,电工学上这个网络有两个谐振点,以频率的高低分其中较低的频率为串联谐振,较高的频率为并联谐振。
由于晶体自身的特性致使这两个频率的距离相当的接近,在这个极窄的频率范围内,晶振等效为一个电感,所以只要晶振的两端并联上合适的电容它就会组成并联谐振电路。
这个并联谐振电路加到一个负反馈电路中就可以构成正弦波振荡电路,由于晶振等效为电感的频率范围很窄,所以即使其他元件的参数变化很大,这个振荡器的频率也不会有很大的变化。

晶振有一个重要的参数,那就是负载电容值,选择与负载电容值相等的并联电容,就可以得到晶振标称的谐振频率。
一般的晶振振荡电路都是在一个反相放大器的两端接入晶振,再有两个电容分别接到晶振的两端,每个电容的另一端再接到地,这两个电容串联的容量值就应该等于负载电容,请注意一般IC的引脚都有等效输入电容,这个不能忽略。
一般的晶振的负载电容为15皮或12.5皮,如果再考虑元件引脚的等效输入电容,则两个22皮的电容构成晶振的振荡电路就是比较好的选择。
来源:电子电路
链接:晶振概述及工作原理 - RFASK射频问问
关于RFASK射频问问
射频问问是在"微波射频网”系列原创技术专栏基础上升级打造的技术问答学习平台,主要围绕射频芯片、微波电路、天线、雷达、卫星等相关技术领域,致力于为无线通信、微波射频、天线、雷达等行业的工程师,提供优质、原创的技术问答、专栏文章、射频课程等学习内容。更多请访问:RFASK射频问问 - 射频技术研发服务平台 | 技术问答、专栏文章、射频课程