1 场景介绍
大数据量的查询问题
假设我们要从商品的表里面查询一个商品

我们的数据库里面肯定有个t_goods的表,我们现在利用商品的名称做模糊查询
1.1 对于数据库的查询的
select * from t_goods where goodsName like “%手机%” ;问题:
- 这个查询速度快不快?
- 对于goodsName 是否添加了索引(假设我们添加了)
- 对于上面的sql 语句,是否会走索引?
索引的本质是一颗树,若我们使用(“%手机%” ) 查询时,它无法去比较大小,无法比较,就无法走索引!
那种场景走索引:最左匹配原则 goodsName like “手机%”,它会走索引。
goodsName like “%手机” 它不会走索引。
既然不会走索引,它的查询速度,就需要来一个全表的扫描。它的速度会非常慢!
假设我们的数据有百万级别的,查询一个商品,可能就需要20s 左右!
1.2 使用Map 集合来做查询
数据结构如下:Map<String,List<ID>>

我们在Map 集合的Key 放商品的关键字,value放商品的id的集合。
到时我们使用关键字查询商品的ids就可以了
1.3 怎么得到商品的关键字?
商品名称Eg:
【小米10 旗舰新品2月13日14点发布】小米10 骁龙865 5G 抢先预约抽壕礼
荣耀20S 李现同款 3200万人像超级夜景 4800万超广角AI三摄 麒麟810 全网通版
荣耀20i 3200万AI自拍 超广角三摄 全网通版6GB+64GB 渐变红 移动联通电信4G
Redmi 8A 5000mAh 骁龙八核处理器 AI人脸解锁 4GB+64GB 深海蓝 游戏老人手机
1.4 老师问你一个问题:请说出包含 明月的古诗?
明月几时有,把酒问青天(苏东坡《水调歌头》)
海上升明月,天涯共此时(张九龄《望月怀远》)
暗尘随马去,明月逐人来(苏昧道《正月十五夜》)
三五明月满,四五蟾兔缺(无名氏《孟冬寒气至》)
白云还自散,明月落谁家(李白《忆东山二首》)
明月却多情,随人处处行(张先《菩萨蛮》)
明月净松林,千峰同一色(欧阳修《自菩提步月归广化寺》)
明月几时有,把酒问青天(苏轼《水调歌头》)
明月出天山,茫茫人海间(李白《关山月》)
明月照高楼,流光正徘徊(曹植《怨歌行》)
明月隐高树,长河没晓天(陈子昂《春夜别友人》)
举杯邀明月,对影成三人(李白《月下独酌》)
举头望明月,低头思故乡(李白《静夜思》)
深林人不知,明月来相照(王维《竹里馆》)
明月松间照,清泉石上流(王维《山居秋暝》)
如果在使用数据库查询,你只能遍历你学过的每一首诗,看看里面有没有《明月》两个字
如果使用索引:
明月---List<以上所有>
白云---List<忆东山二首>
青天---List<水调歌头>
2 分词实现操作
新建一个maven项目
2.1 导入jieba分词依赖
<dependencies>
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
</dependencies>2.2 分词器测试
package com.example.demo;
import com.huaban.analysis.jieba.JiebaSegmenter;
import com.huaban.analysis.jieba.SegToken;
import java.util.List;
public class TestJieBa {
//声明一个分词对象
private static JiebaSegmenter jiebaSegmenter=new JiebaSegmenter();
public static void main(String[] args) {
String content="锤子(smartisan) 坚果Pro3 8GB+128GB 黑色 骁龙855PLUS 4800万四摄 全网通双卡双待 全面屏游戏手机";
/***
* @Description:
* 参数1 要分词的内容
* 参数1:分词模式
*/
List<SegToken> tokens = jiebaSegmenter.process(content, JiebaSegmenter.SegMode.SEARCH);
for (SegToken token : tokens) {
System.out.println(token.word);
}
System.out.println("分词完成"+tokens.size());
}
}
启动后结果如下:

分词器引入成功。
3 使用商品搜索案例来展示我们的Map集合
一下模拟商品查询的过程
3.1 商品实体类
package com.example.demo.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Goods {
private Integer id;//商品ID
private String goodsName;//商品名称
private Double goodsPrice;//商品价格
}
3.2 数据库工具类
这边只是模拟数据库,没有进行数据库的连接
package com.example.demo.util;
import com.example.demo.domain.Goods;
import java.util.*;
public class DBUtils {
private static Map<Integer, Goods> db=new HashMap<>();
public static void insert(Goods goods){
db.put(goods.getId(),goods);
}
public static Goods getById(Integer id){
return db.get(id);
}
/***
* @Description:
* @Param: 提供一个根据ids的集合查询商品的方法 key--->多个商品ID
* @return:
*/
public static List<Goods> getByIds(Set<Integer> ids){
if(null==ids||ids.isEmpty()){
return Collections.emptyList();
}
List<Goods> goods=new ArrayList<>();
for (Integer id : ids) {
Goods g = db.get(id);
if(null!=g){
goods.add(g);
}
}
return goods;
}
}
3.3 商品服务的接口GoodsService
package com.example.demo.service;
import com.example.demo.domain.Goods;
import java.util.List;
public interface GoodsService {
/**
* @Description: 添加商品
* @Param: [goods]
* @return: void
*/
void insert(Goods goods);
/**
* @Description: 根据商品名称模糊查询商品
* @Param: [goodsName]
* @return: java.util.List<com.leige.solr.test.domain.Goods>
*/
List<Goods> findByGoodsName(String goodsName);
}
3.4 商品服务的实现类(GoodsServiceImpl)
package com.example.demo.service.Impl;
import com.example.demo.domain.Goods;
import com.example.demo.service.GoodsService;
import com.example.demo.util.DBUtils;
import com.huaban.analysis.jieba.JiebaSegmenter;
import com.huaban.analysis.jieba.SegToken;
import java.util.*;
public class GoodsServiceImpl implements GoodsService {
//模拟一个索引库
private Map<String, Set<Integer>> indexs=new HashMap<>();
private JiebaSegmenter jiebaSegmenter=new JiebaSegmenter();
@Override
public void insert(Goods goods) {
/***
* 我们在插入商品时,要构造一个Map集合
* Map<String,List<ID>/>
*/
//分词
List<String> keywords= this.fenci(goods.getGoodsName());
//插入数据
DBUtils.insert(goods);
//保存到分词的关键字和ids的映射关系
saveKeyWords(keywords,goods.getId());
}
/**
* @Description: 保存分词和id的关系
* @Param: [keywords, id]
* @return: void
*/
private void saveKeyWords(List<String> keywords, Integer id) {
if(null!=keywords&&!keywords.isEmpty()){
for (String keyword : keywords) {
if(indexs.containsKey(keyword)){//先看关键字在索引里面是否存在
Set<Integer> integers = indexs.get(keyword);//得到这个关键字对应该的已存在的ids集合
integers.add(id);//把新插入的id放入
}else{//这是一个新词,之前的索引库不存在
HashSet<Integer> ids = new HashSet<>();
ids.add(id);
indexs.put(keyword,ids);
}
}
}
}
/***
* @Description: 完成分词
* @Param: [goodsName]
* @return: java.util.List<java.lang.String>
*/
private List<String> fenci(String goodsName) {
List<SegToken> tokens = jiebaSegmenter.process(goodsName, JiebaSegmenter.SegMode.SEARCH);
List<String> keywords=new ArrayList<>(tokens.size());
for (SegToken token : tokens) {
keywords.add(token.word);
}
return keywords;
}
/***
* @Description: 查询
* @Param: [goodsName]
* @return: java.util.List<com.leige.solr.test.domain.Goods>
*/
@Override
public List<Goods> findByGoodsName(String goodsName) {
//直接从Map里面取有没有
if(indexs.containsKey(goodsName)){
Set<Integer> ids = indexs.get(goodsName);//取出有goodsName里面有传过来的goodsName商品的ID
List<Goods> goodsList = DBUtils.getByIds(ids);
return goodsList;
}
return Collections.emptyList();
}
}
3.5 测试类
package com.example.demo;
import com.example.demo.domain.Goods;
import com.example.demo.service.GoodsService;
import com.example.demo.service.Impl.GoodsServiceImpl;
import java.util.List;
public class TestApp {
public static void main(String[] args) {
GoodsService goodsService = new GoodsServiceImpl();
Goods goods = new Goods(1,"苹果手机",10.00) ;
Goods goods1 = new Goods(2,"华为手机",11.00) ;
Goods goods2 = new Goods(3,"红米手机",5.00) ;
Goods goods3 = new Goods(4,"联想手机",6.00) ;
goodsService.insert(goods);
goodsService.insert(goods1);
goodsService.insert(goods2);
goodsService.insert(goods3);
List<Goods> goodss = goodsService.findByGoodsName("红米");
for (Goods goodsTest : goodss) {
System.out.println(goodsTest);
}
}
}
3.6 搜索结果如下
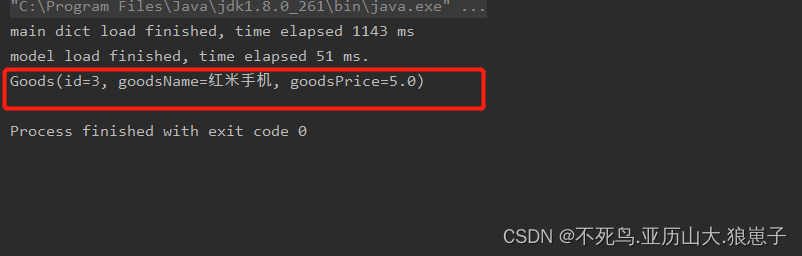
4 缺陷解决
以上代码我们会发现一个问题,我们在搜索红米手机或者其他手机的全名的时候,搜索不出来结果

原因:
分词器对查询的关键字进行分词的时候,对关键字进行了拆分,没有保留原来的完整关键字,
解决方案:
搜索的时候也进行分词
操作如下:
(1)修改GoodsService
/**
* @Description: 根据商品名称模糊查询商品
* @Param: [goodsName]
* @return: java.util.List<com.leige.solr.test.domain.Goods>
*/
List<Goods> findByKeyWord(String keyword);(2)修改GoosServiceImpl
@Override
public List<Goods> findByKeyWord(String keyword) {
//先分词 再查询
List<String> stringList = this.fenci(keyword);
Set<Integer> idsSet = new HashSet<>();
for (String kw : stringList) {
//直接从Map里面取有没有
if(indexs.containsKey(kw)){
Set<Integer> ids = indexs.get(kw);//取出有goodsName里面有传过来的goodsName商品的ID
idsSet.addAll(ids);
}
}
if(idsSet.isEmpty()){
return Collections.emptyList();
}else{
return DBUtils.getByIds(idsSet);
}
}(3)修改测试类
package com.example.demo;
import com.example.demo.domain.Goods;
import com.example.demo.service.GoodsService;
import com.example.demo.service.Impl.GoodsServiceImpl;
import java.util.List;
public class TestApp {
public static void main(String[] args) {
GoodsService goodsService = new GoodsServiceImpl();
Goods goods = new Goods(1,"苹果手机",10.00) ;
Goods goods1 = new Goods(2,"华为手机",11.00) ;
Goods goods2 = new Goods(3,"红米手机",5.00) ;
Goods goods3 = new Goods(4,"联想手机",6.00) ;
goodsService.insert(goods);
goodsService.insert(goods1);
goodsService.insert(goods2);
goodsService.insert(goods3);
List<Goods> goodss = goodsService.findByKeyWord("红米手机");
for (Goods goodsTest : goodss) {
System.out.println(goodsTest);
}
}
}
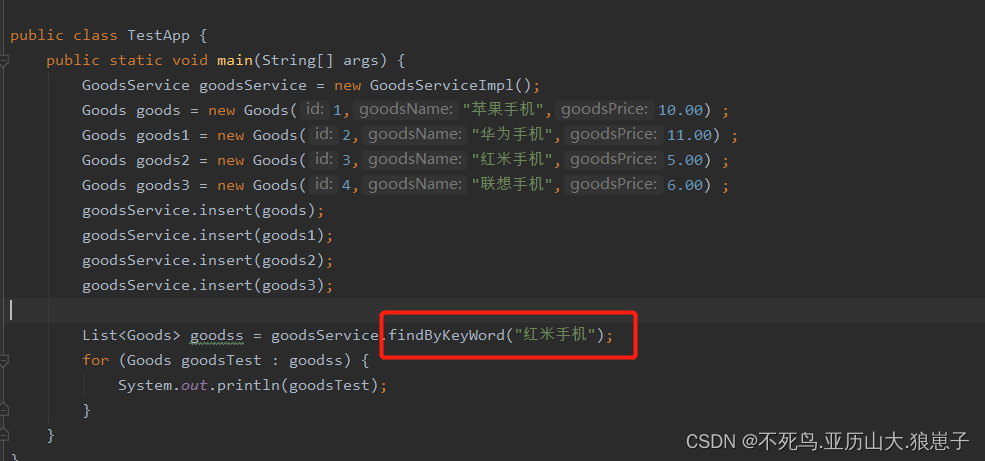
结果如下
3.7 对比直接查询
使用分词器之前:是需要把数据库做一个全表的扫描
使用分词器之后:直接通过计算hash值定位 值,在非常理想的情况下。他的速度,只计算一次
![[架构之路-187]-《软考-系统分析师》-5-数据库系统 - 操作型数据库OLTP与分析型数据库OLAP比较](https://img-blog.csdnimg.cn/img_convert/0bc6f03d7788b8326ff2d71a2f7aa492.png)


![[Gitops--10]微服务项目部署流水线编写](https://img-blog.csdnimg.cn/c45505142b8945f8890a0b3086d26ef7.png)