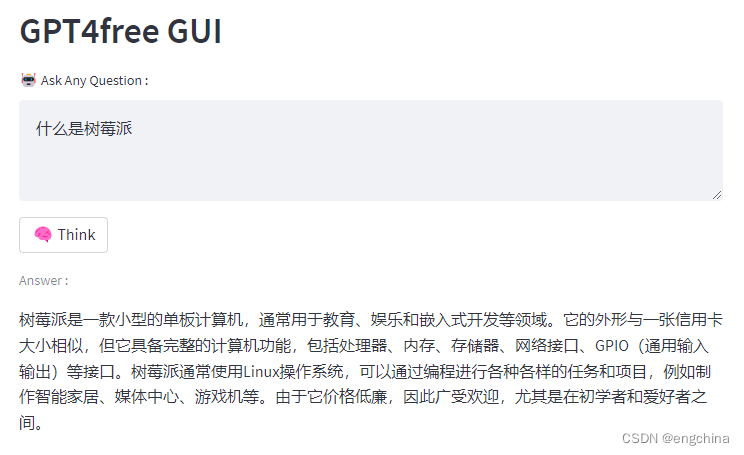
简介
在Cutlass 2.x之前将matix或者tensor切分成固定尺寸的操作都是在tile iterator当中(Cutlass 3.0之后对于matrix和tensor的操作都放到了cute::Tensor里面)。tile_iterator_concept不同于c++20里面的concept,这里不使用concept作为key word,仅仅是对这些类型的需求。tile_iterator内部是几个概念的组合,tile iterator concept几乎涵盖了所有需求。
Concept定义
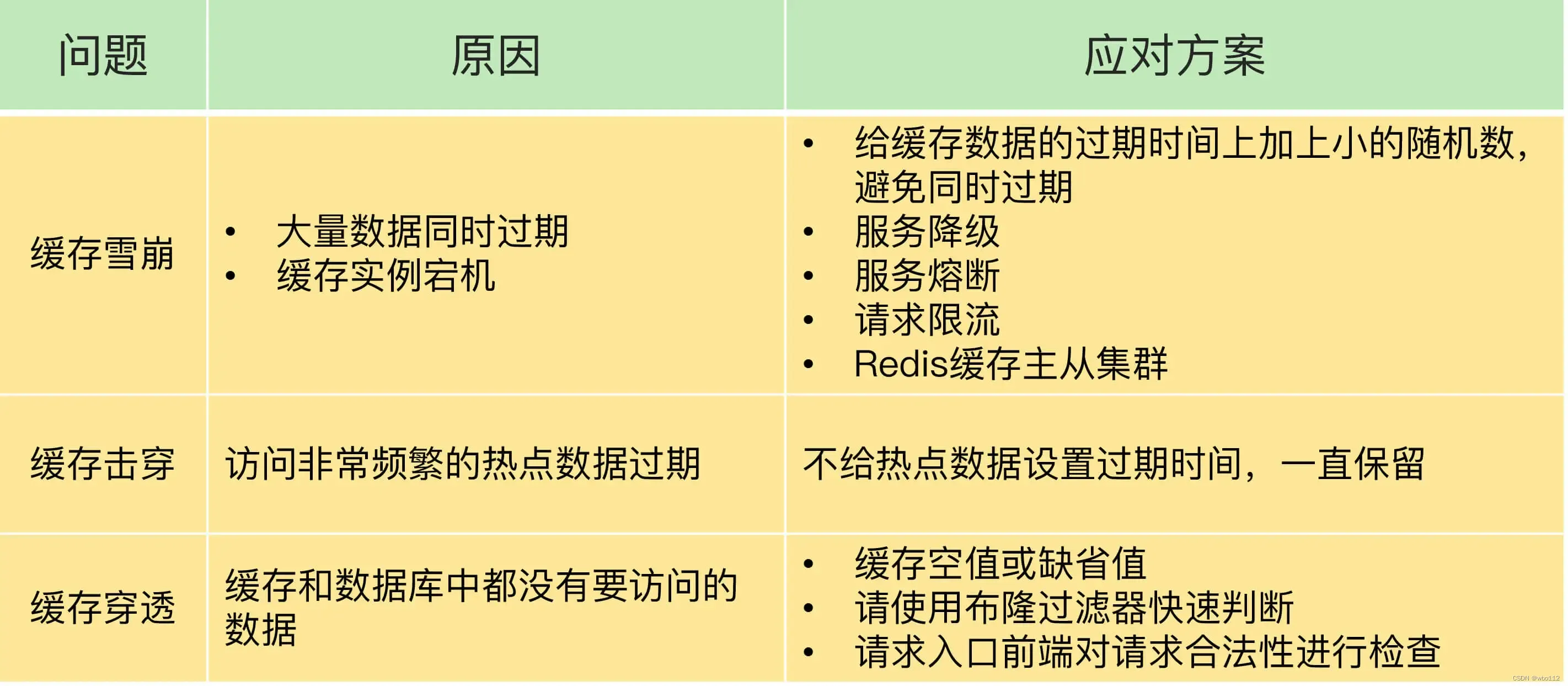
| struct | 定义 |
|---|---|
| TileIteratorConcept | 基类:1. Element,tile的组成部分;2. 形状类型,取决于iter的实现 |
| ContiguousMemoryTileIterator | 在连续内存上任意Tile的iterator,每个thread将Element尺寸的数据块存储在pointer_offset的位置上 |
| ReadableTileIteratorConcept(WriteableTileIteratorConcept类似) | 每个thread从内存读取一块数据放到其相应的Fragment当中 |
| ReadableContiguousTileIteratorConcept(WriteableContiguousTileIteratorConcept类似) | 从pointer_offset的位置连续读取数据 |
| ForwardTileIteratorConcept | 前向遍历tile,具体的方向和Context相关,比如Gemm就这沿着K方向遍历 |
| BidirectionalTileIteratorConcept | 两个方向遍历tile |
| RandomAccessTileIteratorConcept | 相较TensorRef进行TensorCoord的偏移 |
| ReadableRandomAccessTileIteratorConcept(WriteableRandomAccessTileIteratorConcept类似) | 根据TensorRef和TensorCoord load数据到fragment中 |
| ReadableRandomAccessContiguousTileIteratorConcept(WriteableRandomAccessContiguousTileIteratorConcept类似) | 根据TensorRef和TensorCoord load pointer_offset处数据到fragment中 |
| MaskedTileIteratorConcept | 为了部分获取数据设置的mask,可以作为oob保护 |
| WriteableReadableForwardContiguousTileIteratorConcept | ForwardTileIteratorConcept + ReadableContiguousTileIteratorConcept + WriteableContiguousTileIteratorConcept |
| WriteableReadableRandomAccessContiguousTileIteratorConcept | ReadableRandomAccessContiguousTileIteratorConcept + WriteableRandomAccessContiguousTileIteratorConcept |